一、准备工作(找到所需网站,获取请求头,并用到请求头)
- 找到所需爬取的网站(这里举拉勾网的一些静态数据的获取)----------- https://www.lagou.com/zhaopin/Python/
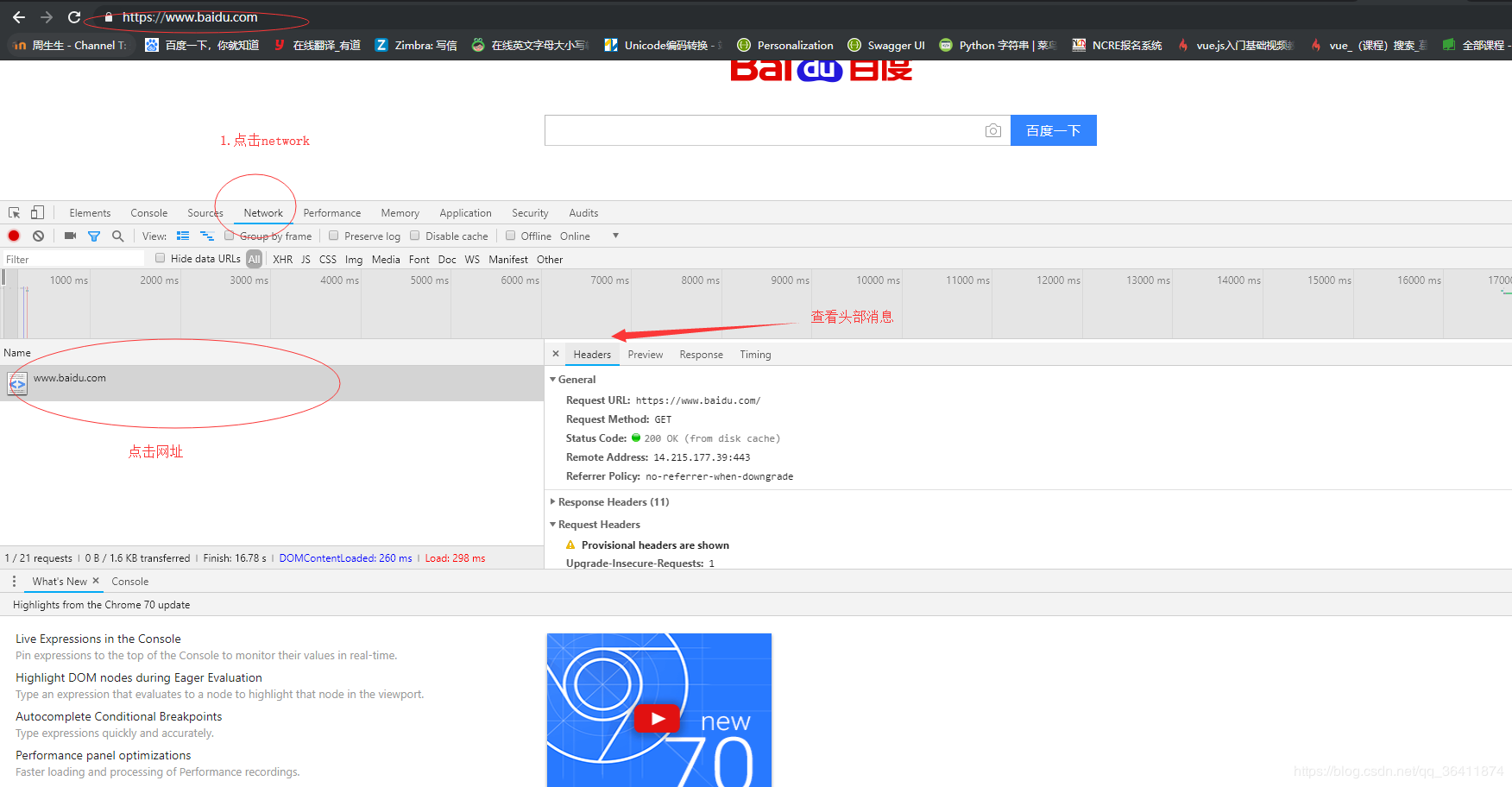
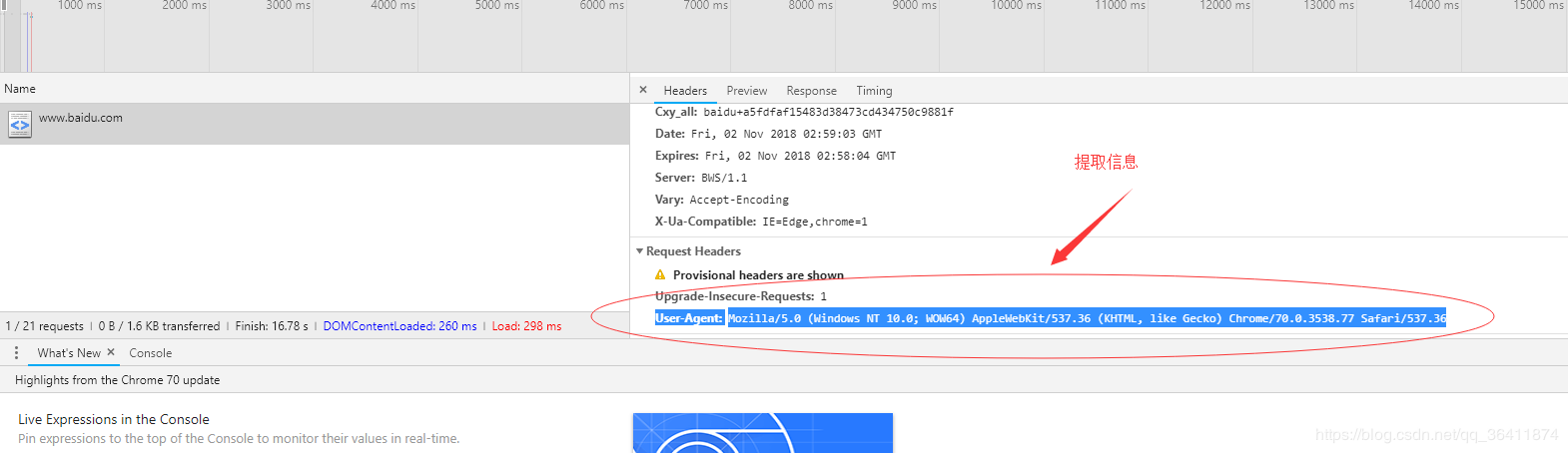
- 请求头的作用:模拟真实用户进入网站浏览数据-----------headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',}
- r=requests.get("https://www.lagou.com/zhaopin/Python/",headers=headers)-------------------这两行就是模拟用户进入网站
- 找到数据所在网页的标签(html网页右键源代码查看即可)

假设这里的15k-25k是我们要的数据,右键查看按箭头查看即可-----例如这里是span标签class=''money''(可以点击下面的控制台查看money是什么属性,有的是id=“money”这样的)------具体得看html代码
- 准备工作完毕
二、代码演示:(开始爬取)
2.1如果爬取的数据乱码,可以加入这三句话,定义输出格式
import io import sys sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
2.2爬取职位等相关信息(完整代码)
import requests import re import itertools from bs4 import BeautifulSoup import io import sys sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',}-------------请求头 r=requests.get("https://www.lagou.com/zhaopin/Python/",headers=headers)---------------请求该网页 r.encoding=r.apparent_encoding result=r.text------------------------------------------获取网页文档 bs=BeautifulSoup(result,'html.parser') # soup.find_all(string=re.compile('python')) li1=bs.find_all('h3')-------------------------------------------查找该页面所有h3标签 # len1=len(li1) # for i in li1:-----------------------------------------------用来测试输出的内容 # print(i.string) li2=bs.find_all('em') # len2=len(li2) # for i in li2:--------------------------------------------用来测试输出的内容 # print(i.string) li3=bs.find_all('span',class_="money") # len3=len(li3) # for i in li3: # print(i.string) li4=bs.find_all('div',class_="industry") # len4=len(li4) # for i in li4: # print(i.string) print("职位:".ljust(15),"地点:".center(15),"薪水:".center(15),"需求:".rjust(15)) print("------------------------------------------------------------------------------------------------") for li_1,li_2,li_3,li_4 in zip(li1,li2,li3,li4):--------------------------------------------------------------------------四个列表整合(每一行一个元素对应) print(li_1.string.ljust(15),li_2.string.center(15),li_3.string.center(15),li_4.string.rjust(15).strip())-------------strip()是用来去除字符串左右两边的空格(不然太长不好排版)
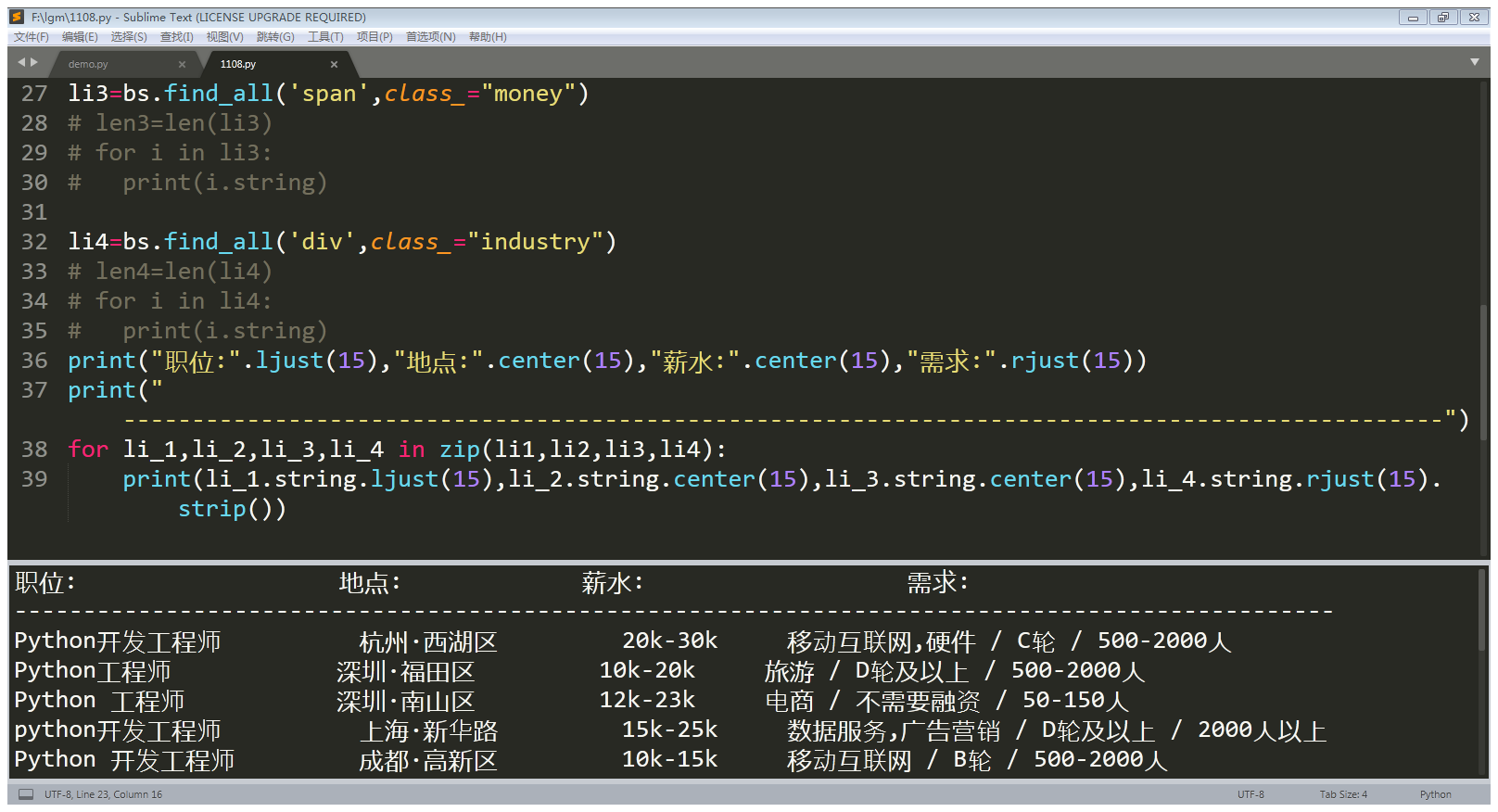
2.3运行结果
三、技术不是很难,但也很有用,不过这里得提醒一下(最好是将网页的html文档存放在本地,一直请求服务器是很不友好的行为哟!)
- 拓展:可以试着将数据存到txt文档或者excl表格中,更直观哟!