3.查找和排序
一、冒泡排序
public static void bubbleSort(int[] arr) {
for(int tianHuaBan = arr.length - 1; tianHuaBan>= 0; tianHuaBan--) {
for (int i = 0; i < tianHuaBan; i++) {
if (arr[i] > arr[i + 1]) {//如果当前位置更大
int temp = arr[i];
arr[i]= arr[1 + i];
arr[1 + i] = temp;
}
}
}
}
二、选择排序
static void swap(int a[],int b,int c){
int t=a[b];
a[b]=a[c];
a[c]=t;
}
public static void selectSort(int[] arr) {
/*这一层好比控制天花板*/
for (int tianHuaBan = arr.length - 1; tianHuaBan >= 0; tianHuaBan--) {
//在天花板范围内选一一个最大的
int index0fMax = 0;
int max = arr[0];
for (int i = 0; i <= tianHuaBan; i++) {
if (arr[i] > max) {//如果当前位置更大
index0fMax = i;
max = arr[i];
}
}//内层for循环完成之后, 天花板范围内的最大值及其下标就确定了
swap(arr, index0fMax, tianHuaBan);
}
}
三、插入排序
public static void insertSort(int[] arr) {
//好比摸牌,从上到下一张- -张去摸
for (int i =0; i < arr.length; i++) {
//这张牌的点数是arr[i]
//手上的牌0~i-1
int lastIndex = i-1;//原有手牌最后那张的位置
int v=arr[i];//新手牌
while(lastIndex > -1 && v < arr[lastIndex]){
arr[lastIndex + 1] = arr[lastIndex];//往后挪
lastIndex--;//更新最后-张待比较的手牌
}
//lastIndex=- 1或者v更大了
//新手牌放到合适的位置
arr[lastIndex + 1] = v;
}
}
四、希尔排序
分组插入排序,最开始以间隔为长度一半分组,每组插入排序,然后间隔再一半再分组,直到间隔为1,
里面的插入相当于把普通插入排序1改成间隔,但是第二个for里面不改,是i++
不是把每个组拿出来,往自己组做插入排序
5往9插,4往8插,3往7插,2往6插,1往5和9插,来实现每间隔组插入排序
static void shellSort(int[] arr){
//不断地缩小增量
for(int interval=arr.length/2;interval>0;interval=interval/2){
//增量为interval的插入排序
for(int i=interval;i<arr.length;i++){
int x=arr[i];//起始元素i=4 value=5 x为将要插入的元素
int in=i-interval;//i=0 value=9 前面已经排好序元素最后一个
while(in>-1&&arr[in]>x){//元素依次往后移,留出合适位置
arr[in+interval]=arr[in];
in-=interval;
}
arr[in+interval]=x;
}
}
}
============
int[] a=new int[]{9,8,7,6,5,4,3,2,1};
shellSort(a);
System.out.println(Arrays.toString(a));
============
[1, 2, 3, 4, 5, 6, 7, 8, 9]
- 如果原始数据的大部分元素已经排序,那么插入排序的速度很快(因为需要移动的元素很少)
- 为什么“快"
- 无序的时候,元素少
- 元秦多的时候,已经基本有序
分治法
- 分治法(divide and conquer,D&C) :将原问题划分成若干个规模较小而结构与原问题一致的子问题;递归地解决这些子问题然后再合并其结果,就得到原问题的解。
- 容易确定运行时间,是分治算法的优点之一。
- 分治模式在每一层递归上都有三个步骤
- 分解(Divide) :将原问题分解成一系列子问题;
- 解决(Conquer) :递归地解各子问题。若子问题足够小,则直接有解;
- 合并(Combine):将子问题的结果合并成原问题的解。
分治的关键点
- 原问题可以一直分解为形式相同子问题,当子问题规模较小时,可自然求解,如一-个元素本身有序
- 子问题的解通过合并可以得到原问题的解
- 子问题的分解以及解的合并一定是比较简单的,则分解和合并所花的时间可能超出暴力解法,得不偿失
快速排序重点在划分
归并排序重点在合并
五、快速排序
-
分解:数组A[p..r]被划分为两个子数组A[p. .q-1]和A[q+1,r],使得A[q]为大小居中的数,左侧A[p. .q-1]中的每个元素都小于等于它,而右侧A[q+1,r]中的每个元素都大于等于它。其中计算下标q也是划分过程的一部分。
-
解决:通过递归调用快速排序,对子数组A[p. .q-1]和A[q+1,r]进行排序
-
合并:因为子数组都是原址排序的,所以不需要合并,数组A[p. .r]已经有序
那么,划分就是问题的关键
快排的划分算法
1.一遍单向扫描法:
- 一遍扫描法的思路是,用两个指针将数组划分为三个区间
- 扫描指针(scan_pos)左边是确认小于等于主元的
- 扫描指针到某个指针(next_bigger_pos)中间为未知的,因此我们将第二个指针(next_bigger_pos) 称为未知区间末指针,末指针的右边区间为确认大于主元的元素
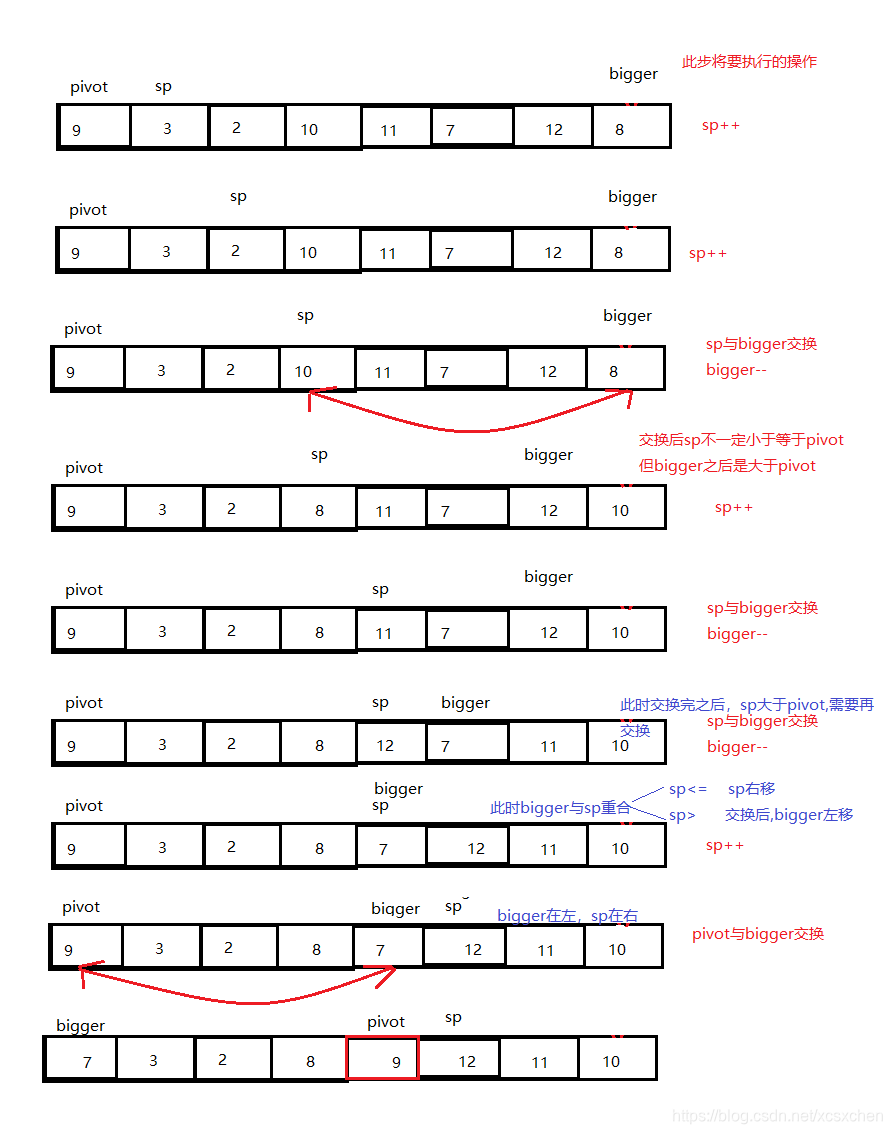
2.双向扫描法
双向扫描的思路是,头尾指针往中间扫3描,从左找到大于主元的元素,从右找到小于等于主元的元素二者交换,继续扫描,直到左侧无大元素,右侧无小元素
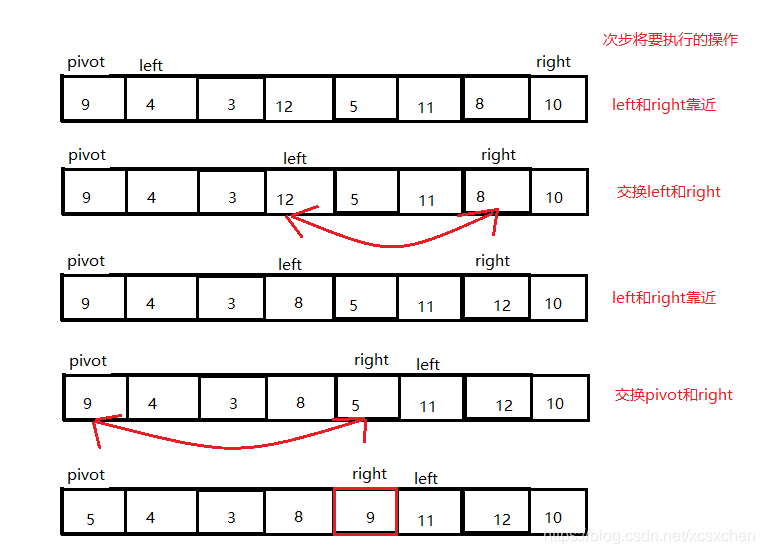
3.严蔚敏教材交换法
附设两个指针low和high,它们的初值分别为low和high,设枢轴记录的关键字为pivotkey,则首先从high所指位置起向前搜索找到第一个关键字小于pivotkey的记录和枢轴记录互相交换,然后从low所指位置起向后搜索,找到第一个关键字大于pivotkey的记录和枢轴记录互相交换,重复这两步直至low=high为止。
4. 严蔚敏教材赋值法
具体实现上述算法时,每交换一对记录需进行3次记录移动(赋值)的操作。而实际上,在排序过程中对枢轴记录的赋值是多余的,因为只有在一趟排序结束时,即low=high的位置才是枢轴记录的最后位置。由此可改写上述算法,先将枢轴记录暂存在r[0]的位置上,排序过程中只作r[Iow]或r[high]的单向移动,直至一趟排序结束后再将枢轴记录移至正确位置上。
import java.util.Arrays;
public class _快排一遍单向扫描法 {
public static int[] getRandomArr(int length, int min, int max) {
int[] arr = new int[length];
for (int i = 0; i < length; i++) {
arr[i] = (int) (Math.random() * (max + 1 - min) + min);
}
return arr;
}
static void swap(int a[],int b,int c){
int t=a[b];
a[b]=a[c];
a[c]=t;
}
static void QuickSort(int a[],int p,int q){
if(p<q){
int r=partition3(a,p,q);
QuickSort(a,p,r-1);
QuickSort(a,r+1,q);
}
}
static int partition(int a[],int p,int q){
int privot=p;
int sp=p+1;
int bigger=q;
while (sp<=bigger){
if(a[sp]<=a[p]){
sp++;
}else{
swap(a,sp,bigger);
bigger--;
}
}
swap(a,privot,bigger);
return bigger;
}
static int partition2(int a[],int p,int q){
int privot=p;
int left=p+1;
int right=q;
while(left<=right){
while(left<=right&&a[left]<=a[privot]) left++;
while(left<=right&&a[right]>a[privot]) right--;
if(left<right){
swap(a,right,left);
}
}
swap(a,privot,right);
return right;
}
static int partition3(int r[],int low,int high){
int pivot=r[low];//用子表的第一个记录作枢轴记录
while(low<high){//从表的两端交替地向中间扫描
//如果是第一个元素做枢轴,则先从high往前扫描,最后一个,则先从low往后扫描
while (low<high&&r[high]>=pivot){
high--;
}
swap(r,low,high);//将比枢轴记录小的记录交换到低端
while(low<high&&r[low]<=pivot){
low++;
}
swap(r,low,high);//将比枢轴记录大的记录交换到高端
}
return low;//返回枢轴所在位置
}
static int partition4(int r[],int low,int high){
int pivot=r[low];//因为r[low]后面要覆盖,先把他储存在pivot中
while(low<high){
while (low<high&&r[high]>=pivot){
high--;
}
r[low]=r[high];
while(low<high&&r[low]<=pivot){
low++;
}
r[high]=r[low];
}
r[low]=pivot;
return low;
}
public static void main(String[] args) {
int[] a=getRandomArr(100,0,100);
int[] b=a.clone();
Arrays.sort(b);
System.out.println(Arrays.toString(b));
QuickSort(a,0,a.length-1);
System.out.println(Arrays.toString(a));
}
}
工程实践中的其他优化
- 三点中值法
- 绝对中值法
- 待排序列表较短时,用插入排序
六、归并排序
- 归并排序(Merge Sort)算法完全依照了分治模式
- 分解:将n个元素分成各含n/2个元素的子序列;
- 解决:对两个子序列递归地排序;
- 合并:合并两个已排序的子序列以得到排序结果
- 和快排不同的是
- 归并的分解较为随意
- 重点是合并
import java.util.Arrays;
public class _归并排序 {
public static int[] getRandomArr(int length, int min, int max) {
int[] arr = new int[length];
for (int i = 0; i < length; i++) {
arr[i] = (int) (Math.random() * (max + 1 - min) + min);
}
return arr;
}
static void Merge(int[] SR,int[] TR,int i,int m,int n){
//将SR左右半有序。归并到TR
int k,j;//k为TR合并位置下标,i为左边最小元素下标,j为右边最小元素下标
for(k=i,j=m+1;i<=m&&j<=n;++k){
if(SR[i]<SR[j]){
TR[k]=SR[i++];
}else{
TR[k]=SR[j++];
}
}
while(i<=m){
TR[k++]=SR[i++];
}
while (j<=n){
TR[k++]=SR[j++];
}
}
static void MSort(int[] SR,int[] TR1,int s,int t){
//SR为拷贝,TR1为要排序数组
int TR2[]=new int[TR1.length];//TR2为拷贝的拷贝
if(s==t) {
TR1[s] = SR[s];
}else{
int m=(s+t)/2;//将SR[s..t]平分为SR[s..m]和SR[m+ 1..t]
MSort(SR,TR2,s,m);//递归地将SR[s..m]归并为有序的TR2[s..]
MSort(SR,TR2,m+1,t);// 递归地将SR[m+ 1.. t]归并为有序的TR2[m+ 1..t]
Merge(TR2,TR1,s,m,t);//将TR2[s.. m]和TR2[m+ 1.. t]归并到TR1[s..t]
}
}
static void MergeSort(int[] a){
int[] b=a.clone();//b为拷贝,a为原数组
MSort(b,a,0,a.length-1);
}
public static void main(String[] args) {
int[] a=getRandomArr(10000,0,1000);
int[] b=a.clone();
System.out.println();
Arrays.sort(b);
System.out.println(Arrays.toString(b));
MergeSort(a);
System.out.println(Arrays.toString(a));
boolean isSame=true;
for (int i = 0; i < a.length; i++) {
if(a[i]!=b[i]){
isSame=false;
break;
}
}
System.out.println(isSame);
}
}
题1:调整数组顺序使奇数位于偶数前面
输入一个整数数组,调整数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半部分。要求时间复杂度为O(n)
没有要求奇数偶数的顺序,类似快速排序的双向扫描,大于、小于,奇数、偶数 ,前半部分遇到偶数停下,后半部分遇到奇数停下来,交换前后
题2:第k个元素
以尽量高的效率求出一个乱序数组中按数值顺序的第K个元素值
利用快速排序的分区思想,执行完partition之后,左边元素小于q,右边大于q,q的位置为实际排序后的位置,如果它的序列为k,则p为所求元素,大于k,继续在左半部分查找,小于k,在右半部分查找
时间复杂度期望O(n),最差O(n²)
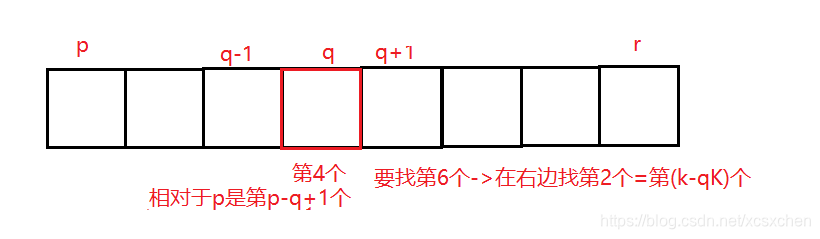
public class _第k个元素 {
static int selectK(int[] A,int p,int r,int k){//k为要找第k个
int q=_快速排序.partition2(A,p,r);
int qK=q-p+1;//在p~r中第几个
if(k==qK){
return A[q];
}else if(k<qK){//要找的小在左边找
return selectK(A,p,q-1,k);
}else{
return selectK(A,q+1,r,k-qK);
}
}
public static void main(String[] args) {
int[] A = {3, 9, 7, 6, 1, 2};
int k = selectK(A, 0, A.length - 1, 6);
System.out.println(k);
}
}
题3:超过一半的数字
数组中有一个数字出现的次数超过了数组长度的一半,找出这个数字。
解法一:排序后返回arr[N/2]
一个数字在数组中出现次数超过了一半,则排序后,位于数组中间的数字一定就是该出现次数超过了长度一半的数字(可以用反证法证明),也即是说,这个数字就是统计学上的中位数。最容易想到的办法是用快速排序对数组排序号后,直接取出中间的那个数字,这样的时间复杂度为O(nlogn),空间复杂度为O(1)。

static void solve1(int[] arr) {
Arrays.sort(arr);
System.out.println(arr[arr.length / 2]);
}
解法2:hash统计
解法3:顺序统计
利用题2的按数值顺序的第K个元素值,
O(N),限制:需要改动数组的内容
static int partition2(int a[],int p,int q){
int privot=p;
int left=p+1;
int right=q;
while(left<=right){
while(left<=right&&a[left]<=a[privot]) left++;
while(left<=right&&a[right]>a[privot]) right--;
if(left<right){
swap(a,right,left);
}
}
swap(a,privot,right);
return right;
}
public static int selectK(int[] A, int p, int r, int k) {
int q = partition2(A, p, r);//主元的下标
int qK = q - p + 1;//主元是第几个元素
if (qK == k) return A[q];
else if (qK > k) return selectK(A, p, q - 1, k);
else return selectK(A, q + 1, r, k - qK);
}
static void solve3(int[] arr) {
int res = selectK(arr, 0, arr.length - 1, arr.length / 2);
System.out.println(res);
}
解法4:不同的数,进行消除
由于该数字的出现次数比所有其他数字出现次数的和还要多,因此可以考虑在遍历数组时保存两个值:一个是数组中的一个数字,一个是次数,。当遍历到下一个数字时,如果下一个数字与之前保存的数字相同,则次数加1,如果不同,则次数减1,如果次数为0,则需要保存下一个数字,并把次数设定为1。由于我们要找的数字出现的次数比其他所有数字的出现次数之和还要大,则要找的数字肯定是组后一次把次数设为1时对应的数字。该方法的时间复杂度为O(n),空间复杂度为O(1)。
static int solve4(int[] arr) {
int candidate=arr[0];//先定第一个元素候选
int num=1;//出现次数
for (int i = 1; i < arr.length; i++) {//从第二个扫描数组
if(num==0){//前面的步骤相消,消为0了,把后面元素作为候选
candidate=arr[i];
num=1;
continue;
}
if(candidate==arr[i]){//遇到和候选值相同的,次数加1
num++;
}else {//不同的数,进行消减
num--;
}
}
return candidate;
}
题3扩展:寻找发帖“水王”
Tango是微软亚洲研究院的-一个试验项目。研究院的员工和实习生们都很喜欢在Tango上面交流灌水。传说,Tango 有一大“水王”,他不但喜欢发贴,还会回复其他ID发的每个帖子。坊间风闻该“水王”发帖数目超过了帖子总数的一半。如果你有一个当前论坛上所有帖子(包括回帖)的列表,其中帖子作者的ID也在表中,你能快速找出这个传说中的Tango水王吗?
解法同同上
水王增强
出现次数恰好为个数的一半,求出这个数
/*
* 关于加强版水王的题我有个想法可以扫描一遍数组就解决问题:
水王占总数的一半,说明总数必为偶数;
不失一般性,假设隔一个数就是水王的id,两两不同最后一定会消减为0
水王可能是最后一个元素,每次扫描的时候,多一个动作,和最后一个元素做比较,单独计数,计数恰好等于一半
如果不是,计数不足一半,那么去掉最后一个元素,水王就是留下的那个candidate*/
public static int solve5(int[] arr) {
int candidate = arr[0];
int nTimes = 0;
int countOfLast = 0;//统计最后这个元素出现的次数
int N = arr.length;
for (int i = 0; i < N; i++) {
//增加和最后一个元素比较的步骤
if (arr[i] == arr[N - 1])
countOfLast++;
if (nTimes == 0) {
candidate = arr[i];
nTimes = 1;
continue;
}
if (arr[i] == candidate)
nTimes++;
else
nTimes--;
}
//最后一个元素出现次数是n/2
if (countOfLast == N / 2)
return arr[N - 1];
else
return candidate;
}
题4:最小可用ID
在非负数组(乱序)中找到最小的可分配的id (从1开始编号),数据量1000000
// O(N²) 暴力解法:从1开始依次探测每个自然数是否在数组中
static int find1(int[] arr) {
int i = 1;
while (true) {
if (Util.indexOf(arr, i) == -1) {
return i;
}
i++;
}
}
// NlogN
static int find2(int[] arr) {
Arrays.sort(arr);//NlogN
int i = 0;
while (i < arr.length) {
if (i + 1 != arr[i]) { //不在位的最小的自然数
return i + 1;
}
i++;
}
return i + 1;
}
/**
* 改进1:
* 用辅助数组
*
*/
public static int find3(int[] arr) {
int n = arr.length;
int[] helper = new int[n + 1];
for (int i = 0; i < n; i++) {
if (arr[i] < n + 1)
helper[arr[i]] = 1;
}
for (int i = 1; i <= n; i++) {
if (helper[i] == 0) {
return i;
}
}
return n + 1;
}
/**
* 改进2,分区,递归
* 问题可转化为:n个正数的数组A,如果存在小于n的数不在数组中,必然存在大于n的数在数组中, 否则数组排列恰好为1到n
* @param arr
* @param l
* @param r
* @return
*/
public static int find4(int[] arr, int l, int r) {
if (l > r)
return l + 1;
int midIndex = l + ((r - l) >> 1);//中间下标
int q = Case02_OrderStatistic.selectK(arr, l, r, midIndex - l + 1);//实际在中间位置的值
int t = midIndex + 1;//期望值
if (q == t) {//左侧紧密
return find4(arr, midIndex + 1, r);
} else {//左侧稀疏
return find4(arr, l, midIndex - 1);
}
}
题5:合并有序数组
给定两个排序后的数组A和B,其中A的末端有足够的缓冲空间容纳B。编写一个方法,将B合并入A并排序
题6:逆序对个数
一个数列,如果左边的数大,右边的数小,则称这两个数位一个逆序对。求出一个数列中有多少个逆序对。
如果选左边第一个,说明左边第一个比右边第一个小,所以左边第一个比右半部都小,类似,如果选右边第一个,说明右边第一个比左边第一个小,所以右边第一个比左半部都小,此时产生逆序对,个数为左边剩余全部的个数 ,即mid - left + 1
public class _6MergeSort {
private static int[] helper;
public static void sort(int[] arr) {
helper = new int[arr.length];
sort(arr, 0, arr.length - 1);
}
/*
分成两段分别排序,然后再合并
*/
private static void sort(int[] A, int p, int r) {
if (p < r) {
int mid = p + ((r - p) >> 1);
sort(A, p, mid); //对左侧排序
sort(A, mid + 1, r);//对右侧排序
merge(A, p, mid, r);//合并
}
}
static int niXu = 0;//统计逆序对的个数
/**
*假设数组的两段分别有序,借助一个辅助数组来缓存原数组,用归并的思路将元素从辅助数组中拷贝回原数组
*@param A 原数组
*@param p 低位
*@param mid 中间位
*@param r 高位
**/
private static void merge(int[] A, int p, int mid, int r) {
//拷贝到辅助空间的相同位置
System.arraycopy(A, p, helper, p, r - p + 1);
//辅助数组的两个指针
int left = p, right = mid + 1;
//原始数组的指针
int current = p;
while (left <= mid && right <= r) {
if (helper[left] <= helper[right]) {
A[current++] = helper[left++];
} else { //右边小
A[current++] = helper[right++];
niXu += mid - left + 1;
}
}
// 这样做完后,左边指针可能没到头;右边的没到头也没关系,想想为什么?
while (left <= mid) {
A[current] = helper[left];
current++;
left++;
}
}
public static void main(String[] args) {
int[] arr = Util.getRandomArr(10, 1, 100);
Util.print(arr);
sort(arr);
Util.print(arr);
Assertions.assertThat(Util.checkOrdered(arr, true)).isTrue();
System.out.println("逆序对的个数:" + niXu);
}
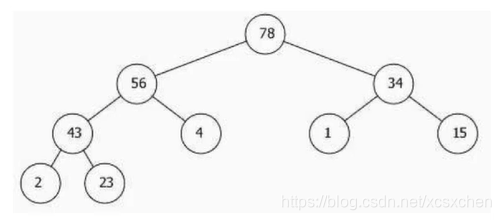
树、二叉树介绍
二叉树
根结点为0
左儿子 2i+1
右儿子 2i+2
父节点(i-1)/2
先序遍历:根左右
中序遍历:左根右
后序遍历:左右根
public class _二叉树三种遍历 {
static void PreOrder(int[] a,int i){
if(i>=a.length)
return;
System.out.print(a[i]+",");
PreOrder(a,2*i+1);
PreOrder(a,2*i+2);
}
static void InOrder(int[] a,int i){
if(i>=a.length)
return;
InOrder(a,2*i+1);
System.out.print(a[i]+",");
InOrder(a,2*i+2);
}
static void PostOrder(int[] a,int i){
if(i>=a.length)
return;
PostOrder(a,2*i+1);
PostOrder(a,2*i+2);
System.out.print(a[i]+",");
}
public static void main(String[] args) {
int a[]=new int[]{78,56,34,43,4,1,15,2,23};
PreOrder(a,0);
System.out.println();
InOrder(a,0);
System.out.println();
PostOrder(a,0);
}
}
78,56,43,2,23,4,34,1,15,
2,43,23,56,4,78,1,34,15,
2,23,43,4,56,1,15,34,78,
堆的概念
- 二叉堆是完全二叉树或者是近似完全二叉树。
- 二叉堆满足二个特性:
1.父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2.每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。 - 任意节点的值都大于其子节点的值—大顶堆
- 任意节点的值都小于其子节点的值—小顶堆
七、堆排序
使记录序列按关键字非递减有序排列,则在堆排序的算法中先建一个“大顶堆”,即先选得-个关键字为最大的记录并与序列中最后一个记录交换,然后对序列中前n-1记录进行筛选,重新将它调整为一一个“大顶堆”,如此反复直至排序结束。由此,“筛选"应沿关键字较大的孩子结点向下进行。
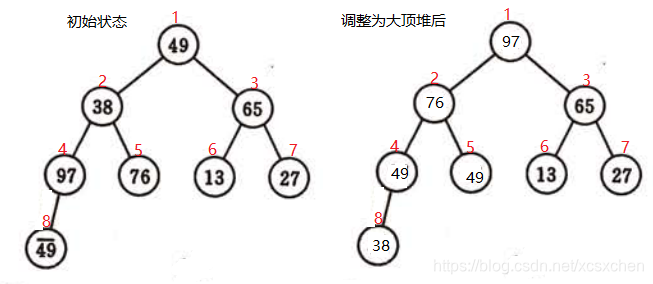
import java.util.Arrays;
public class _堆排序 {
static void HeapAdjust(int[] H,int s,int m){
// 已知s.. m中记录的关键字除H[s]之外均满足堆的定义,本函数调整H[s]的关键字,使H[s..m]成为一个大顶堆
int rc=H[s];//先把父亲节点值存到rc中
for (int j = 2*s; j <=m ; j*=2) {//j为s的左孩子,循环一次后,j*2,变成最大孩子的左孩子
if(j<m&&H[j]<H[j+1]){//如果右孩子大于左孩子,j++,j就为最大孩子的坐标
j++;
}
if(rc>=H[j]){//父元素已经是两个孩子中最大的了,则for循环退出
break;
}
H[s]=H[j];//把最大孩子的值赋值给父亲节点
s=j;//s保存当前最大孩子的下标
}
H[s]=rc;//把父亲值赋值给最后一次孩子下标
}
//递归调整
static void HeapAdjust2(int A[],int i,int n){//i为父节点,本函数使A[i..n]成为大顶堆
int left=2*i;
int right=2*i+1;
if(left>n){//左孩子已经越界返回
return;
}
int max=left;
if(right<=n&&A[right]>A[left]){
max=right;
}//max指向左右孩子中较大的那个
if(A[i]>=A[max]){//如果A[i]把;两个孩子都大,不同调整
return;
}
_快速排序.swap(A,max,i); //否则,找到两个孩子中较大的,和i交换
HeapAdjust2(A,max,n); //大孩子那个位置的值发生了变化,i变更为大孩子那个位置,递归调整
}
static void HeapSort(int[] H){
//H.length-1相当于H的length
for(int i=(H.length-1)/2;i>0;i--){//把H.r[1.. H.length]建成大顶堆
HeapAdjust2(H,i,H.length-1);//从(H.length-1)/2位最后一个父亲节点,依次往前调整
}
for (int i=H.length-1; i >1 ; i--) {
_快速排序.swap(H,1,i);//将堆顶(1)记录和当前未经排序子序列H[1.. i]中最后一个记录相互交换
HeapAdjust2(H,1,i-1);//将H[1..i-1]重新调整为大顶堆
}
}
public static void main(String[] args) {
//数组第一位预留,不参与排序
int a[] = new int[]{0, 49, 38, 65, 97, 76, 13, 27, 49};
HeapSort(a);
System.out.println(Arrays.toString(a));
}
}
八、计数排序
- 一句话:用辅助数组对数组中出现的数字计数,元素转下标,下标转元素
- 假设元素均大于等于0 ,依次扫描原数组,将元素值k记录在辅助数组的k位上
- 依次扫描辅助数组,如果为1 ,将其插入目标数组的空白处
- 问题
- 重复元素
- 有负数
思路:开辟新的空间,空间大小为max(source)扫描source,将value作为辅助空间的下标,用辅助空间的改位置元素记录value的个数如:9 7 5 3 1 ,helper=arr(10)一次扫描,value为9,将helper[9]++,value为7,将helper[7]++……如此这般之后,我们遍历helper,如果该位(index)的值为0,说明index不曾在source中出现如果该位(index)的值为1,说明index在source中出现了1次,为2自然是出现了2次,遍历helper就能将source修复为升序排列
时间复杂度: 扫描一次source,扫描一次helper,复杂度为N+k
空间复杂度:辅助空间k,k=maxOf(source)
非原址排序
稳定性:相同元素不会出现交叉,非原址都是拷来拷去
如果要优化一下空间,可以求minOf(source),helper的长度位max-min+1,这样能短点
计数有缺陷,数据较为密集或范围较小时,适用。
static void CountSort(int[] a) {
int max = a[0];
for (int e : a) {
if (e > max) {
max = e;
}
}
int[] helper = new int[max + 1];
for (int e : a) {
helper[e]++;
}
int current = 0;//数据回填的位置
for (int i = 1; i < helper.length; i++) {
while (helper[i] > 0) {
a[current++] = i;
helper[i]--;
}
}
}
九、桶排序
- 一句话:通过"分配”和"收集”过程来实现排序
- 思想是:设计k个桶( bucket) ( 编号0~k-1 ) ,然后将n个输入数分布到各个桶中去,对各个桶中的数进行排序,然后按照次序把各个桶中的元素列出来即可。
- 计数是不是有点桶的味道?
- 由于实现需要链表,我们再讲到链表的时候再回来写这个代码
十、基数排序
思路:是一种特殊的桶排序
初始化0-9号十个桶
一、按个位数字,将关键字入桶,入完后,依次遍历10个桶,按检出顺序回填到数组中,如
321 322 331 500 423 476 926
| 0 | 500 |
|---|---|
| 1 | 321 331 |
| 2 | 322 |
| 3 | 423 |
| 4 | 无 |
| 5 | 无 |
| 6 | 476 926 |
| 7 | 无 |
| 8 | 无 |
| 9 | 无 |
检出后数组序列为: 500 321 331 423 476 926,然后取十位数字重复过程一,得到
| 0 | 500 |
|---|---|
| 1 | 无 |
| 2 | 321 423 926 |
| 3 | 331 |
| 4 | 无 |
| 5 | 无 |
| 6 | 476 |
| 7 | 无 |
| 8 | 无 |
| 9 | 无 |
检出后数组序列为: 500 321 423 926 331 476,然后取百位数字重复过程一,得到
| 0 | 无 |
|---|---|
| 1 | 无 |
| 2 | 无 |
| 3 | 321 331 |
| 4 | 423 476 |
| 5 | 500 |
| 6 | 926 |
| 7 | |
| 8 | |
| 9 |
检出后数组序列为: 321 331 423 476 500 926,已然有序
但是我们应该继续入桶,不过因为再高位全部是0了,这些元素会按顺序全部进入0号桶,这时0号桶的size==数组的size,这时结束标志
最后再回填到数组,数组就是升序排列的了
时间复杂度: 假设最大的数有k位,就要进行k次入桶和回填,每次入桶和回填是线性的,所以整体复杂度为kN,
其中k为最大数的10进制位数
空间复杂度:桶是10个,10个桶里面存n个元素,这些空间都是额外开辟的,所以额外的空间是N+k,k是进制
肯定是非原址的了
稳定性:假设有相等的元素,它们会次第入桶,次第回数组,不会交叉,所以是稳定的
static void Distribute(int[] a,int i,ArrayList[] bucket) {
for (int j = 0; j <a.length ; j++) {
int temp =a[j] / (int) (Math.pow(10, i )) % 10;//取出a[j]的个位
bucket[temp].add(a[j]);//加入到相应的bucket
}
}
static void Collect(ArrayList[] bucket,int[] a){
int k = 0;
for (int i = 0; i <bucket.length; i++) {//每个桶中的元素依次压入原数组
for (Object m : bucket[i]) {
a[k++] = (Integer) m;
}
}
//记得清空
for (ArrayList b : bucket) {
b.clear();
}
}
static void RadixSort(int[] a){
int max=a[0];
for (int e:a) {
if(e>max){
max=e;
}
}
int dNum=1;//dNum为最大数的位数
while (max/10!=0){
dNum++;
max=max/10;
}
ArrayList[] bucket=new ArrayList[10];//在Java中只是建立数组,并没有初始化
for (int i = 0; i < bucket.length; i++) {
bucket[i] = new ArrayList();
}
for (int i = 0; i <dNum ; i++) {//按最低位优先依次,从个位数进行分配收集
Distribute(a,i,bucket);//把数组a元素,按个位分配到对用bucket中
Collect(bucket,a);//从bucket[0]-[9]收集到数组a中
}
}
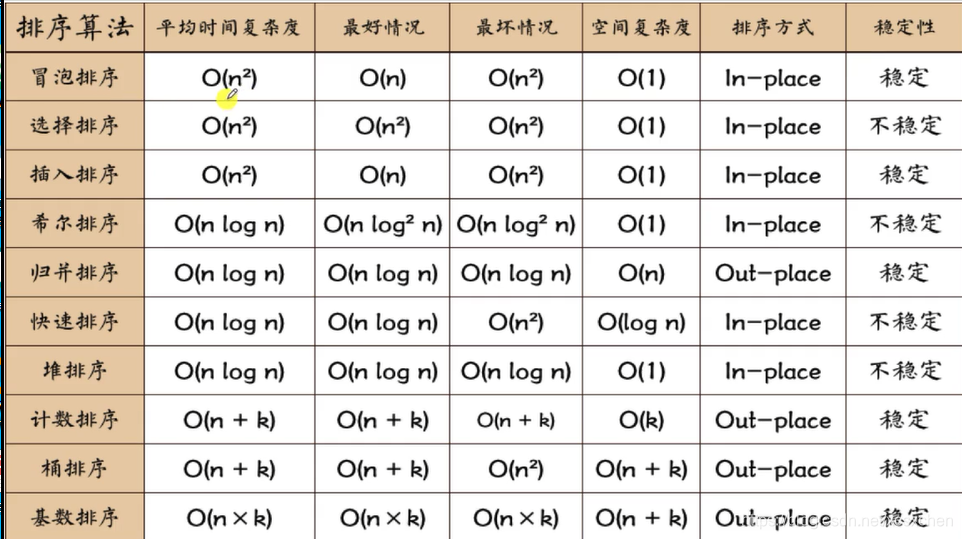
排序算法的总结:
基础排序
a.冒泡
谁大谁上,每一轮都把最大的顶到天花板
效率太低O(n²)——掌握swap
b.选择排序,效率较低,但经常用它内部的循环方式来找最大值和最小值——怎么一次性求出数组的最大值和最小值
O(n²)
c.插排,虽然平均效率低,但是在序列基本有序时,它很快,所以也有其适用范围
Arrays这个工具类在1.7里面做了较大改动
d.希尔(缩小增量排序),是插排的改良,对空间思维训练有帮助
分治法
1.子问题拆分
2.递归求解子问题
3.合并子问题的解
e.快排是软件工业中最常见的常规排序法,其双向指针扫描和分区算法是核心,
往往用于解决类似问题,特别地partition算法用来划分不同性质的元素,
partition->selectK,也用于著名的top问题
O(NlgN),但是如果主元不是中位数的话,特别地如果每次主元都在数组区间的一侧,复杂度将退化为N²
工业优化:三点取中法,绝对中值法,小数据量用插入排序
快排重视子问题拆分
f.归并排序,空间换时间——逆序对数
归并重视子问题的解的合并
g.堆排序,用到了二叉堆数据结构,是继续掌握树结构的起手式
=插排+二分查找
上面三个都是NlgN的复杂度,其中快排表现最好,是原址的不用开辟辅助空间;堆排也是原址的,但是常数因子较大,不具备优势。
上面7种都是基于比较的排序,可证明它们在元素随机顺序情况下最好是NlgN的,用决策树证明
下面三个是非比较排序,在特定情况下会比基于比较的排序要快:
1.计数排序,可以说是最快的:O(N+k),k=maxOf(sourceArr),
用它来解决问题时必须注意如果序列中的值分布非常广(最大值很大,元素分布很稀疏),
空间将会浪费很多
所以计数排序的适用范围是:序列的关键字比较集中,已知边界,且边界较小
2.桶排序:先分桶,再用其他排序方法对桶内元素排序,按桶的编号依次检出。(分配-收集)
用它解决问题必须注意序列的值是否均匀地分布在桶中。
如果不均匀,那么个别桶中的元素会远多于其他桶,桶内排序用比较排序,极端情况下,全部元素在一个桶内
还是会退化成NlgN
其时间复杂度是:时间复杂度: O(N+C),其中C=N(logN-logM),约等于NlgN
N是元素个数,M是桶的个数。
3.基数排序,kN级别(k是最大数的位数)是整数数值型排序里面又快又稳的,无论元素分布如何,
只开辟固定的辅助空间(10个桶)
对比桶排序,基数排序每次需要的桶的数量并不多。而且基数排序几乎不需要任何“比较”操作,而桶排序在桶相对较少的情况下,
桶内多个数据必须进行基于比较操作的排序。
因此,在实际应用中,对十进制整数来说,基数排序更好用。
期望水准:
1、准确描述算法过程
2、写出伪代码
3、能分析时间复杂度
4、能灵活应用(知道优缺点和应用场景)
在查找算法中,基于比较的查找算法最好的时间复杂度也是O(logN)。
比如折半查找、平衡二叉树、红黑树等。
但是Hash表却有O(C)线性级别的查找效率(不冲突情况下查找效率达到O(1))。
大家好好体会一下:Hash表的思想和桶排序是不是有异曲同工之妙呢?
题7 :排序数组中找和的因子
- 给定已排序数组arr和k ,不重复打印arr中所有相加和为k的不降序二元组
- 如输入arr={-8,-4,-3,0,2,4,5,8,9,10},k=10
- 输出(0,10)(2,8)
- 扩展:三元组呢?
题8:需要排序的子数组
给定一个整数数组,你需要寻找一个连续的子数组,如果对这个子数组进行升序排序,那么整个数组都会变为升序排序。
你找到的子数组应是最短的,请输出它的长度。
示例 1:
输入: [2, 6, 4, 8, 10, 9, 15]
输出: 5
解释: 你只需要对 [6, 4, 8, 10, 9] 进行升序排序,那么整个表都会变为升序排序。
说明 :
输入的数组长度范围在 [1, 10,000]。
输入的数组可能包含重复元素 ,所以升序的意思是<=。
public int findUnsortedSubarray(int[] nums) {
int[] a=nums.clone();
Arrays.sort(a);
int L=0,R=a.length-1;
while (L<a.length&&a[L]==nums[L]) L++;
while (R>0&&a[R]==nums[R]) R--;
if(L==a.length&&R==0) return 0;
return R-L+1;
}
public int[] findSegment(int[] A, int n) {
int p1 = -1;
int p2 = -1;
int max = A[0];
int min = A[n - 1];
//拓展右端点:更新历史最高,只要右侧出现比历史最高低的,就应该将右边界扩展到此处
for (int i = 0; i < n; i++) {
if (A[i] > max) {
max = A[i];
}
//只要低于历史高峰,就要扩展需排序区间的右端点
if (A[i] < max)
p2 = i;
}
//找左端点:更新历史最低,只要左侧出现比历史最低高的,就应该将左边界扩展到此处
for (int i = n - 1; i >= 0; i--) {
if (A[i] < min) {
min = A[i];
}
if (A[i] > min)
p1 = i;
}
if (p1 == -1) {
return new int[]{0, 0};
}
return new int[]{p1, p2};
}
{1, 4, 6, 5, 9, 10} [2, 3]
{1, 2, 3, 4, 5, 6} [0, 0]
{1, 5, 3, 4, 2, 6, 7}[1, 4]
{2, 3, 7, 5, 4, 6}[2, 5]
{3, 2, 5, 6, 7, 8}[0, 1]
{2, 8, 7, 10, 9}[1, 4]
{2, 3, 7, 4, 1, 5, 6}[0, 6]
题9 :前k个数
- 求求海量数据(正整数)按逆序排列的前k个数(topK),因为数据量太大,不能全部存储在内存中,只能一个一个地从磁盘或者网络上读取数据,请设计一个高效的算法来解决这个问题。 第一行用户输入K,代表要求得topK 随后的N(不限制)行,每一行是一个整数代表用户输入的数据 直到用户输入-1代表输入终止 请输出topK,空格分割。
- 思路:先开辟一个K大小的数组arr,然后读取K个数据存储到数组arr,读到K+1的时候,如果arr[K+1]小于arr中最小的值,那么就丢掉不管,如果arr[K+1]大于arr中最小的值,那么就把arr[K+1]和数组中最小的值进行交换,然后再读取K+2个数。这样就能解决这个问题。但是这个算法复杂度为K+(N-K)*K,K可以忽略不计,所以时间复杂度为O(KN)。那这个代码很容易就写出来。假如题目要求用到NlgK的时间复杂度,那么这里就需要使用堆这种数据结构来解决问题,而且还是小顶堆。具体思想还是和数组一样.
import java.util.Arrays;
import java.util.Scanner;
public class TopK {
static int[] heap;
static int index = 0;
static int k;
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
k = scanner.nextInt();
heap = new int[k];
int x = scanner.nextInt();
while(x!=-1){
deal(x); // 处理x
x = scanner.nextInt();
}
System.out.println(Arrays.toString(heap));
}
/**
* 如果数据量小于等于k,直接加入堆中
* 等于k的时候,进行堆化
* @param x
*/
private static void deal(int x) {
if (index<k) {
heap[index++] = x;
if (index==k) {
// 堆化
makeMinHeap(heap);
System.out.println(Arrays.toString(heap));
}
}else if (heap[0]<x) {
heap[0] = x;
MinHeapFixDown(heap, 0, k);
System.out.println(Arrays.toString(heap));
}else {
System.out.println(Arrays.toString(heap));
}
}
static void makeMinHeap(int[] A){
int n = A.length;
for(int i = n/2-1;i>=0;i--){
MinHeapFixDown(A,i,n);
}
}
private static void MinHeapFixDown(int[] A, int i, int n) {
// 找到左右孩子
int left = 2 * i + 1;
int right = 2 * i + 2 ;
// 左孩子已经越界,i就是叶子节点
if (left>=n) {
return ;
}
// min 指向了左右孩子中较小的那个
int min = left;
if (right>=n) {
min = left;
}else {
if (A[right]<A[left]) {
min = right;
}
}
// 如果A[i]比两个孩子都要小,不用调整
if (A[i]<=A[min]) {
return ;
}
// 否则,找到两个孩子中较小的,和i交换
int temp = A[i];
A[i] = A[min];
A[min] = temp;
// 小孩子那个位置的值发生了变化,i变更为小孩子那个位置,递归调整
MinHeapFixDown(A, min, n);
}
}
partition和堆都能解决顺序统计量问题,堆更适用于海量数据流
题10 :所有员工年龄排序
- 公司现在要对几万员工的年龄进行排序,因为公司员1工的人数非常多,所以要求排序算法的效率要非常高,你能写出这样的程序吗
- 输入:输入可能包含多个测试样例,对于每个测试案例,
- 输入的第一行为-一个整数n(1<= n<=1000000) :代表公司内员工的人数。
- 输入的第二行包括n个整数:代表公司内每个员工的年龄。其中,员工年龄age的取值范围为(1<=age<=99)。
- 输出:对应每个测试案例,
- 请输出排序后的n个员工的年龄,每个年龄后面有-一个空格。
采用计数排序,计数排序适用于数据范围小且已知
题11 :数组能排成的最小数(特殊排序)
-
输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。
示例 1:
输入: [10,2]
输出: "102"
示例 2:输入: [3,30,34,5,9]
输出: "3033459"提示:
0 < nums.length <= 100
说明:输出结果可能非常大,所以你需要返回一个字符串而不是整数
拼接起来的数字可能会有前导 0,最后结果不需要去掉前导 0public String minNumber(int[] nums) { Integer[] num=new Integer[nums.length]; for (int i = 0; i <nums.length ; i++) { num[i]=nums[i]; } Arrays.sort(num, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { String s1=o1+""+o2; String s2=o2+""+o1; return s1.compareTo(s2); } }); StringBuilder sb=new StringBuilder(); for (int i = 0; i < nums.length; i++) { sb.append(num[i]); } return sb.toString(); }
题12 :数组的包含
输入两个字符串str1和str2 ,请判断str1中的所有字符是否都存在与str2中
static boolean check(String s1,String s2){
char[] s2_arr=s2.toCharArray();
Arrays.sort(s2_arr);
for (int i = 0; i < s1.length(); i++) {
char a=s1.charAt(i);
if(Arrays.binarySearch(s2_arr,a)==-1){
return false;
}
}
return true;
}
什么时候用Java的类库?
有序时-Arrays.binarySearch二分查找
无序时Arrays.sort-原址 改变原数组