在使用JDBC查询数据库中数据时,返回的结果是ResultSet对象,使用十分不方便。Commons DbUtils组件提供了将ResultSet转化为Bean列表的方法,但是该方法在使用时需要根据不同的Bean对象创建不同的查询方法。本实例将在该方法的基础上使用泛型进行包装,使其通用性更强。
思路分析:
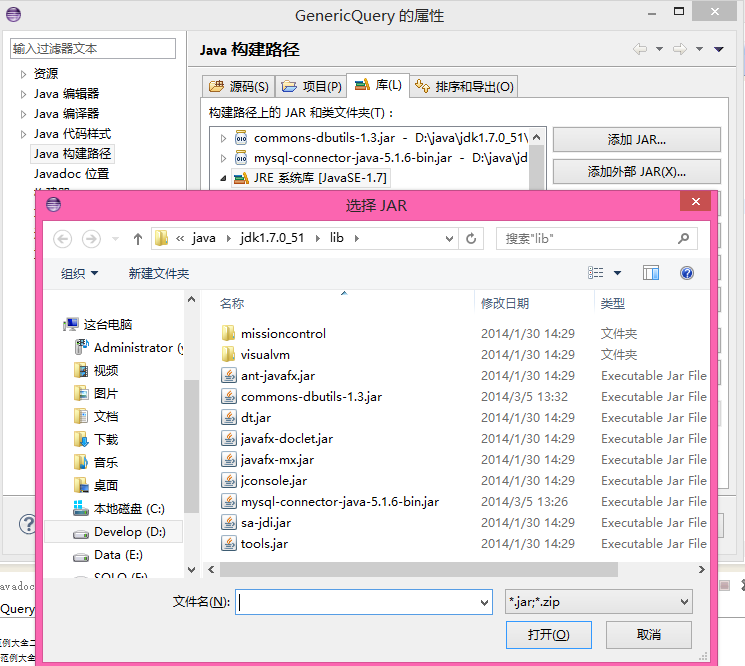
- 凡是要进行数据库操作的肯定都要额外导入包,比如mysql-connector-java-5.1.6-bin.jar与commons-dbutils-1.3.jar。我就很奇怪为毛JDK的默认包里不带这些呢。导入包的操作为在项目的“JRE系统库”选项上单击鼠标右键,选择构建路径——>配置构建路径——>添加外部JAR,如图所示:
- 从数据表里查询信息后,要想将查到的信息分别显示出来,就得根据数据表的结构来定义类了,一般来说,对于要显示的每个字段,都要在类中为其定义成员变量、get()方法与set()方法,代码如下:Books.java:
package cn.edu.xidian.crytoll; public class Books { private int id; private String name; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } @Override public String toString() { return id + ":" + name; } } - 接下来要编写数据库操作类,在该类中定义数据库进行连接、查询等操作的方法。因为是泛型查询,所以查询方法的返回值就是<T> List<T>类型的,参数嘛一个是SQL语句,一个就是上一步定义的类Class<T> type了,代码如下:GenericQuery.java:
package cn.edu.xidian.crytoll; import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; import java.util.List; import org.apache.commons.dbutils.DbUtils; import org.apache.commons.dbutils.QueryRunner; import org.apache.commons.dbutils.handlers.BeanListHandler; public class GenericQuery { private static String URL = "jdbc:mysql://localhost:3306/db_database13"; private static String DRIVER = "com.mysql.jdbc.Driver"; private static String USERNAME = "root"; private static String PASSWORD = "密码"; private static Connection conn; public static Connection getConnection() { DbUtils.loadDriver(DRIVER); try { conn = DriverManager.getConnection(URL, USERNAME, PASSWORD); } catch (SQLException e) { e.printStackTrace(); } return conn; } public static <T> List<T> query(String sql, Class<T> type) { QueryRunner qr = new QueryRunner(); List<T> list = null; try { list = qr.query(getConnection(), sql, new BeanListHandler<T>(type)); } catch (SQLException e) { e.printStackTrace(); } finally { DbUtils.closeQuietly(conn); } return list; } } - 最后就是编写主方法啦,在主方法中创建一个泛型对象,并调用上一步中的查询方法,然后使用foreach()循环将要查询的信息显示出来,代码如下:
GenericQueryTest.java:
package cn.edu.xidian.crytoll; import java.util.List; public class GenericQueryTest { public static void main(String[] args) { String sql = "select * from books;"; List<Books> list = GenericQuery.query(sql, Books.class); System.out.println("明日科技新书:"); for (Books books : list) { System.out.println(books); } } }效果如图:
