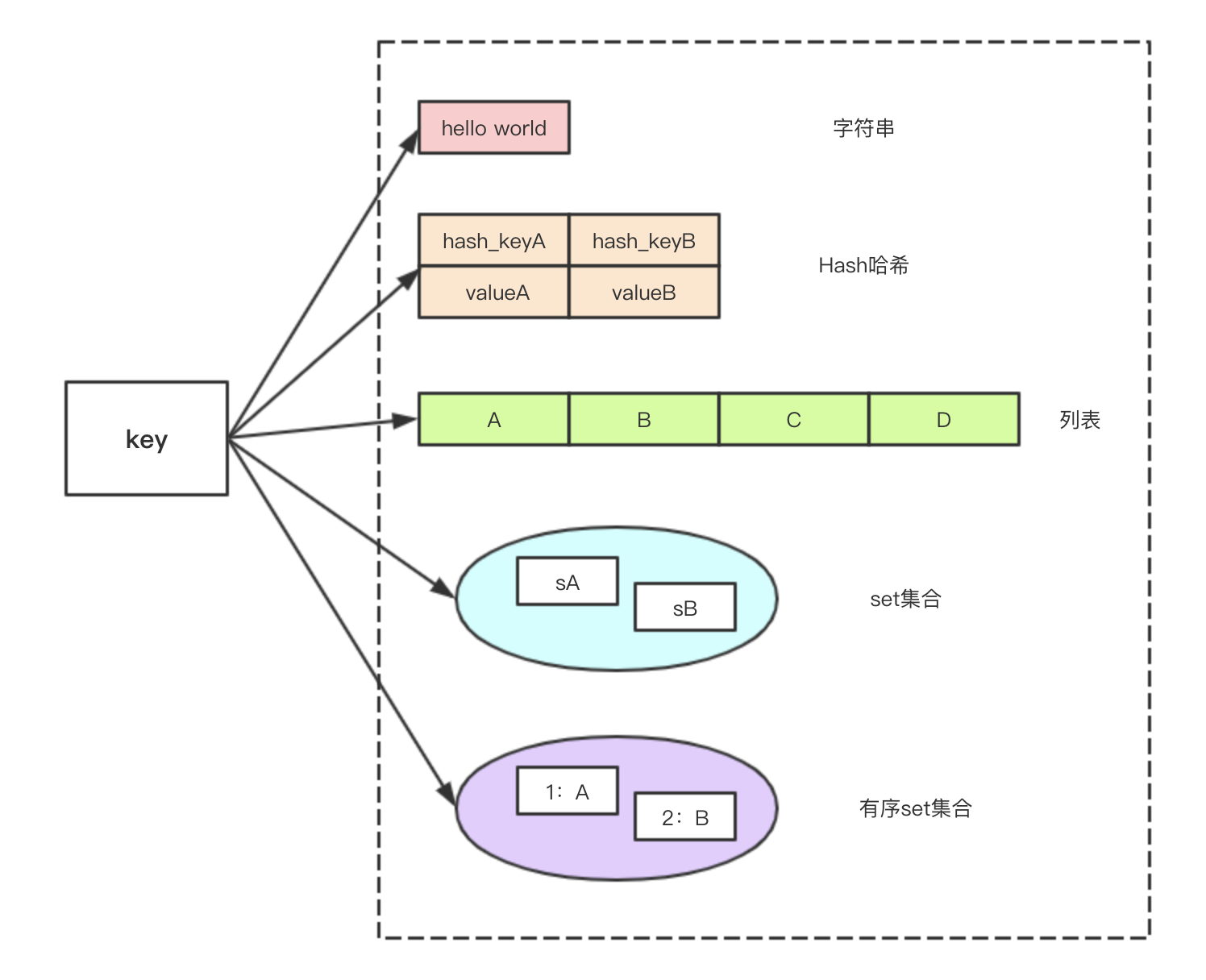
1.Redis支持的数据类型?
答:五种,在第一节redis相关的博客我就说过,String,Hash,List,Set,zSet,也就是我们的字符串,哈希,列表,集合,有序集合五种。结构图如下。
2.什么是Redis持久化?Redis有哪几种持久化方式?优缺点是什么?
答:Redis持久化主要分为三种,RDB、AOF还有我们的混合持久化,RDB是一个二进制文件,AOF是保存我们的每一次操作的命令,默认是使用RDB的持久化方式。RDB,二进制文件,速度快,但是数据安全性差,可能造成数据的丢失,AOF,命令文件,速度慢,数据安全性视配置文件而定,相对要更安全一些,数据不容易丢失,BGREWRITEAOF重写可以压缩我们已有的AOF文件,混合持久化模式就是以RDB和AOF共同使用的。
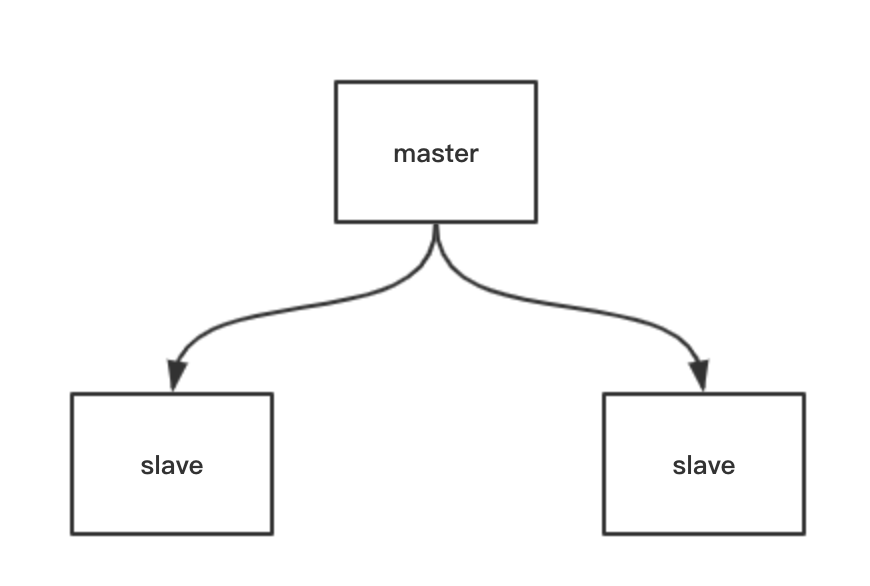
3.Redis 有哪些架构模式?讲讲各自的特点
答:主从模式,一般是一个主节点,一或多个从节点,为了保证我们的主节点宕机后,数据不丢失,我们将主节点的数据备份到从节点,从节点并不进行实际操作,只做实时同步操作,并不能起到高并发的目的。
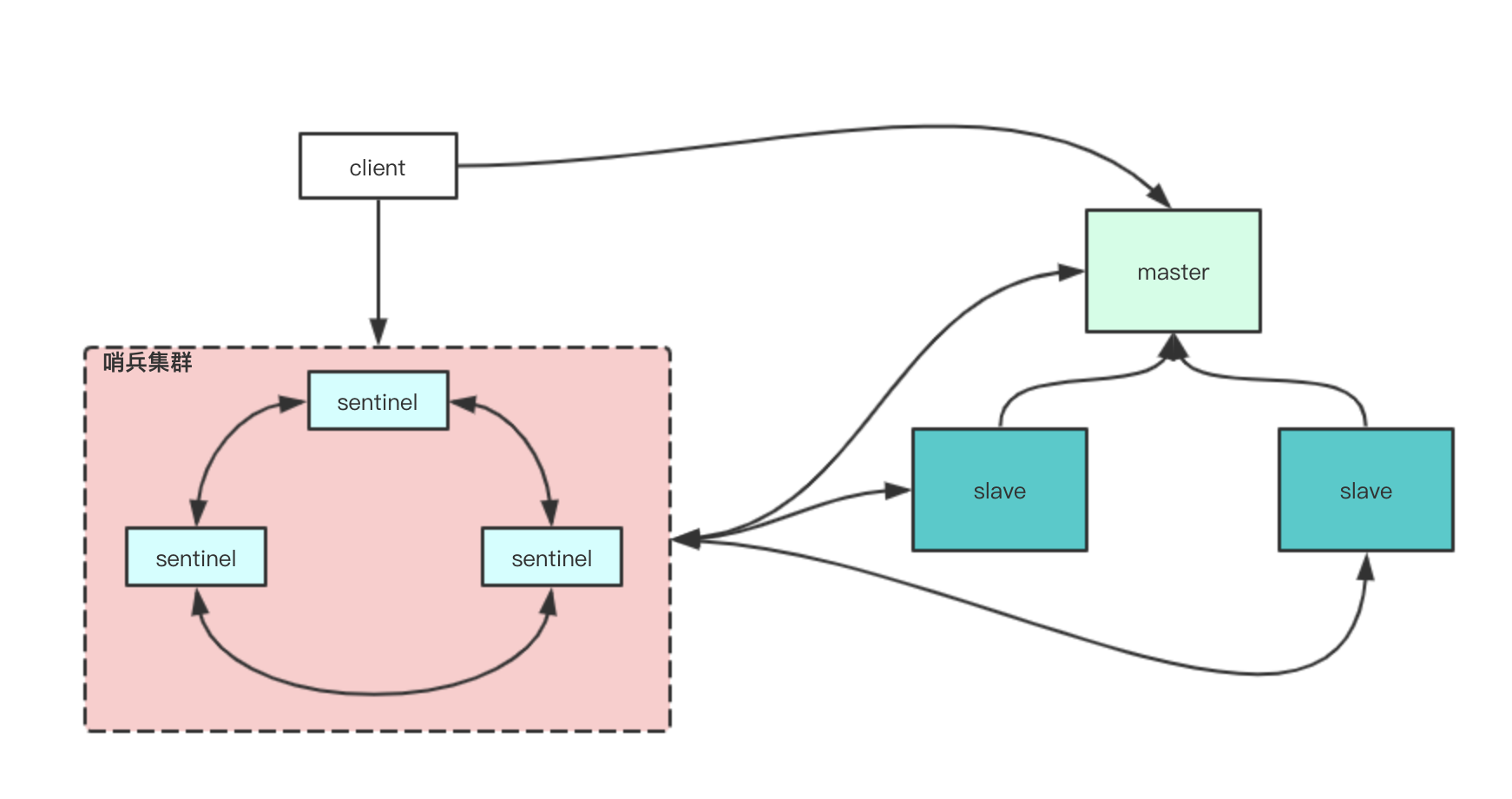
哨兵模式,一个哨兵集群和一组主从架构组成。比主从更好的是当我们的主节点宕机以后,哨兵会主动选举出一个主节点继续向外提供服务。
集群架构,由很多个小主从聚集在一起,一起向外提供服务的,将16384个卡槽切分存储,并不是一个强一致性的集群架构,每一个小主从节点内会存在选举机制,保证对外的高可用架构。
4.Redis常用命令?
答:setnx,单次插入,incr,DECR原子加减,lpush列表左侧插入,rpush列表右侧插入,rpop列表右侧移除,blpop key timeout 从列表key的表头(最左侧)弹出第一个元素,sadd集合中添加元素,sismember判断元素是否在集合中,sinter交集,sunion并集,sdiff差集,zadd有序集合添加元素。
5.使用过Redis分布式锁么,它是怎么实现的?
答:用过分布式锁,用setnx来简单实现的,设置setnx,也就是锁的争抢,设置成功的即为拿到锁的,锁需要设置最大等待时间,并设置方法内的唯一UUID作为Value,防止其它线程解锁。方法结束以后,用finnal来解锁,需要判断value值为当前UUID才可以解锁,这样就简单实现了一个分布式的锁,为了保证原子性操作可以采用lua脚本来执行中间判断步骤。还有很成熟的redisson来设置我们的分布式锁,也解决了我们上面最大等待时间多久合适的争议。redisson底层是这样来做的,我们设置了一个线程锁,超时时间比如设置了30秒,方法开始执行,这时redisson会开启一个分线程,来查询主线程的方法是否执行完成,大概是没30/3秒执行一次,即使到了30秒还没有执行完,redisson也不会将锁释放掉,会继续给予锁10秒的生命时间,来继续使主线程正常运行,直到时间加到主线程执行完成为止。

6.使用过Redis做异步队列么,你是怎么用的?有什么缺点?
答:用过,用列表数据来实现的。大致就是左侧进入lpush,右侧弹出brpop,或者相反的方向也是可以的,但是用我们的redis实现的消息队列,消息的发布是无状态的,无法保证可达,若订阅者在发送者发布消息期间下线,之后我们再上线将无法接受到刚才发送的消息,解决办法就是使用消息队列
7.什么是缓存穿透?如何避免?什么是缓存雪崩?何如避免?
答:缓存击穿是指经过缓存层并没有得到我们想要的数据,请求会向下请求我们的数据库,这就是缓存击穿,我们可以在每次请求数据库返回时做一个保存操作,即使没有值也保存一下,记得设置好超时时间,现在没有值,不代表永远没有值。
缓存雪崩是指redis宕机造成服务无法继续使用,或者大量的命令阻塞的redis,造成假死现象,使得请求直接访问我们的数据库,请求量巨大,可能压垮我们的数据服务器,可以使用高可用的架构来做redis服务,比如哨兵架构,集群架构,避免用单机的redis来作为缓存服务,对于并发量超大的情况我们可以使用限流的方式来控制。比如hystrix
8.redis的单线程为什么那么快
答:因为它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换中性能损耗的问题。
9.Redis有哪几种数据淘汰策略?
答:默认策略是volatile-lru,即超过最大内存后,在过期键中使用lru算法进行key的剔除,保证不过期数据不被删除,但是可能会出现OOM问题。
其他策略如下:
allkeys-lru:根据LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止。
allkeys-random:随机删除所有键,直到腾出足够空间为止。
volatile-random: 随机删除过期键,直到腾出足够空间为止。
volatile-ttl:根据键值对象的ttl属性,删除最近将要过期数据。如果没有,回退到noeviction策略。
noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息"(error)OOM command not allowed when used memory",此时Redis只响应读操作。

10.一个字符串类型的值能存储最大容量是多少?
答:512M,但是并不建议存储bigKeys的数值,本来就是单线程的redis,如果你使用了bigKey的体积较大的数值可能造成网络拥塞,同时也影响使用的效率,建议单个键值对大小不超过10kb。
11.Redis有哪些适合的场景?
答:文章点赞模型,incr,DECR原子加减来实现,队列操作lpush和rpop,栈的操作lpush和lpop,关注模型,使用列表的交集并集来推荐可能认识的人,购物车模型,使用哈希存储来方面存取。
12.Jedis与Redisson对比有什么优缺点?
答:Jedis是连接redis最常用的插件,底层用java编写的,对于redis的单机命令集成的非常好,但是对于一些集群的操作不是很友好的,而Redisson也是连接我们redis的重要插件,但是集成的redis命令并不理想,可他提供了强大的分布式锁供我们来使用,在分布式中,相比jedis,redisson表现的更为出色。
13.Redis中的管道有什么用?
答:管道就是通过一次网络请求,一起塞给Redis客户端多条命令,不存在事务的控制,就是说,当我们其中的命令报错了,并不会中断我们管道的继续执行,同时已经执行完的操作,也会持久化下来。

14.谈一下redis中的事务
答:redis自身的事务并不是很好用的,一般我用Lua脚本来代替Redis的事务。用eval来执行我们的Lua脚本。
15.Redis如何做内存优化?
答:上述提到过一些优化的方法,比如我们的键最好设置为见名识意的,但是不要设置的过长,尽力的避免设置bigkey,如果真的无法避免bigkey,可以考虑水平拆分。
16.Redis分区有什么缺点?
答:redis集群并不是一个强一致的集群,通过CRC16算法分配我们的16384个卡槽上的,这时可能造成我们的一些命令失效,比如我们取得交集,并集等命令,还有我们的批量get,批量set命令。如果不在一个服务主从集群上,会造成命令报错。


最进弄了一个公众号,小菜技术,欢迎大家的加入
