转载至:https://blog.csdn.net/chaipp0607/article/details/99879081
评价标准
二分类的精准率和召回率
人脸检测是目标检测的一个特例,因为目标类别只有一类,剩下的都是背景,所以人脸检测评价标准中会用到些二分类问题的评价,在这里先提一下。
二分类问题最常用的就是精准率和召回率:
- 精准率代表着预测为正的样本中有多少是正确的;
- 召回率代表着总的正样本中有多少正样本被成功预测出来。
假设实际测试集中有100个正样本和100负样本,100个正样本有90个预测为正,10个预测为负;100个负样本中有80个预测为负,20个预测为正,那么TP,TN, FP , FN分别是:
TP代表着本次预测为True,预测为Positive,预测为正,并且预测是正确的,把正的预测为正就是正确的,于是TP=90;
TN代表着本次预测为True,预测为Negtive,预测为负,并且预测是正确的,把负的预测为负就是正确的,于是TN=80 ;
FP代表着本次预测为Flase,预测为Positive,预测为正,但是预测是错误的,把负的预测为正就是错误的,于是FP=20 ;
FN代表着本次预测为Flase,预测为Negtive,预测为负,但是预测是错误的,把正的预测为负就是错误的,于是FN=10;
有了上面四个值之后,就可以计算精准率Precision和召回率Recall了:

剩下还有一些指标,比如准确率Acc,这个评价最符合一般认知,就是别管是正的负的,只要是对的就行:

F1是精准率和召回率的综合,是综合评价标准下的一个特例:
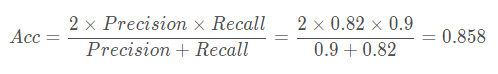
人脸检测中的精准率和召回率
刚刚提到了人脸检测里只有人脸和背景两类,那么如果用精准率,召回率去评价人脸检测应该怎么做?
首先检测问题是有Bbox框,要把检测问题当做分类来处理,就要定义出什么样的检测结果是正确的,一般情况下,当检测框的和Ground Truth的IOU大于0.5时,认为这张人脸被正确的检测到,有了这个前提,就可以按照二分类那样统计了。
假设实际测试集中有100张脸,检测算法一共生成了95个Bbox,95个Bbox里有90是正确的,剩下的5个是错误的检测。那么TP ,TN, FP , FN分别是:
所有判定为人脸的结果有90个正确,TP=90;
对于人脸检测任务,背景类不输出结果,TN=0;
所有判定为人脸的结果有5个错误,预测为人脸但实际是非人脸,FP=5;
所有人脸中有10个被漏检,实际是人脸,但是没有预测出来,于是FN=10;
精准率Precision PrecisionPrecision和召回率Recall RecallRecall可以计算:

召回率在人脸检测里也被称为人脸的检测率,就是检测出来的人脸占总人脸的比例;
精准率就是检测为人脸的框中实际有多少是真正的人脸;
精准率的对立就是误检率,也就是检测为人脸的框中实际有多少是非人脸;精准率+误检率=1;
对于一个固定的数据集,我们可以把每张图都测一遍,然后统计模型的检测率,精准率,误检率,当然还可以算下准确率和F1,然后比较各个模型的性能,但是这样的话,就可能会出现模型1检测率高,精准率低,对应的误检率就高。而模型2检测率低,精准率高,对应的误检率就低。这种情况就会不好比,所以就有了另外一种评价,固定一个指标,去比较另一个。
ROC曲线
此外,还可以统计模型的ROC曲线,对于每一个检测出的人脸,检测器都会给出这个检测结果的得分(置信度),那么如果人为地引入一个阈值来对检测结果进行筛选(只保留得分大于阈值得检测结果),那么随着这个阈值的变化,最终得检测结果也会不同,因而其对应得检测率和误检数目也会不同。
通过遍历阈值,我们就能够得到多组检测率和误检数目的值,由此我们可以在平面直角坐标系中画出一条曲线来:
以x坐标表示误检数目,以y坐标表示检测率,这样画出来的曲线称之为ROC曲线。ROC曲线上每一个点都是一个统计结果,对应同一模型的不同阈值,下方对应的面积越大,模型的性能越好。ROC曲线提供了一种非常直观的比较不同人脸检测器的方式,得到了广泛的使用。
固定误检测召回率
在有了ROC曲线的前提下,就可以计算出**张误检下的召回率。
比如一个模型的精准率很高,输出出来的框几乎都是正确的,这个模型遍历完测试集,都没有达到100个误检,那么它的召回率也不一定很高,因为它可能漏检多;
还有一种情况是,模型有很高的召回率,实际的人脸都能被检测出来,但是输出出来的框有很多错误,还没有遍历完数据集就已经达到100个误检了,那么它原本很高的召回率在“100张误检下召回率”这个评价标准中也体现不出来。
所以,固定误检测召回率的方式能够测出模型的综合性能。
常用数据集
FDDB
FDDB总共2845张图像,共包含5171张人脸,人脸非约束环境,人脸的难度较大,有面部表情,双下巴,光照变化,穿戴,夸张发型,遮挡等难点,是目标最常用的数据库。有以下特点:
图像分辨率较小,所有图像的较长边缩放到450,也就是说所有图像都小于450450,最小标注人脸2020,包括彩色和灰度两类图像。每张图像的人脸数量偏少,平均1.8人脸/图,绝大多数图像都只有一人脸;
比如最新开源的SeetaFace2,在FDDB上,100张误检检测率达到92%。
参考链接:
WIDER FACE
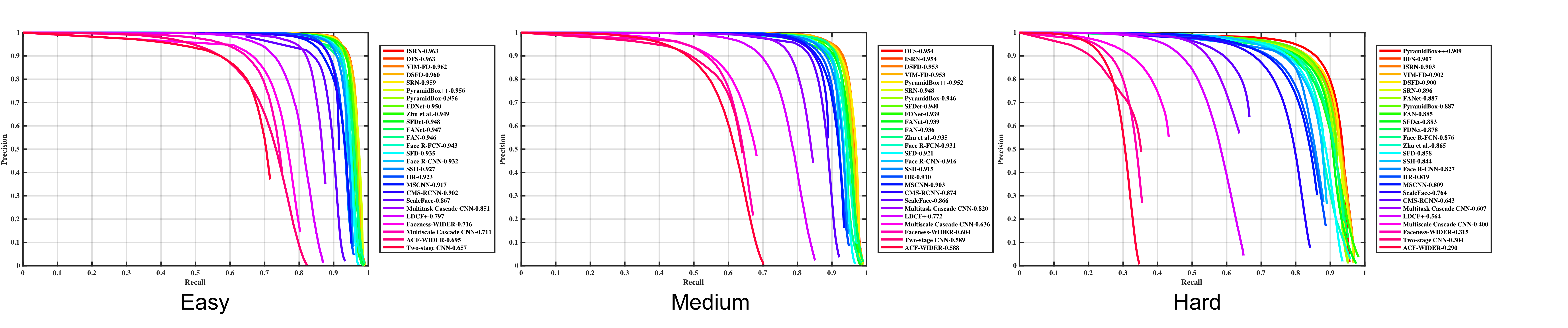
WIDER FACE是当前人脸检测任务最主流的数据集,总共32203图像,393703标注人脸,人脸包含各种尺度,姿态,遮挡,表情,化妆,光照等。图像分辨率普遍偏高,所有图像的宽都缩放到1024,最小标注人脸10*10,都是彩色图像; 每张图像的人脸数据偏多,平均12.2人脸/图,密集小人脸非常多;
分训练集train/验证集val/测试集test,分别占40%/10%/50%,而且测试集的标注结果(ground truth)没有公开,需要提交结果给官方比较,更加公平公正,而且测试集非常大,结果可靠性极高;
根据EdgeBox的检测率情况划分为三个难度等级:Easy, Medium, Hard。
目前,wider face上排在第一位的是创新奇智(AInnovation)的AInnoFace
Performance curves for the validation set
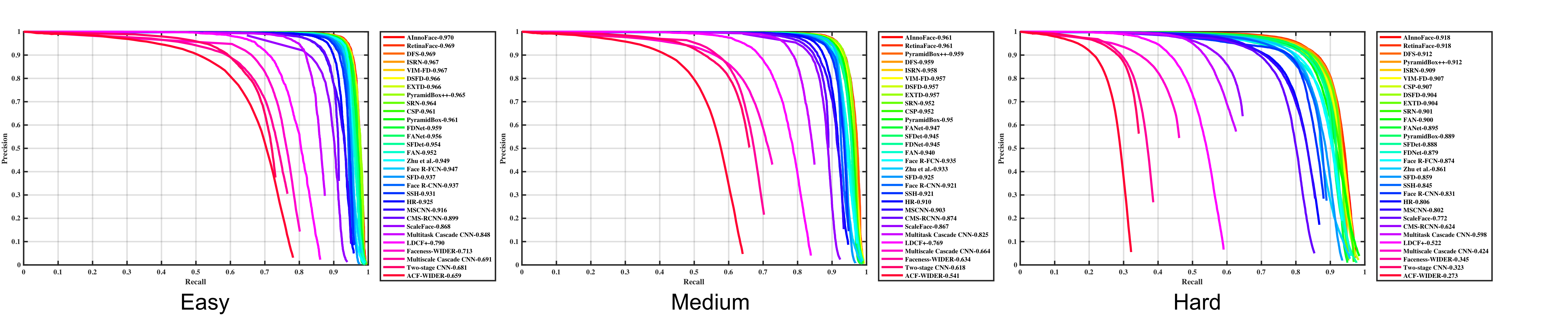
Performance curves for the test set