读写分离是互联网应用系统中提升数据访问性能最常见的一种技术,现在开源社区等都有很多成熟的组件来实现这个功能,虽然是一种常见技术,但是你了解的有几种读写分离方案呢?我们这篇文章就来专门讲述一下读写分析的各种常见实现方案。
为什么要读写分离?
我们先来看一个典型的读写分离架构图,如下:
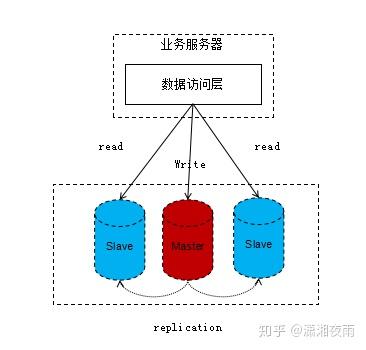
这个架构图阐述了读写分离的标准常见,从主库写入,从库来读取,这种实现是在单机房场景下,我们再来演化一下,如果在多机房场景下又是怎样的呢?
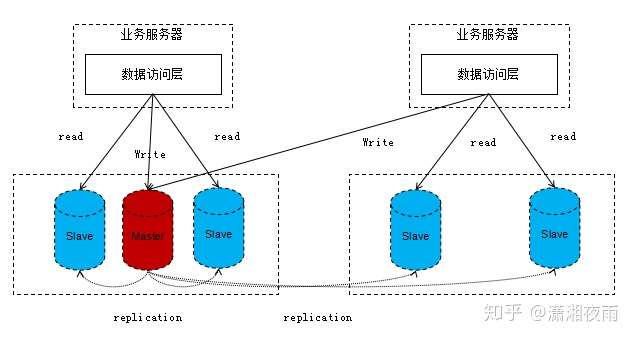
多机房场景下还是一个主库,只是在另外一个机房多出了另外的一些从库,并且写入是直接跨机房连接到主库写入。
从以上两种类型的架构图,我们可以分析出如下几个使用读写分离的原因:
1、读写量很大,为了提升数据库读写性能,将读写进行分离;
2、多机房下如果写少读多,同时基于数据一致性考虑,只有一个主库存入所有的数据写入,本地再做从库提供读取,减少多机房间直接读取带来的时延。
读写分离实现方案
如果要实现读写分离,我们首先就需要知道从业务层到数据库中间会有经过哪几层,了解了这几层,我们的思路就是分别从这些层去实现读写分离,这样就构成了我们不同的实现方案,对于语言我们选择Java来进行分析,其它的类似。

这个图是从开发者的视角来看的,我们可以看出,从Service层一直到数据库,它会经历Dao(数据访问层)、JDBC(Java的数据库连接层)、DataSource(数据源),那我们就从这三个层次分别来介绍它的方案实现。
DAO层
在这一层做读写分离,很容易想到的方案就是初始化两个ORM操作,一个做读,另外一个做写,然后依据业务对数据库操作属性调用相应的ORM,我们举一个简单的例子来看下,例如一个Sample数据表,里面包含:id、名称、状态和创建时间几个字段,我们的例子主要包含:新增、获取、更新及获取操作,看看里面是怎么实现读写分离的(其中的JDBC采取了Spring的JdbcTemplate来实现,这里不做过多代码展示,如有疑问大家可以先查看JdbcTemplate相关技术介绍)
@Repository
public class DaoImpl implements DaoInterFace {
//读数据库连接
@Autowired
private Jdbc readJdbc;
//写数据库连接
@Autowired
private Jdbc writeJdbc;
@Override
public boolean add(String appId, String name) {
StringBuilder sql = new StringBuilder();
sql.append(" insert into sample(app_id, name, status, create_time");
sql.append(" values (?,?,?,?) ");
StatementParameter param = new StatementParameter();
param.setString(appId);
param.setString(name);
param.setBool(true);
param.setDate(new Date());
return writeJdbc.insertForBoolean(sql.toString(), param);
}
@Override
public Sample get(long appId) {
StringBuilder sql = new StringBuilder();
sql.append(" select * from sample where app_id = ? ");
StatementParameter param = new StatementParameter();
param.setLong(appId);
return readJdbc.query(sql.toString(), Sample.class, param);
}
@Override
public Sample updateAndGet(String appId, boolean status) {
StringBuilder writeSql = new StringBuilder();
sql.append(" update sample set status = ? where id = ? and app_id = ?");
StatementParameter readParam = new StatementParameter();
readParam.setBool(status);
readParam.setString(appId);
writeJdbc.updateForBoolean(writeSql.toString(), readParam);
StringBuilder readSql = new StringBuilder();
sql.append(" select * from sample where app_id = ? ");
StatementParameter readParam = new StatementParameter();
readParam.setLong(appId);
//读写窗口一致性,仍然需要采取写入Jdbc来进行读取,以防读库还没有同步到主库的数据
return writeJdbc.query(readSql.toString(), Sample.class, readParam);
}
} 例子新建两个数据库连接JDBC,并且由业务实现人员来明确指定使用哪个JDBC来进行操作数据库,当写入后再读取的场景要保障都使用写入JDBC来实现。这个方案的优缺点我们总结如下:
优点:易于实现
缺点:1、侵入业务,每个数据操作层都需要额外考虑读写分离;
2、对于读写窗口一致性要求操作者自行实现,考虑不周就会导致数据读取失败。
JDBC层
由于DAO层的做法对业务侵入很大,读写分离都需要业务方自行实现,对业务实现方有一定的要求,如果处理不当还有可能出现错误读取,那么我们考虑既然读写分离是一种公共的技术诉求,是否可以再到上面一层做一个封装,将这些内部实现全部封装起来,业务调用方仍然只需关注一个链接,具体里面什么时候读写分离,内部自行实现。这就是JDBC层实现读写分离的价值了,我们先看下它的架构图。
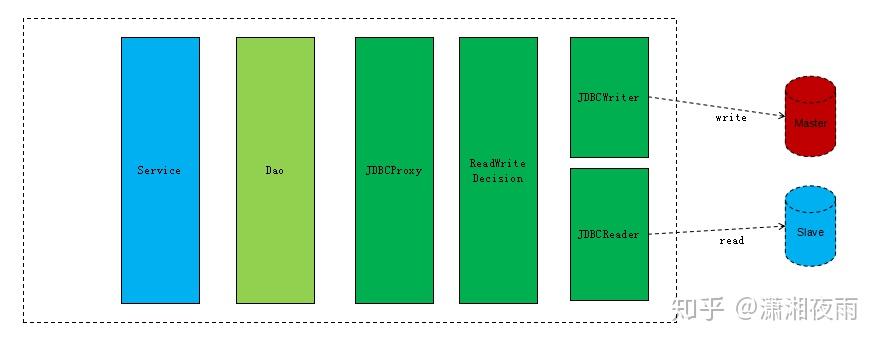
从架构图可以看出,需要将JDBC层的接口函数进行重写,会有一个对业务层暴露的JDBCProxy,它通过读写决策器进行选择此时是使用读还是写连接,JDBCWriter以及JDBCReader都是对JDBC接口的一个实现。我们来看下这种方案的几个重要实现类和方法:
public class JdbcProxyImpl implements Jdbc {
private final static Logger logger = LoggerFactory
.getLogger(JdbcProxyImpl.class);
//读写JDBC实现
private JdbcReaderImpl jdbcReaderImpl;
private JdbcWriterImpl jdbcWriterImpl;
public void setJdbcReaderImpl(JdbcReaderImpl jdbcReaderImpl) {
this.jdbcReaderImpl = jdbcReaderImpl;
}
public void setJdbcWriterImpl(JdbcWriterImpl jdbcWriterImpl) {
this.jdbcWriterImpl = jdbcWriterImpl;
}
//更新的时候首先需要标记为写入,再调用写JDBC来实现更新
@Override
public int update(String sql) {
ReadWriteDataSourceDecision.markWrite();
return jdbcWriterImpl.update(sql);
}
//查询的时候首先是要判断在当前线程下是否有写入操作,如果有就直接使用写JDBC来读取,否则才使用读JDBC
@Override
public <T> T query(String sql, Class<T> elementType) {
if(ReadWriteDataSourceDecision.isChoiceWrite()){
return jdbcWriterImpl.query(sql, elementType);
}
return jdbcReaderImpl.query(sql, elementType);
}
//事务提交属于写入操作属性
@Override
public boolean commit() {
return jdbcWriterImpl.commit();
}
}对于查询操作时会从ReadWriteDataSourceDecision(读写决策器中进行判断),那么读写决策器如何来保存当前线程下的读写操作呢?
public class ReadWriteDataSourceDecision {
public enum DataSourceType {
write, read;
}
//所有读写操作的标记会被记录在这里ThreadLocal,线程安全的
private static final ThreadLocal<DataSourceType> holder = new ThreadLocal<DataSourceType>();
public static void markWrite() {
holder.set(DataSourceType.write);
}
public static void markRead() {
holder.set(DataSourceType.read);
}
public static void reset() {
holder.set(null);
}
public static boolean isChoiceNone() {
return null == holder.get();
}
public static boolean isChoiceWrite() {
return DataSourceType.write == holder.get();
}
public static boolean isChoiceRead() {
return DataSourceType.read == holder.get();
}
}从源码我们可以看出这里有一个比较巧妙的设计,那就是采取了ThreadLocal来存储当前线程下的读写属性,它可以识别出当前线程操作下是否有写入操作,如果有就直接使用写入JDBC来进行读取,保障了读写窗口的一致性。
DataSource层
JDBC层可以很好的解决侵入性以及窗口一致性问题,但是我们在配置的时候仍然是需要为proxy配置两个JDBC,相应的参数都需要完整的设置一遍,还是会比较麻烦,程序猿的使命就是追究极简,有没有我只需要告诉它读写分离的JDBCurl,剩下的一个组件内部全部搞定呢?另外如果主从复制时延较大,如果当前线程是纯读取,也要看是否时延超过了容忍阈值,如果超过了则仍然需要强制从主库读取,这就是我们现在要介绍的dataSource层的方案了。

读写分离:通过实现dataSorce的connection以及statement,当jdbc请求执行sql时会首先获取connection,通过解析sql判断是查询还是更新来选择连接池的读写连接类型,同时需要结合主从复制检测的结果进行综合判断来实现读写连接分离。而读写的链接都是从读写的dataSorce中获取。
读写窗口一致性:通过重写dataSource的connection,如果当前连接已经存在写连接请求就强制采用写连接。
主从复制时延智能切换:通过启动单线程检测master与slave数据是否存在时延,来决策系统主从是否存在时延,如果存在时延强制系统本次执行主库查询。
我们看下connection里面几个重要方法的实现:
public PreparedStatement prepareStatement(String sql, int resultSetType,
int resultSetConcurrency) throws SQLException {
//通过sql解析是否是读请求,并且时延没有超过指定阈值,则请求读连接,否则取写连接
if (SqlUtil.isReadRequest(sql) && !datasource.getMdsm().isDelay()) {
return getReadConnection().prepareStatement(sql, resultSetType, resultSetConcurrency);
} else {
return getWriteConnection().prepareStatement(sql, resultSetType, resultSetConcurrency);
}
}而getReadConnection的方法逻辑如下:
Connection getReadConnection() throws SQLException {
if (writeConn != null) {
// 如果是读数据,并且已有写连接,那么强制返回这个写链接。
return writeConn;
}
if (readConn != null) {
return readConn;
} else {
readConn = datasource.getReadConnection(username, password);
}
return readConn;
}我们从开发者视角来阐述了基于DAO/JDBC以及dataSource的三个读写分离方案,各有优势,大家可以按需自行选择对应方案在业务中实现读写分离。