数据挖掘
R语言数据可视化部分
散点图
|
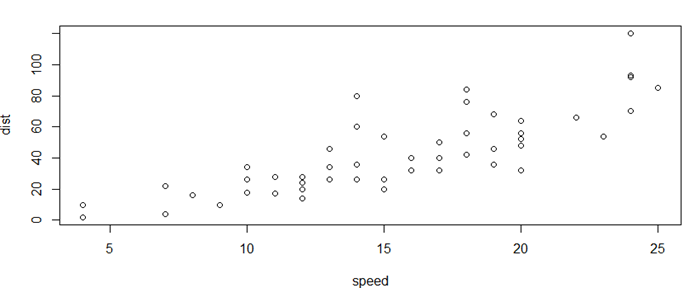
library(datasets) head(cars) plot(cars) |
|
|
plot(cars$dist,cars$speed,xlab = "dist", ylab = "speed",xlim = c(0,20)) |

|
|
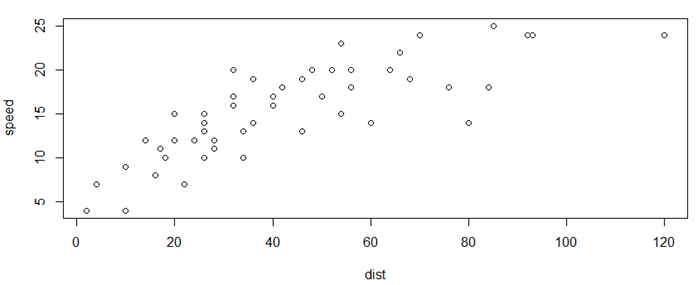
attach(cars) plot(dist,speed,xlab = "dist",ylab = "speed") |
|
|
plot(cars$dist,cars$speed,xlab = "dist",ylab = "speed",main = "cars 散点图",type="b",pch=4,lwd=2,col="red") |

|
|
a<-c(20,30,40,50,60) b<-c(11,22,33,44,66) c<-c(15,25,35,45,55) plot(a,b,type = "b")#有点,用线连接 plot(a,b,type = "o")#有点,线连接,线过点 plot(a,b,type = "p")#点图 plot(a,b,type = "h")#用线表示值 plot(a,b,type = "l")#直接线链接 plot(a,b,type = "s")#梯形图 plot(a,b,type = "S")#梯形图 plot(a,b,type = "n")#不做图 |
|
|
plot(a,b,pch=0) plot(a,b,pch=1) plot(a,b,pch=2) plot(a,b,pch=3) plot(a,b,lty=2,lwd=2,pch=15,cex=2) plot(a,b,type="b",lty=2,lwd=2,pch=15,cex=2) |
|
|
install.packages("RColorBrewer") library(RColorBrewer) plot(a,b,type="b",lty=2,lwd=2,pch=15,cex=2,col=2) opar<-par(no.readonly = FALSE) par(pin=c(2,3)) par(lwd=2,cex=1.5) par(cex.axis=.75,font.axis=3) |

|
|
plot(a,b,type="b",pch=19,lty=2,col=2) |
|
|
plot(a,b,type="b",pch=23,lty=5,col=2,bg="green") par(opar) |
|
|
par(mfrow = c(2, 2)) plot(a,c,type = "o",col=3,lty=3,pch=3,lwd=4, main = "实验图形",xlab="a",ylab="c", xlim = c(0,100),ylim=c(0,100)) x<-c(1:15) y<-x z<-10/x opar<-par(no.readonly = TRUE) par(mar=c(5,4,4,8)+0.1) plot(x,y,type = "b",pch=21,col=2,yaxt="n",lty=3,ann = FALSE) lines(x,z,type = "b",pch=3,col=4,lty=2) axis(side = 2,at=x,labels = x,col.axis=2,las=2) axis(side = 4,at=z,labels = round(z,digits = 2), cex.axis=2,las=2) par(opar) |

|
|
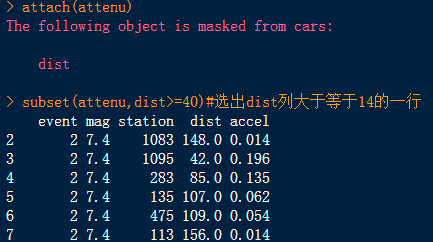
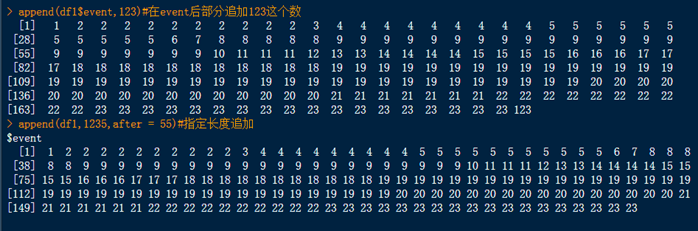
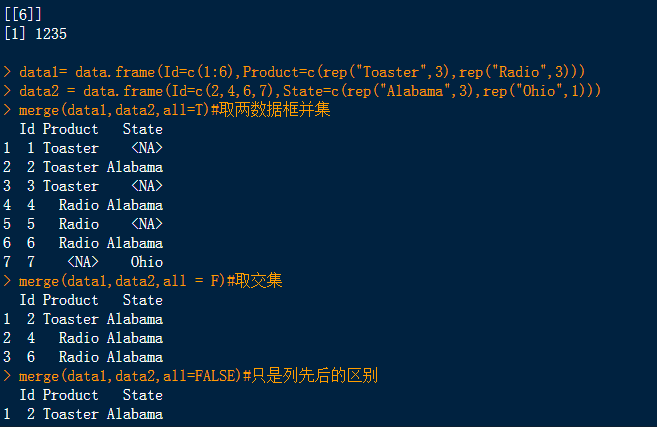
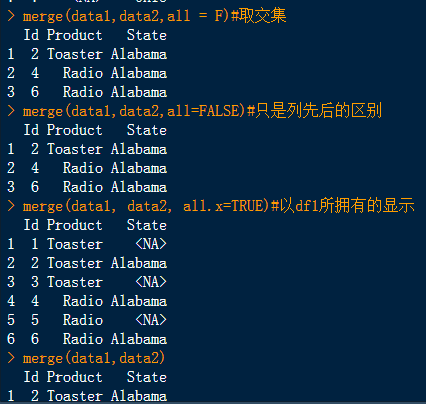
library(datasets)#加载数据包 attenu# attach(attenu) subset(attenu,dist>=40)#选出dist列大于等于14的一行 df<-subset(attenu,event=="2" & dist=="107",select=c(dist));df#显示特定的行 s=subset(attenu,event=="2" & dist=="107",select=c(event,dist));s#多条件查询 df1<-as.list(attenu);df1#转换成列表 append(df1$event,123)#在event后部分追加123这个数 append(df1,1235,after = 55)#指定长度追加 data1= data.frame(Id=c(1:6),Product=c(rep("Toaster",3),rep("Radio",3))) data2 = data.frame(Id=c(2,4,6,7),State=c(rep("Alabama",3),rep("Ohio",1))) merge(data1,data2,all=T)#取两数据框并集 merge(data1,data2,all = F)#取交集 merge(data1,data2,all=FALSE)#只是列先后的区别 merge(data1, data2, all.x=TRUE)#以df1所拥有的显示 merge(data1,data2) #有两个及以上相同的列,合并则会自动选择两个均相同的, #结果同merge(df1, df2, by = c("id", "sex")) merge(data1,data2,by="Id")#两数据框中共有的sex那一列则会以sex.x和sex.y形式输出。 #aggregate()函数 |

|
|
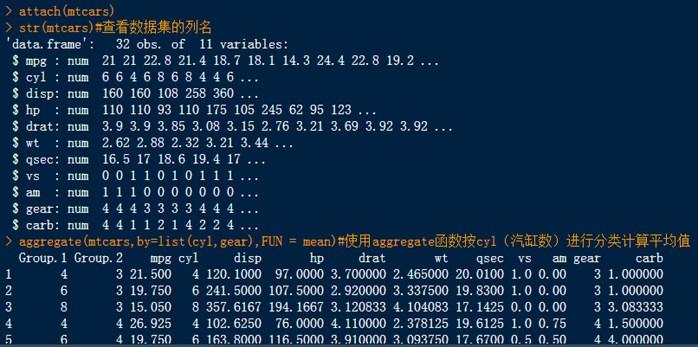
#aggregate()函数 mtcars#R语言自带的汽车数据集 attach(mtcars) str(mtcars)#查看数据集的列名 aggregate(mtcars,by=list(cyl,gear),FUN = mean)#使用aggregate函数按cyl(汽缸数)进行分类计算平均值 #公式是一种特殊的R数据对象,在aggregate函数中使用公式参数可以对数据框的部分指标进行统计 aggregate(cbind(mpg,hp) ~ cyl+gear, FUN=mean) #频次统计table table(hp)#统计mtcars数据中的hp列中出现结果频次 #函数apply(),list,matrix,array三种形式均可以 rname = c("r1","r2","r3") cname = c("c1","c2") b<-matrix(1:6,nrow=3, dimnames = list(rname, cname)) apply(b,1,sum)#1—表示按行计算,2—按列计算; apply(b,2,sum)#1—表示按行计算,2—按列计算; m<-c("SPYDERMAN","BATMAN","VERTIGO","CHINATOWN") m1<-lapply(m,tolower)#把大写的字符改成小写 m1 sapply(mtcars,min)#查找数据框中最小的 tapply(mtcars$mpg, INDEX=mtcars$mpg, FUN = mean)#计算数据框中的列或者向量里的均值 |

|






条形图
|
#条形图 install.packages("vcd") install.packages("plottrix") install.packages("sm") install.packages("vioplot") library(vcd) a<-table(Arthritis$Treatment);a hist(a) barplot(a,main = "条形图",ylab="Frequency", xlab="Treatment",ylim=c(0,50))#条形图绘制 barplot(a,main = "条形图",ylab="Treatment", xlab="Frequency",xlim=c(0,50),horiz=TRUE)#条形图绘制 plot(Arthritis$Improved,main = "条形图",xlab="Improved", ylab="Frequency") |

|
|
counts <- table(Arthritis$Improved, Arthritis$Treatment) counts #堆切 barplot(counts, main = "条形图", xlab = "Treatment", ylab = "Frequency", col = c("red", "yellow", "green"), legend = rownames(counts)) |

|
|
#分组 barplot(counts, main = "条形图", xlab = "Treatment", ylab = "Frequency", col = c("red", "yellow", "green"), legend = rownames(counts), beside = TRUE) |

|
|
#均值条形图 states <- data.frame(state.region, state.x77) means <- aggregate(states$Illiteracy, by = list(state.region), FUN = mean)#以列表的形式计算均值 means means <- means[order(means$x), ]#排序 means barplot(means$x, names.arg = means$Group.1)#把均值做条形图 title("Mean Illiteracy Rate") |

|
|
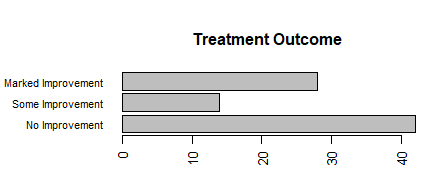
#调条形图 par(mar = c(5, 8, 4, 2))#增加Y的边界 par(las = 2)#旋转条形图的标签 counts <- table(Arthritis$Improved) barplot(counts, main = "Treatment Outcome", horiz = TRUE, cex.names = 0.8, names.arg = c("No Improvement", "Some Improvement", "Marked Improvement")) |
|
|
#棘状图用spine(),看比例 attach(Arthritis) counts <-table(Treatment, Improved) spine(counts, main = "棘状图") detach(Arthritis) |

|
饼图
|
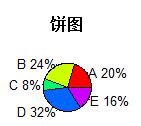
#饼图 par(mfrow = c(2, 2)) s<- c(10, 12, 4, 16, 8) lbls <- c("A", "B", "C", "D", "E") pie(s,labels = lbls, main = "饼图") pct <- round(s/sum(s) * 100)#求百分比 lbls2 <- paste(lbls, " ", pct, "%", sep = "") pie(s, labels = lbls2, col = rainbow(length(lbls)), main = "饼图") |
|
|
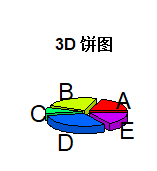
install.packages("plotrix") library(plotrix) pie3D(s, labels = lbls, explode = 0.1, main = "3D 饼图 ") mydata<-table(state.region) lbls <-paste(names(mydata), " ", mydata, sep = "") pie3D(mydata, labels = lbls, main = "饼图1") |
|
|
#扇形图 slices<-c(10, 12, 4, 16, 8) lbls<-c("US", "UK", "Australia", "Germany", "France") fan.plot(slices, labels = lbls, main = "扇形图") |

|


散点图
|
#散点图 attach(mtcars) par(mfrow=c(2,2)) plot(wt, mpg, main="Basic Scatterplot of MPG vs. Weight", xlab="Car Weight (lbs/1000)", ylab="Miles Per Gallon ", pch=19) abline(lm(mpg ~ wt), col="red", lwd=2, lty=1) lines(lowess(wt, mpg), col="blue", lwd=2, lty=2) #loess(),lowess() library(car) scatterplot(mpg ~ wt | cyl, at=cyl,data=mtcars, lwd=2, main="Scatter Plot of MPG vs. Weight by Cylinders", xlab="Weight of Car (lbs/1000)", ylab="Miles Per Gallon", id.method="identify", legend.plot=TRUE, labels=row.names(mtcars), boxplots="xy") |
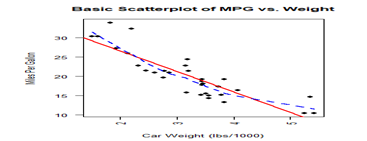
|
|
#散点图矩阵 attach(mtcars) pairs(~mpg+disp+wt+drat,data=mtcars,main="汽车数据矩阵散点图") library(car) scatterplotMatrix(~mpg+disp+drat+wt,data=mtcars,spread=FALSE, smoother.args=list(lty=2), main="散点图矩阵") #spread=FALSE;选项表示不添加展示分散度和对称信息的直线 #smoother.args=list(lty=2);设定loess()拟合曲线是用虚线而不是实线 |
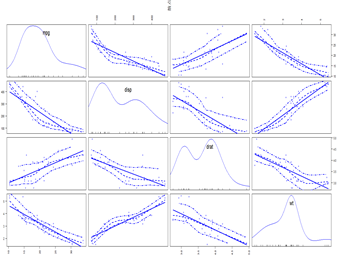
|
|
scatterplotMatrix(~mpg+disp+drat+wt,data=mtcars,spread=TRUE, smoother.args=list(lty=1), main="散点图矩阵") #不同风格 install.packages("glus") library(glus) install.packages("TeachingDemos") library(TeachingDemos) pairs2() install.packages("HH") installed.packages("ResourceSelection") |

|
|
#高密度散点图 set.seed(1234) n <- 10000 c1 <- matrix(rnorm(n, mean=0, sd=0.5), ncol=2) c2 <- matrix(rnorm(n, mean=3, sd=2), ncol=2) mydata <- rbind(c1, c2) mydata <- as.data.frame(mydata) names(mydata) <- c("x", "y")
with(mydata, plot(x, y, pch=19, main="高密度散点图"))
|

|
|
with(mydata, smoothScatter(x, y, main="高密度散点图")) |
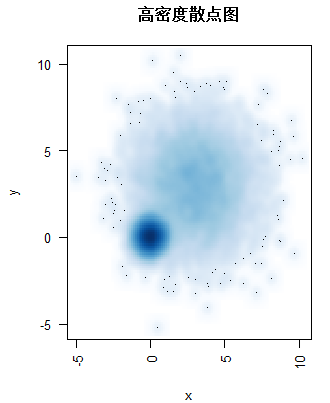
|
|
library(hexbin) with(mydata, { bin <- hexbin(x, y, xbins=50) plot(bin, main="Hexagonal Binning with 10,000 Observations") }) |

|
|
library(IDPmisc)#做的散点图对大数据集的创建可读性比较好 with(mydata, iplot(x, y, main="Image Scatter Plot with Color Indicating Density")) par(opar) |

|
|
#多维可视化散点图 install.packages("scatterplot3d") library(scatterplot3d) attach(mtcars) scatterplot3d(wt,disp,mpg,main = "3d 散点图") scatterplot3d(wt, disp, mpg, pch=16, highlight.3d=TRUE, type="h", main="3D 散点图") #highlight.3d=TRUE;填充颜色 s3d <-scatterplot3d(wt, disp, mpg, pch=16, highlight.3d=TRUE, type="h", main="3D 散点图") |
|
|
fit <- lm(mpg ~ wt+disp) s3d$plane3d(fit) detach(mtcars) |
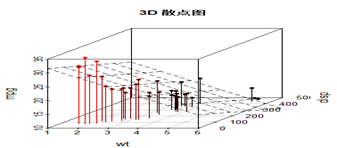
|
|
#3d旋转散点图1 install.packages("rgl") library(rgl) attach(mtcars) plot3d(wt,disp,mpg,col="blue",size=5) |
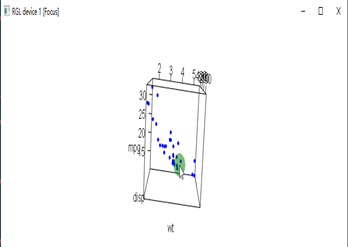
|



折线图
|
#展示五种树的生长情况 Orange$Tree<- as.numeric(Orange$Tree)#转换成数值型 ntrees <-max(Orange$Tree);ntrees #创建图形 #range返回一个包含所有给定参数的最小值和最大值的向量。 xrange <- range(Orange$age);xrange yrange <- range(Orange$circumference);yrange plot(xrange, yrange, type="n", xlab="Age (days)", ylab="Circumference (mm)") #rainbow创建一个由n个相邻颜色组成的向量。 colors <-rainbow(ntrees) linetype <- c(1:ntrees)#绘制1:5的颜色 plotchar <-seq(18,18+ntrees,1);plotchar#绘图的类型 #绘制图形 for (i in 1:ntrees) { tree<-subset(Orange,Tree==i) lines(tree$age,tree$circumference, type="b", lwd=2, lty=linetype[i], col=colors[i], pch=plotchar[i] ) } #lty=linetype[i], 1-5的绘图风格 #col=colors[i],颜色从1-5的编号 #pch=plotchar[i],18-23 的绘制符号 title("树子的生长折线图", "绘图例子") #添加标签legend legend(xrange[1], yrange[2], 1:ntrees, cex=0.8, col=colors, pch=plotchar, lty=linetype, title="Tree" ) # cex=0.8图形缩放0.8倍 |

|
不同包作图比较
|
#不同的程序包作图比较 data<-read.csv("J:shuju/Facet_Data.csv",sep = ",",header = T) str(data) attach(data) #graphics包作图 library(ggplot2) plot(SOD,tau,main = "实验散点图")#散点图 hist(SOD,breaks=30,ylim=c(0,40),main = "") boxplot(SOD~Class,data = data,xlab = "Class",ylab = "SOD") |

|
|||
|
#lattice包作图 library(lattice) xyplot(SOD~tau,col="black",main="实验散点图") histogram(~SOD,data,type="count",nint=30,col="white") bwplot(SOD~Class,data,xlab = "Class",par.settings=canonical.theme(color = FALSE)) |
|
|||
|
#ggplot2包作图 library(graphics) ggplot(data,aes(x=SOD,y=tau))+geom_point(shape=21,main="实验散点图") ggplot(data,aes(SOD))+geom_histogram(bins=30,colour="black",fill="white") ggplot(data,aes(x=Class,y=SOD))+geom_boxplot() |

|


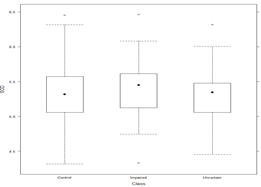
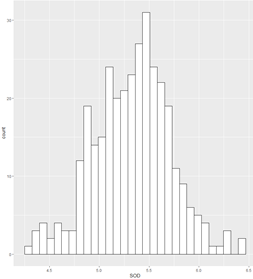
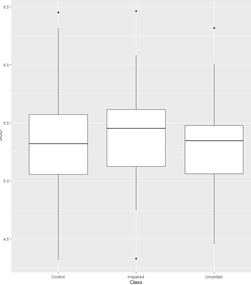
核密度函数图
|
#密度图 mtcars attach(mtcars) par(mfrow = c(2, 1)) d<-density(mpg) plot(d) d<-density(mpg) plot(d, main = "Kernel Density of Miles Per Gallon") polygon(d, col = "red", border = "blue")#填充 rug(mpg, col = "brown") |

|
|
#多组密度图 library(sm) a<-factor(cyl,levels = c(4,6,8), labels = c("4A","6A","8A")) sm.density.compare(mpg,cyl,xlab="hfhhj") title(main = "hyhbhkajbkjhu") c<-c(2:(1+length(levels(a)))) length(locator(1),levels(a),fill=colfill) |

|
马瑟克图
|
#马赛克图 |

|
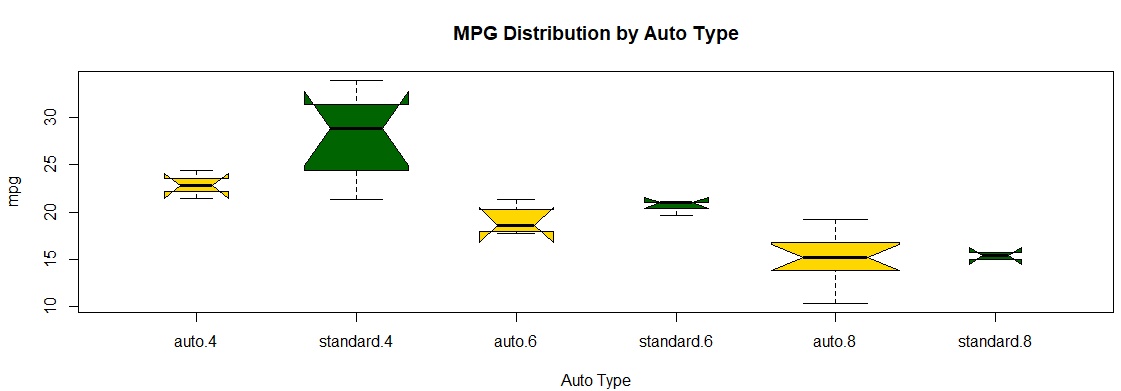
箱线图
|
#箱线图 mtcars$am.f <- factor(mtcars$am, levels = c(0, 1), boxplot(mpg ~ am.f * cyl.f, data = mtcars, |

|


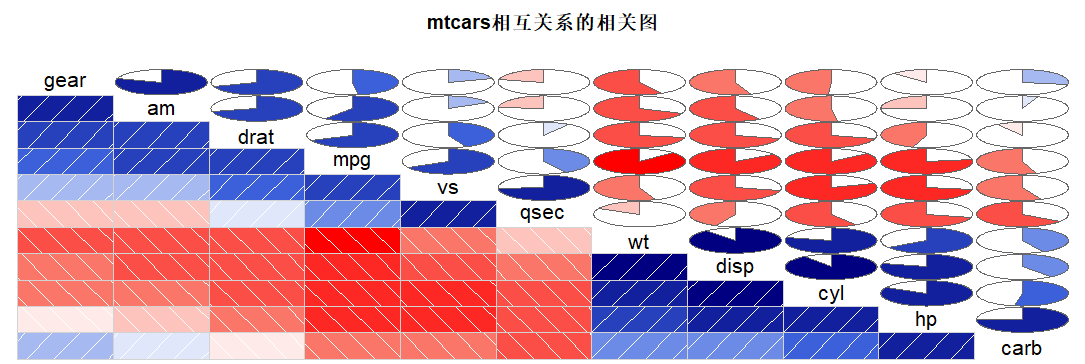
相关图
|
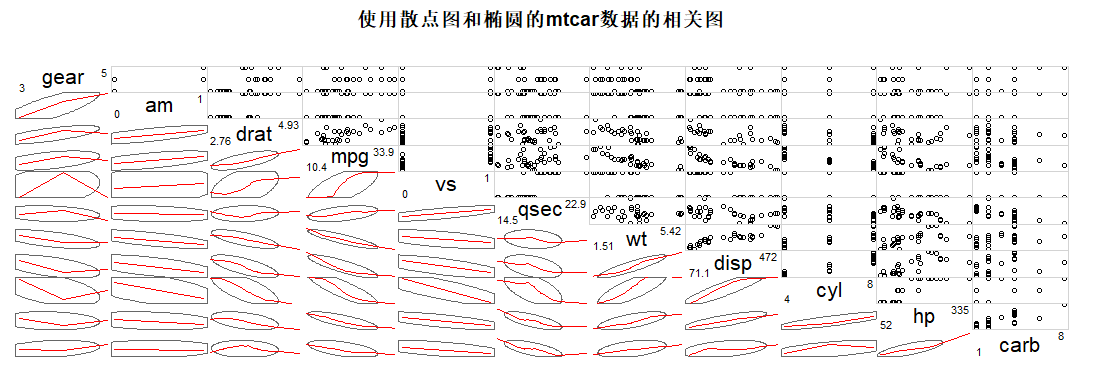
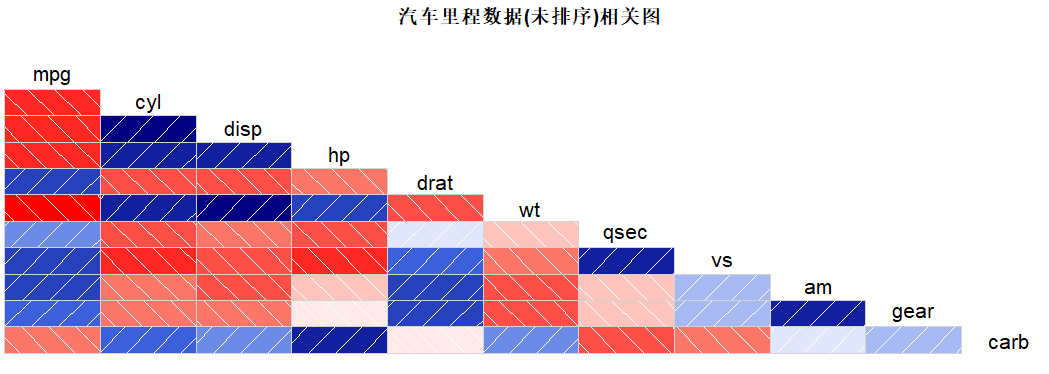
#相关图 corrgram(mtcars, lower.panel=panel.shade, |
|