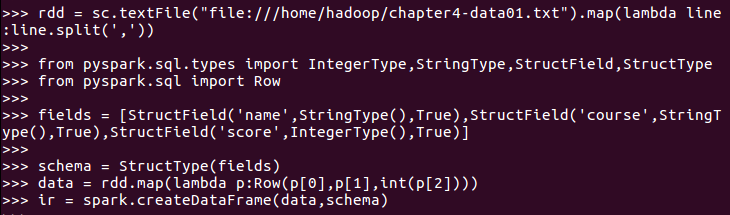
用DataFrame的操作或SQL语句完成以下数据分析要求,并和用RDD操作的实现进行对比:
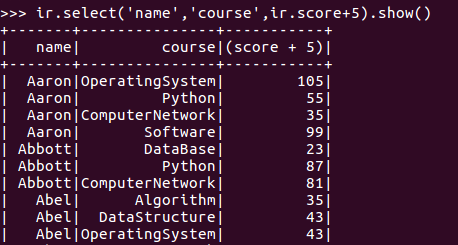
每个分数+5分。
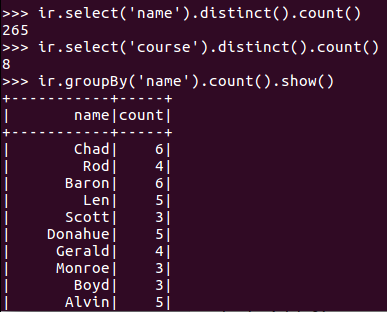
2.总共有多少学生?
3.总共开设了哪些课程?
4.每个学生选修了多少门课?
5.每门课程有多少个学生选?
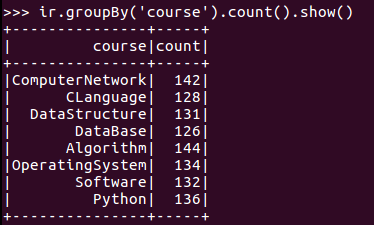
6.每门课程大于95分的学生人数?
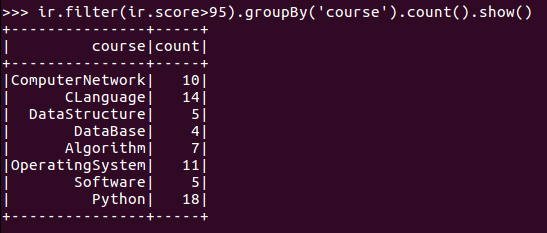
7.Tom选修了几门课?每门课多少分?

8.Tom的成绩按分数大小排序。

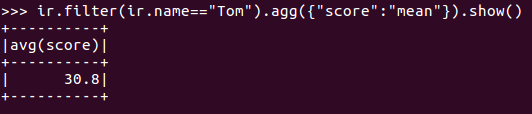
9.Tom的平均分。
10.求每门课的平均分,最高分,最低分。
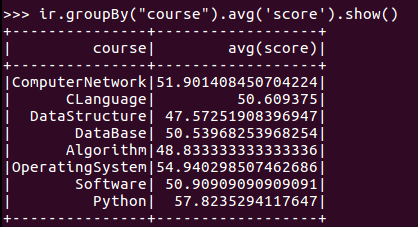
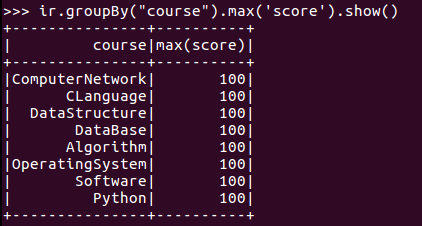
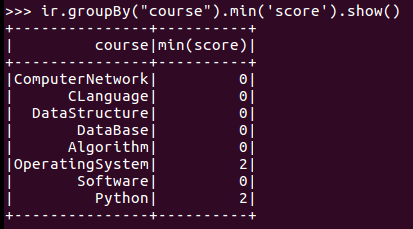
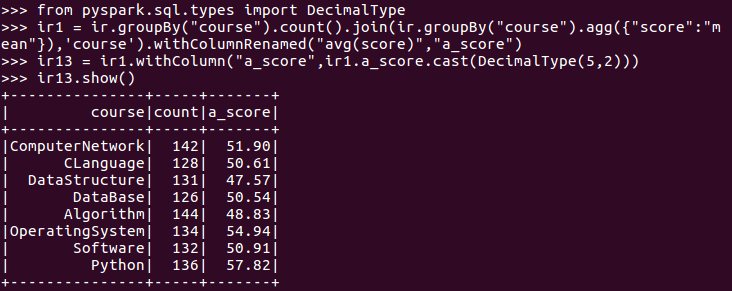
11.求每门课的选修人数及平均分,精确到2位小数。
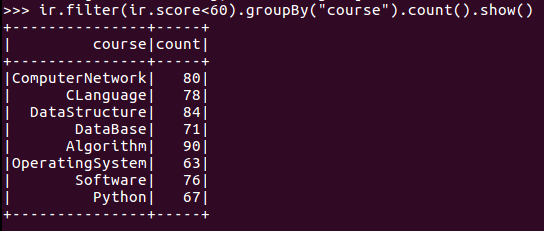
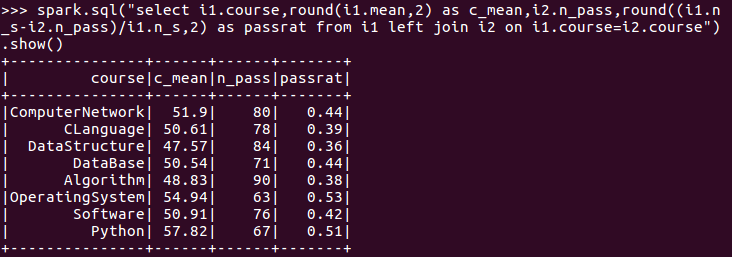
12.每门课的不及格人数,通过率
二、用SQL语句完成以上数据分析要求
1.每个分数+5分。
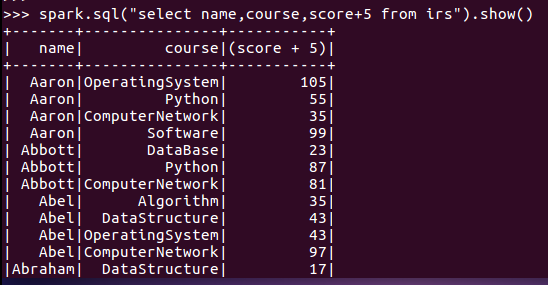
2.总共有多少学生?
3.总共开设了哪些课程?
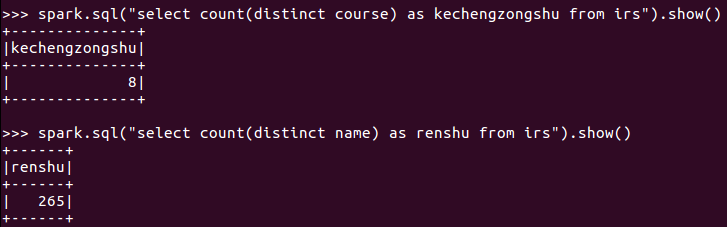
4.每个学生选修了多少门课?

5.每门课程有多少个学生选?
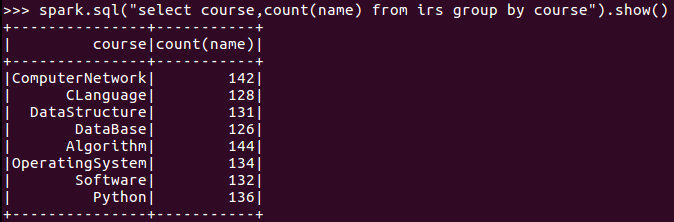
6.每门课程大于95分的学生人数?
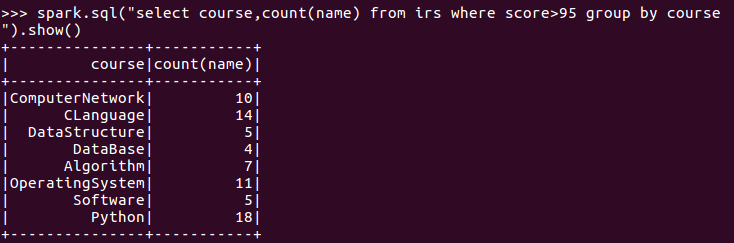
7.Tom选修了几门课?每门课多少分?
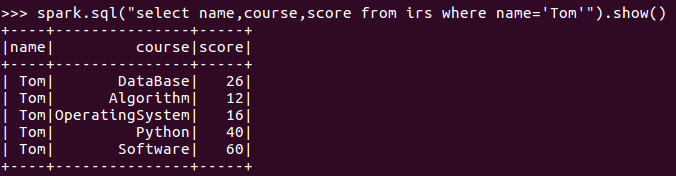
8.Tom的成绩按分数大小排序。
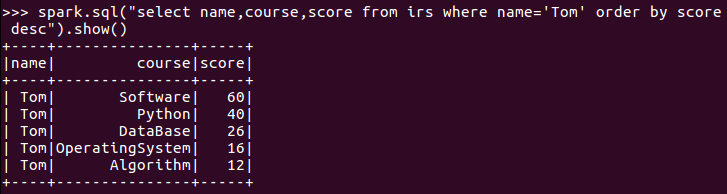
9.Tom的平均分。

10.求每门课的平均分,最高分,最低分。
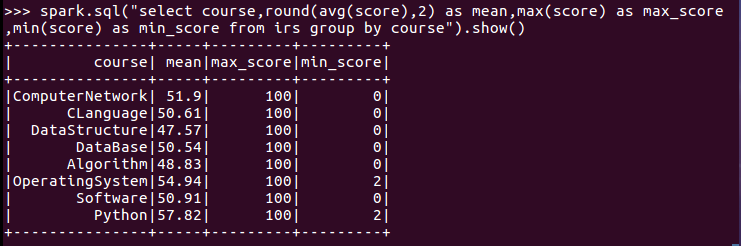
11.求每门课的选修人数及平均分,精确到2位小数。
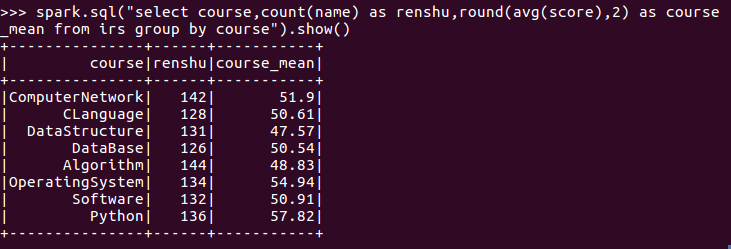
12.每门课的不及格人数,通过率

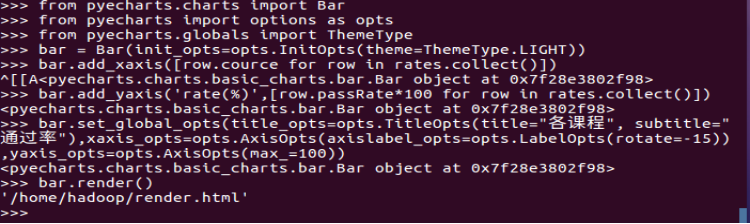
结果可视化
rates=spark.sql("SELECT cource,SUM(failed) AS failedNumber,CAST(SUM(passNumber) / COUNT(1) AS DECIMAL(5,2)) AS passRate FROM (SELECT cource,(CASE WHEN score>=60 THEN 1 ELSE 0 END) AS passNumber,(CASE WHEN score<60 THEN 1 ELSE 0 END) AS failed FROM scs) group by cource")
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.globals import ThemeType
bar = Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
bar.add_xaxis([row.cource for row in rates.collect()])
bar.add_yaxis('rate(%)',[row.passRate*100 for row in rates.collect()])
bar.set_global_opts(title_opts=opts.TitleOpts(title="各课程", subtitle="通过率"),xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),yaxis_opts=opts.AxisOpts(max_=100))
bar.render()