作者:天山老妖S
链接:http://blog.51cto.com/9291927
一、字符集与编码
1、字符集简介
字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符集(Character
set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、
GB18030字符集、Unicode字符集等。计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
字符编码(Character encoding)是把字符集中的某个字符编码为指定字符集中字符,以便文本在计算机中存储和通过通信网络的传递。常见的例子包括将拉丁字母表编码成ASCII,ASCII将字母、数字和其它符号编号,并用7比特的二进制来表示。
字符序(collation)是指同一个字符集内字符之间的比较规则。只有确定字符序后,才能在一个字符集上定义什么是等价的字符,以及字符之间的大小关系。一个字符可以包含多种字符序。MySQL字符序命名规则是:以字符序对应的字符集名称开头,以国家名居中(或以general居中),以ci、cs、或bin结尾。以ci结尾的字符序表示大小写不敏感,以cs结尾的字符序表示大小写敏感,以bin结尾的字符序表示按二进制编码值比较。
2、ASCII编码
ASCII既是编码字符集,又是字符编码,ASCII直接将字符在编码字符集中的序号作为字符在计算机中存储从数值。
例如:在ASCII中A字符在表中排第65位,序号是65,而编码后A的数值是0100 0001,即十进制的65的二进制转换结果。
3、Latin1字符集
Latin1字符集在ASCII字符集基础上进行了扩展,仍然使用一个字节表示字符,但启用了高位,扩展了字符集的表示范围。
4、UTF-8编码
UTF-8(8-bit
Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。由Ken
Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码Unicode字符。
UTF-8是一种变长字节编码方式。对于某一个字符的UTF-8编码,如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的位数,其余各字节均以10开头。UTF-8最多可用到6个字节。 如表:
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
因此UTF-8中可以用来表示字符编码的实际位数最多有31位,即上表中x所表示的位。除去控制位(每字节开头的10等),x表示的位与UNICODE编码是一一对应的,位高低顺序也相同。
实际将UNICODE转换为UTF-8编码时应先去除高位0,然后根据所剩编码的位数决定所需最小的UTF-8编码位数。 因此基本ASCII字符集中的字符(UNICODE兼容ASCII)只需要一个字节的UTF-8编码(7个二进制位)便可以表示。
5、字符集兼容性
查看任意字符的指定编码方式的编码:
select hex(convert('string' using code));
查看编码值在字符集中的字符:
select convert(0xABCDXXX using charsetname);
ASCII编码实例:
select hex(convert('hello' using ascii));
字符串“hello”的ASCII编码:0x68656C6C6F
Latin1编码实例:
select hex(convert('hello' using latin1));
字符串“hello”的Latin1编码:0x68656C6C6F
UTF-8编码实例:
select hex(convert('hello' using utf8));
字符串“hello”的UTF-8编码:0x68656C6C6F
GBK编码实例:
select hex(convert('hello' using gbk));
字符串“hello”的GBK编码:0x68656C6C6F
GB2312编码实例:
select hex(convert('hello' using gb2312));
字符串“hello”的GB2312编码:0x68656C6C6F
BIG5编码实例:
select hex(convert('hello' using big5));
字符串“hello”的BIG5编码:0x68656C6C6F
从以上实例可以看出,Latin1字符集兼容ASCII字符集;UTF-8、GBK、GB2312、BIG5字符集都兼容Latin1字符集。
中文“很屌”的UTF-8编码实例:
select hex(convert('很屌' using utf8));
“很屌”的UTF-8编码:0xE5BE88E5B18C
select CONVERT(0xE5BE88E5B18C USING utf8);
将“很屌”字符的UTF-8编码值0xE5BE88E5B18C转换为UTF-8中的字符
中文“很屌”的GBK编码实例:
select hex(convert('很屌' using gbk));
“很屌”的GBK编码:0xBADC8CC5
select CONVERT(0xBADC8CC5 USING gbk);
将“很屌”字符的GBK编码值0xBADC8CC5 转换为GBK中的字符
中文“很屌”的GB2312编码实例:
select hex(convert('很屌' using gb2312));
“很屌”的GB2312编码:0xBADC3F
select CONVERT(0xBADC3F USING gbk);
将“很屌”字符的GB2312编码值0xBADC3F转换为GBK中的字符,结果为“很?”,字符“屌”在GB2312字符集中不存在。
中文“很屌”的BIG5编码实例:
select hex(convert('很屌' using big5));
“很屌”的BIG5编码:0xABDCCE78
中文“很屌”的Latin1编码实例:
select hex(convert('很屌' using latin1));
“很屌”的Latin1编码:0x3F3F
中文“很屌”的ASCII编码实例:
select hex(convert('很屌' using ascii));
“很屌”的ASCII编码:0x3F3F
从以上实例可以看出,对于中文字符来说,UTF-8、GBK、GB2312、BIG5四种编码之间是互不兼容的,直接相互转换会导致乱码;当UTF-8、GBK、GB2312、BIG5四种编码转换为ASCII编码和Latin1编码格式时,每个中文字符会被转换为0x3F,即中文字符’?’。
GB2312支持简体中文,BIG5支持繁体中文,GBK支持简体中文及繁体中文,UTF-8支持几乎所有字符。
GBK是国家标准GB2312基础上扩容后兼容GB2312的标准。GB2312是GBK的子集,GBK是GB18030的子集。
二、MySQL字符集
1、MySQL环境变量
Session会话变量:
使用show variables like '%char%';可以查看Session会话的字符集变量: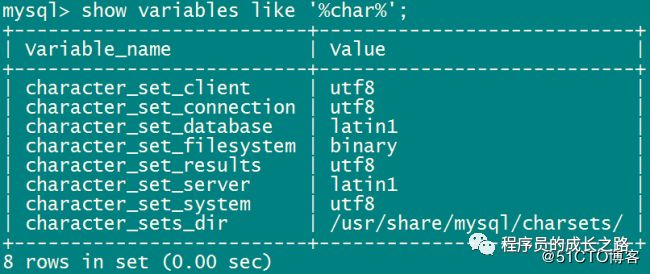
set character_set_server=utf8;
set character_set_database=utf8;
使用SET可以设置不同字符集。但是使用SET设置的字符集都是Session会话级别的,如果新打开一个会话,新会话使用的是默认的字符集。
Global全局变量:
使用show global variables like '%char%';可以查看Global的字符集变量: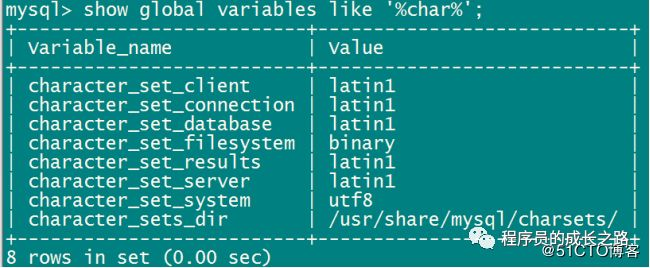
set global character_set_database=utf8;
set global character_set_server=utf8;
使用SET GLOBAL可以设置多个会话的字符集。
使用show charset;查看MySQL支持的字符集和对应字符集的字符序。
MySQL服务重启后,Global的值会被重置为默认值。永久修改Global的值的方法如下:
修改mysql配置文件/etc/my.cnf。
[mysqld]
character-set-server=utf8
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
2、MySQL字符集
MySQL服务器可以支持多种字符集,提供了不同级别的设置,包括server级、database级、table级、column级。
MySQL数据库的环境变量查看使用SQL语句show variables like '%char%';
character_set_client:客户端使用的字符集,当客户端向服务器发送请求时,请求以客户端字符集进行编码。
character_set_connection :客户端/数据库建立的通信连接使用的字符集,MySQL服务器接收客户端的查询请求后,将其转换为character_set_connection变量指定的字符集。
character_set_database:数据库服务器中某个数据库的字符集,如果没有默认数据库字符集,使用 character_set_server指定的字符集。
character_set_results:数据库给客户端返回时的字符集,MySQL数据库把结果集和错误信息转换为character_set_results指定的字符集,并发送给客户端。
character_set_server:数据库服务器的字符集,内部操作字符集。
character_set_system:系统元数据(字段名等)使用的字符集
当客户端连接服务器的时候,客户端会将自己想要的字符集名称发给MySQL服务端,然后服务端就会使用字符集去设置character_set_connection、character_set_client、character_set_results。
创建数据库时如果不指定数据库的字符集,默认会使用character_set_server字符集。
创建表时如果不指定表的字符集,默认使用当前数据库字符集。
创建列时如果不指定字符集,默认使用当前表的字符集。
3、MySQL字符集的设置
A、MySQL服务器级字符集
修改MySQL服务器配置文件/etc/my.cnf文件。
[mysqld]
character_set_server=utf8
重启MySQL数据库服务生效。
B、MySQL数据库级字符集:
创建数据库时指定:
CREATE DATABASE db_name
[[DEFAULT] CHARACTER SET charset_name]
[[DEFAULT] COLLATE collation_name]
修改已有的数据库的字符集:
ALTER DATABASE db_name
[[DEFAULT] CHARACTER SET charset_name]
[[DEFAULT] COLLATE collation_name]
ALTER修改只对修改后在数据库上的操作有效。
C、MySQL表级字符集:
创建表时指定:
CREATE TABLE tbl_name (column_list)
[[DEFAULT] CHARACTER SET charset_name]
[COLLATE collation_name]]
修改表的字符集:
ALTER TABLE tbl_name
[[DEFAULT] CHARACTER SET charset_name]
[COLLATE collation_name]
D、MySQL字段级字符集:
修改已有字段的字符集:
ALTER TABLE table_name MODIFY
column_name {CHAR | VARCHAR | TEXT} (column_length)
[CHARACTER SET charset_name]
[COLLATE collation_name]
MySQL客户端设置:set names utf8;等价于:
set character_set_client=utf8;
set character_set_connection=utf8;
set character_set_results=utf8;
E、客户端字符集
修改MySQL服务器配置文件/etc/my.cnf文件。
[client]
default-character-set=utf8
等价于set names utf8;
会影响会话中的变量character_set_client,character_set_connection 和character_set_results的值。
修改后无需重启MySQL数据库服务即可生效。
4、MySQL字符集的转换过程
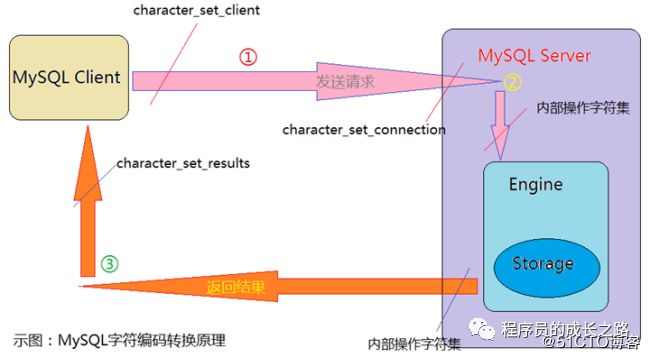
A、MySQL服务端收到请求时将请求数据从character_set_client字符集转换为character_set_connection字符集。
B、进行内部操作前将请求数据从character_set_connection字符集转换为内部操作字符集。确定步骤:
--使用每个数据字段的CHARACTER SET设定值;
--若上述值不存在,则使用对应数据表的DEFAULT CHARACTER SET设定值;
--若上述值不存在,则使用对应数据库的DEFAULT CHARACTER SET设定值;
--若上述值不存在,则使用character_set_server字符集设定值;
C、将操作结果从内部操作字符集转换为character_set_results字符集。
D、将character_set_results字符集的执行结果转换为character_set_client字符集,发送到客户端,客户端使用设置的字符集展示结果。
三、MySQL产生乱码的产生
1、MySQL乱码产生的原因
乱码产生的原因如下:
A、存入和取出时对应环节的编码不一致。
B、如果两个字符集之间无法进行无损编码转换,一定会出现乱码。
2、编码无损转换
如果一个使用编码A表示的字符X,转化为编码B的表示形式,而编码B的字符集中并没有X字符,则编码转换是有损的,否则编码转换就是无损的。
由于每个字符集所支持的字符数量是有限的,并且各个字符集涵盖的字符之间存在差异。将UTF-8字符转换为GBK字符时,MySQL内部如果无法在GBK字符集找到一个UTF8字符集中的字符时,就会转换成一个错误标记(0x3F,问号)。
编码无损转换的条件:
A、被转换的字符是否同时在两个字符集中。
B、目标字符集是否能够对不支持字符,保留其原有表达形式。
喜欢的小伙伴们可以搜索我们个人的微信公众号“程序员的成长之路”点击关注或扫描下方二维码
