导读:索引(index)作为一种具备各种优势的数据结构,被大量应用在数据检索领域。其中倒排索引数据结构在搜索引擎框架中扮演着非常重要的角色。SEO顾问——潇湘驭文为您简单介绍倒排索引与正向索引。
对没有编程和操作数据库经验的站长和SEOer而言,索引是一种比较抽象的概念。感兴趣的朋友可以参考百度百科中的索引。在此,我们只需把索引理解成一本书中的目录。对,索引就像目录一样,可以帮助我们快速检索想要的信息。
什么是正向索引
索引的应用领域很广,包括但不限于:doc、pdf、excel、html等。具体到搜索引擎对网页(html)的索引,正向索引是网页与关键词一一对应的数据结构。
为简单起见,我们假设有网页1和网页2:
网页1中仅包含一句话:厦门SEO顾问潇湘驭文为您提供厦门SEO培训服务。
网页2中也仅包含一句话:SEO是一门艺术。
经过搜索引擎初步分词之后,网页1和2的正向索引如下图所示:
正向索引
假设使用正向索引,那么当你搜索SEO的时候,搜索引擎必须检索网页中的每一个关键词,假设一个网页中包含成千上百个关键词,可想而知,会造成大量的资源浪费。于是倒排索引应运而生。
什么是倒排索引
倒排索引是相对正向索引而言的,你也可以将其理解为逆向索引。它是一种关键词与网页一一对应的数据结构。如下图所示:

倒排索引
从上图可以一目了然,倒排索引可以直接参与排名。
比如你搜索“SEO”,搜索引擎可以快速检索出包含“SEO”搜索词的网页1和网页2,为后续的相关度和权重计算奠定基础,从而大大加快了返回搜索结果的速度。

以上是最简单的倒排索引示意图,实际上,倒排索引数据结构还记录了关键词出现的位置(标题、描述、正文第几段)、关键词出现的频率(关键词密度)、关键词是否被特殊标签包含等信息。后续潇湘驭文将会着重讲解。
问题描述
倒排索引是搜索引擎的基础算法,在本文中我们以一个简单的例子来详细介绍倒排索引的思想和实现。
假设用户有个搜索query:“林俊杰2019演唱会行程”。百度的搜索结果如下:
如果要求你来设计一个搜索引擎,来解决这个问题,你会如何着手呢?
问题简化
现在我们把这个问题具体化。我们除了有要查询的query:“林俊杰2019演唱会行程”。还有被查询的网页数据库。这里我们做个简化,假设我们的网页数据库内容只有如下4条:
网页1:
2019年,JJ林俊杰全球演唱会在北京首场演出,行程如下xxxxxxx;网页2:
林俊杰,吴亦凡终于同框合影 ,惹粉丝们尖叫连连,xxxxx;网页3:
蔡依林2019世界演唱会行程全曝光,xxxxx;网页4:
告别2018,迎接崭新的2019,xxxxxx;简单来说,就是从网页1~4中选取最理想的查询结果。你会怎么做呢?
关键词匹配
最容易想到的方法就是关键词匹配了,简单的来说,就是网页中包含查询的关键词越多,网页和查询query的相关度也就越大。
在做关键词查询前,一般文本会先进行预处理。这里的预处理主要包括去停用词和分词。
去停用词
去除和查询不相关的内容,比如本例子中的标点符号。在其他场景中,除了标点符号也会去除一些特别的字或词。
分词
分词主要目的是将句子切长短语或关键字,这样才利于查询匹配。比如“林俊杰2019演唱会行程”可以分词成,
林俊杰/2019/演唱会/行程当然网页也需要这样进行分词:
网页1:
2019/年/JJ/林俊杰/全球/演唱会/在/北京/首场/演出/行程/如下/xxxxxxx网页2:
林俊杰/吴亦凡/终于/同框/合影 /惹/粉丝们/尖叫/连连/xxxxx网页3:
蔡依林/2019/世界/演唱会/行程/全曝光/xxxxx网页4:
告别/2018/迎接/崭新/的/2019/xxxxxx;分词是一项专门的技术,在实际工程中可以至今借助工具来完成,比如jieba分词。
分词处理后,我们用查询query中的关键词在网页数据库中进行关键词匹配,并统计匹配数目:

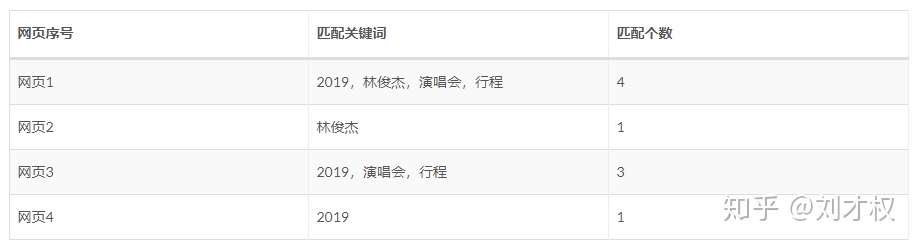
从“匹配个数”中很容易确定,网页1就是和查询query最匹配的网页。
倒排索引
讲到这里大家可能会疑问,这和倒排索引有什么关系?实际上,如果仔细考虑上面的关键词查询过程,会发现这种方法有个很大的效率问题:我们的例子中只有4个待查询的网页,而实际的互联网世界的网页数目是非常巨大的。假设互联网世界的网页数据为N,那么使用关键词查询的时间复杂度就是O(N),显然,这样的时间复杂度还是太大了,而倒排索引就很好的优化了这个问题。
从倒排索引这个名字很容易联想出它的实现,关键就是“倒排”的“索引”。在前面的讲解中,我们的索引(key)是网页,内容(value)是关键字。倒排索引就是反过来:内容关键字作为索引(key),所在网页作为内容(value)。前面的表格就可以改写成,

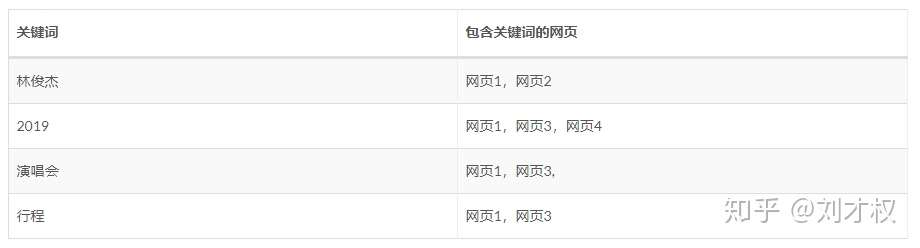
通过上面的表格,很明显网页1是包含最多关键词的网页,也是和查询query相关度最高的网页。采用倒排索引的方法,搜索的时间复杂度得到了明显的降低。
链接:https://www.zhihu.com/question/23202010/answer/586211738