一、什么是POD
Pod是Kubernetes最重要的基本概念,我们看到每个Pod都有一个特殊的被称为“根容器”的Pause容器。Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器,每个Pod还包含一个或多个紧密相关的用户业务容器。
二、POD的生命周期
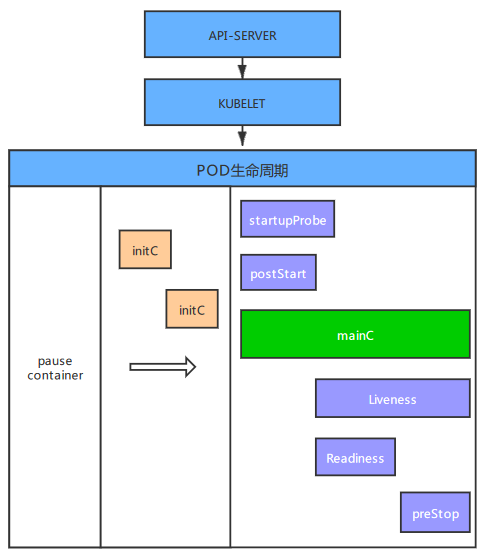
三、pause容器
用"kubernetes/pause"镜像为每个Pod都创建一个容器。该Pause容器用于接管Pod中所有其他容器的网络。每创建一个新的Pod,kubelet都会先创建一个Pause容器, 然后创建其他容器。"kubernetes/pause"镜像大概有270KB,是个非常小的容器镜像。
四、初始化容器initContainers
因为init容器具有与应用容器分离的单独镜像,所以它们启动相关代码有具有如下优势:
- 它们可以包含并运行实用工具,但是出去安全考虑,是不建议在应用程序容器镜像中包含这些实用工具的。
- 它们可以包含使用工具和定制化代码来安装,但是不能出现在应用程序镜像中。例如,创建镜像没必要FROM另一个镜像,只需要在安装过程中使用类似sed、awk、python或dig这样的工具。
- 应用程序镜像可以分离出创建和部署的角色,而没必要联合它们构建一个单独镜像。
- Init容器使用Linux namespace,所以相对应用程序容器来说具有不同的文件系统视图。因此,它能够访问secret的权限,而应用程序则不能。(分权限治理)
- 由于 Init 容器必须在应用容器启动之前运行完成,因此 Init 容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。一旦前置条件满足,Pod内的所有的应用容器会并行启动。
注意事项:
- 在Pod启动过程中,Init容器会按顺序在网络和数据卷初始化之后启动。每个容器必须在下一个容器启动之前成功退出。
- 如果由于运行时或失败退出,将导致容器启动失败,它会根据Pod的RestartPolicy指定的策略进行重试。如果是Never,它不会重新启动。
- 如果Pod重启,则Init容器会重启执行。
- init container不能设置readinessProbe探针,因为必须在它们成功运行后才能继续运行在Pod中定义的普通容器。
五、POD重启策略
当某个容器异常退出或者健康检查失败, kubelet将根据RestartPolicy的设置来进行相应的操作, 重启策略有Always , OnFailure, Never。
Always:Pod一旦终止运行,无论容器是如何终止的,kubelet都将重启它。
OnFailure:当容器终止运行非零退出时,由kubelet自动重启该容器。
Never:不论容器运行状态如何,kubelet都不会重启该容器。
六、imagePullPolicy镜像拉取策略
Always: 表示每次都尝试重新拉取镜像
IfNotPresent: 表示如果本地有镜像, 则使用本地的镜像, 本地不存在时拉取镜像
Never: 表示仅使用本地镜像
七、三种探针startupProbe、livenessProbe和readinessProbe
startupProbe探针:用于判断容器内应用程序是否已经启动,如果配置了startuprobe,优先于其它两种探测支行,直到它成功为止,成功后将不再进行startupProbe探测。
LivenessProbe探针:用于判断容器是否存活(Running状态),如果LivenessProbe探针探测到容器不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应的处理。
如果一个容器不包含LivenessProbe探针,那么kubelet认为该容器的LivenessProbe探针返回的值永远是Success。
ReadinessProbe探针:用于判断容器服务是否可用(Ready状态),达到Ready状态的Pod才可以接收请求。对于被Service管理的Pod,Service与Pod Endpoint的关联关系
也将基于Pod是否Ready进行设置。如果在运行过程中Ready状态变为False,则系统自动将其从Service的后端Endpoint列表中隔离出去,后续再把恢复到Ready状态的Pod加回
后端Endpoint列表。这样就能保证客户端在访问Service时不会被转发到服务不可用的Pod实例上。
包括三种探测方式:
- ExecAction:在容器内部执行一个命令,如果该命令的返回码为0,则表明容器健康。
livenessProbe: exec: command: ['test', '-e', '/tmp/live'] initialDelaySeconds: 1 # 启动容器后进行首次健康检查的等待时间 periodSeconds: 3 # 检测失败后重试时间
- TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表明容器健康。
readinessProbe: tcpSocket: port: 80 initialDelaySeconds: 5 # 启动容器后进行首次健康检查的等待时间 failureThreshold: 30 # 检测失败后重试时间 periodSeconds: 10 # 执行探测的间隔时间
- HTTPGetAction:通过容器的IP地址、 端口号及路径调用HTTP Get方法,如果响应的状态码大于等于200且小于400,则认为容器健康。
livenessProbe: httpGet: path: /index.html port: 80 initialDelaySeconds: 1 periodSeconds: 3
一些可选参数
timeoutSeconds:探测超时的秒数。默认为1秒。
initialDelaySeconds:启动容器后进行首次健康检查的等待时间,单位为s
periodSeconds:检测失败后重试时间3秒
failureThreshold:失败的容忍次数失败几次 判断为彻底失败,放弃检查并重启
successThreshold:失败后探测成功的最小成功次数。默认为1。最小值为1。
八、资源限制requests和limits
- Request工作原理
Request 的值并不代表给容器实际分配的资源大小,用于提供给调度器。调度器会检测每个节点可用于分配的资源(可分配资源减 request 之和),同时记录每个节点已经被分配的资源(节点上所有 Pod 中定义的容器 request 之和)。如发现节点剩余的可分配资源已小于当前需被调度的 Pod 的 request,则该 Pod 就不会被调度到此节点。反之,则会被调度到此节点。
- 避免 request 与 limit 值过大
若服务使用单副本或少量副本,且 request 及 limit 的值设置过大,使服务可分配到足够多的资源去支撑业务。则某个副本发生故障时,可能会给业务带来较大影响。当 Pod 所在节点发生故障时,由于 request 值过大,且集群内资源分配的较为碎片化,其余节点无足够可分配资源满足该 Pod 的 request,则该 Pod 无法实现漂移,无法自愈,会加重对业务的影响。
建议尽量减小 request 及 limit,通过增加副本的方式对服务支撑能力进行水平扩容,使系统更加灵活可靠。
resources: requests: cpu: 500m memory: 1024Mi limits: cpu: 1000m # 1000m=1核CPU memory: 2048Mi
九、command 容器的启动命令
创建 Pod 时,可以为其下的容器设置启动时要执行的命令及其参数。如果要设置命令,就填写在配置文件的 command 字段下,如果要设置命令的参数,就填写在配置文件的 args 字段下。一旦 Pod 创建完成,该命令及其参数就无法再进行更改了。参数会覆盖docker镜像中的启动命令。
# 用shell脚本的方式执行命令 command: ["/bin/sh"] args: ["-c", "while true; do echo hello; sleep 10;done"] # 或者只写一条---------------------------------------------- command: ["sh", "-c", "/startup.sh"] # 使用环境变量来设置参数 env: - name: MESSAGE value: "hello world" command: ["/bin/echo"] args: ["$(MESSAGE)"]
十、env环境变量
env: - name: MESSAGE value: "hello world" command: ["/bin/echo"] args: ["$(MESSAGE)"] env: - name: POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name
十一、POD的调度
在Kubernetes平台上, 我们很少会直接创建一个Pod, 在大多数情况下会通过RC、 Deployment、 DaemonSet、 Job等控制器完成对一组Pod副本的创建、 调度及全生命周期的自动控制任务。
- 11.1 Deployment或者ReplicaSet
主要功能之一就是自动部署一个容器应用的多份副本, 以及持续监控副本的数量, 在集群内始终维持用户指定的副本数量。
# cat nginx-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: mynginx image: nginx:1.18.0 ports: - containerPort: 80 resources: requests: cpu: 100m memory: 128Mi limits: cpu: 1000m memory: 1024Mi
- 11.2 NodeSelector:定向调度
NodeSelector通过标签的方式,简单实现了限制Pod所在节点的方法。
# kubectl label node k8s-node01 app=nginx # 为k8s-node01节点打上app=nginx的标签 # kubectl get node --show-labels |grep app=nginx k8s-node01 Ready <none> 13d v1.19.0 app=nginx,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,
kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux # cat nginx-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: nodeSelector: # 选择node标签为app=nginx的标签进行调度 app: nginx containers: - name: mynginx image: nginx:1.18.0 ports: - containerPort: 80 resources: requests: cpu: 100m memory: 128Mi limits: cpu: 1000m memory: 1024Mi # kubectl apply -f nginx-deployment.yaml # kubectl get pod -o wide # 所有的pod都调度到了k8s-node01节点上 NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-7cc69bccbc-ffn88 1/1 Running 0 45s 10.244.85.205 k8s-node01 <none> <none> nginx-deployment-7cc69bccbc-mmqgw 1/1 Running 0 42s 10.244.85.207 k8s-node01 <none> <none> nginx-deployment-7cc69bccbc-t45gg 1/1 Running 0 43s 10.244.85.206 k8s-node01 <none> <none>
- 11.3 NodeAffinity Node亲和性调度
是用于替换NodeSelector的全新调度策略。目前有两种节点亲和性表达。
RequiredDuringSchedulingIgnoredDuringExecution:必须满足指定的规则才可以调度Pod到Node上( 功能与nodeSelector很像,但是使用的是不同的语法),相当于硬限制。
PreferredDuringSchedulingIgnoredDuringExecution:强调优先满足指定规则,调度器会尝试调度Pod到Node上, 但并不强求,相当于软限制。多个优先级规则还可以设置权重(weight)值,以定义执行的先后顺序。
# 举例
apiVersion: v1 kind: Pod metadata: name: with-node-affinity spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: # 硬亲和性,要求pod在amd64节点上运行 nodeSelectorTerms: - matchExpressions: - key: beta.kubernetes.io/arch operator: In values: - amd64 preferredDuringSchedulingIgnoredDuringExecution: # 软亲和性,尽量运行在磁盘类型为ssd的节点上 - weight: 1 preference: matchExpressions: - key: disk-type operator: In values: - ssd containers: - name: with-node-affinity image: k8s.gcr.io/pause:2.0
NodeAffinity语法支持的操作符包括In、 NotIn、 Exists、 DoesNotExist、 Gt、 Lt。
NodeAffinity规则设置的注意事项如下:
如果同时定义了nodeSelector和nodeAffinity,那么必须两个条件都得到满足,Pod才能最终运行在指定的Node上。
如果nodeAffinity指定了多个nodeSelectorTerms,那么其中一个能够匹配成功即可。
如果在nodeSelectorTerms中有多个matchExpressions,则一个节点必须满足所有matchExpressions才能运行该Pod
- 11.4 PodAffinity POD亲和性
和节点亲和相同, Pod亲和与互斥的条件设置也是requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution。
# 举例pod亲和性,三个pod在运行在同一个k8s节点上 apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment namespace: default spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - nginx topologyKey: kubernetes.io/hostname # 同一个node为一个拓扑域 containers: - name: mynginx image: nginx:1.18.0 ports: - containerPort: 80 resources: requests: cpu: 500m memory: 1024Mi limits: cpu: 1000m memory: 2048Mi # 举例,pod反亲和性三个pod尽量运行在不同的k8s同节点上 apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment namespace: default spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - nginx topologyKey: kubernetes.io/hostname containers: - name: mynginx image: nginx:1.18.0 ports: - containerPort: 80 resources: requests: cpu: 500m memory: 1024Mi limits: cpu: 1000m memory: 2048Mi
十二、污点(Taint)与容忍(Toleration)
Taint需要和Toleration配合使用,让Pod避开那些不合适的Node。在Node上设置一个或多个Taint之后,除非Pod明确声明能够容忍这些污点, 否则无法在这些Node上运行。Toleration是Pod的属性, 让Pod能够(注意, 只是能够, 而非必须)运行在标注了Taint的Node上。
污点(Taint)
使用`kubectl taint `命令可以给革个Node节点设置污点,Node被设置上污点之后就和Pod之间存在一种相斥的关系,可以让Node拒绝Pod的高度执行,甚至将Node上已经存在的Pod驱逐出去。
# 每个污点的组成如下 key=vavlue:effect # 每个污点有一个key和value作为污点标签,其中value可以为空,effec描述污点的作用。当前tain effect支持以下三个选项: NoSchedule: 表示K8s不会将Pod调度到具有该污点的Node上 PreferNoSchedule:表示k8s将尽量避免将Pod调度到具有该污点的Node上 NoExecute:表示K8s将不会将Pod调度到具有该污点的Node上,同时会将Node上已经存在的Pod驱逐出去。
注:使用noexecute,k8s会直接杀死节点上的所有的pod,并在其它节点上面重新pod,如果业务都在这一个节点上业务可能会出现同时不可用的情况,建议使用for循环来杀pod。
例:for i in `kubectl get pod -n default -l app=nginx | awk {'print $1'}`; do kubectl delete pod $i -n default; done
命令设置
# 设置污点 kubectl taint node k8s-node01 key=value:NoSchedule # 查看污点 # kubectl describe node k8s-node01 | grep Taints Taints: key=value:NoSchedule # 移出污点 kubectl taint node k8s-node01 key=value:NoSchedule-
容忍(Tolerations)
设置了污点的Node将根据taint的effect:NoSchedule、PreferNoSchedule、NoExecute和Pod之间产生互斥的关系,pod将在一定程度上不会调度到Node上,但我们可以在Pod上设置容忍,意思是设置了容忍的Pod将可以容忍污点的存在,可以被调度到存在污点的Node上。
系统允许在同一个Node上设置多个Taint,也可以在Pod上设置多个Toleration。 Kubernetes调度器处理多个Taint和Toleration的逻辑顺序为: 首先列出节点中所有的Taint,然后忽略Pod的Toleration能够匹配的部分, 剩下的没有忽略的Taint就是对Pod的效果了。
一般来说, 如果给Node加上effect=NoExecute的Taint, 那么在该Node上正在运行的所有无对应Toleration的Pod都会被立刻驱逐, 而具有相应Toleration的Pod永远不会被驱逐。 不过, 系统允许给具有NoExecute效果的Toleration加入一个可选的tolerationSeconds字段, 这个设置表明Pod可以在Taint添加到Node之后还能在这个Node上运行多久(单位为s) :
# cat nginx19.yaml apiVersion: v1 kind: Pod metadata: name: pod-3 labels: app: pod-3 spec: containers: - name: pod-3 image: nginx:1.18.0 tolerations: - key: "key" # 要与Node上设置的taint保持一致 operator: "Equal" value: "value" # 要与Node上设置的taint保持一致 effect: "NoExecute" # 要与Node上设置的taint保持一致 tolerationSeconds: 3600
十三、固定节点调度nodeName
Pod.spec.nodeName将pod直接调度到指定的node节点上,会跳过schedule的调度策略,该匹配规则是强制匹配。
# cat nginx8.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 5 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: nodeName: k8s-node01 containers: - name: mynginx image: nginx:1.18.0 ports: - containerPort: 80 resources: requests: cpu: 100m memory: 128Mi limits: cpu: 1000m memory: 1024Mi