1.读取
2.数据预处理
前两步请见:https://www.cnblogs.com/cyxxixi/p/12892357.html
3.数据划分—训练集和测试集数据划分
# new_data是要划分的样本特征集--邮件内容,sms_label是划分的样本结果集--垃圾邮件还是普通邮件
# test_size是样本占比,选20%来测试,random_state是随机参数,stratify是平衡比例的
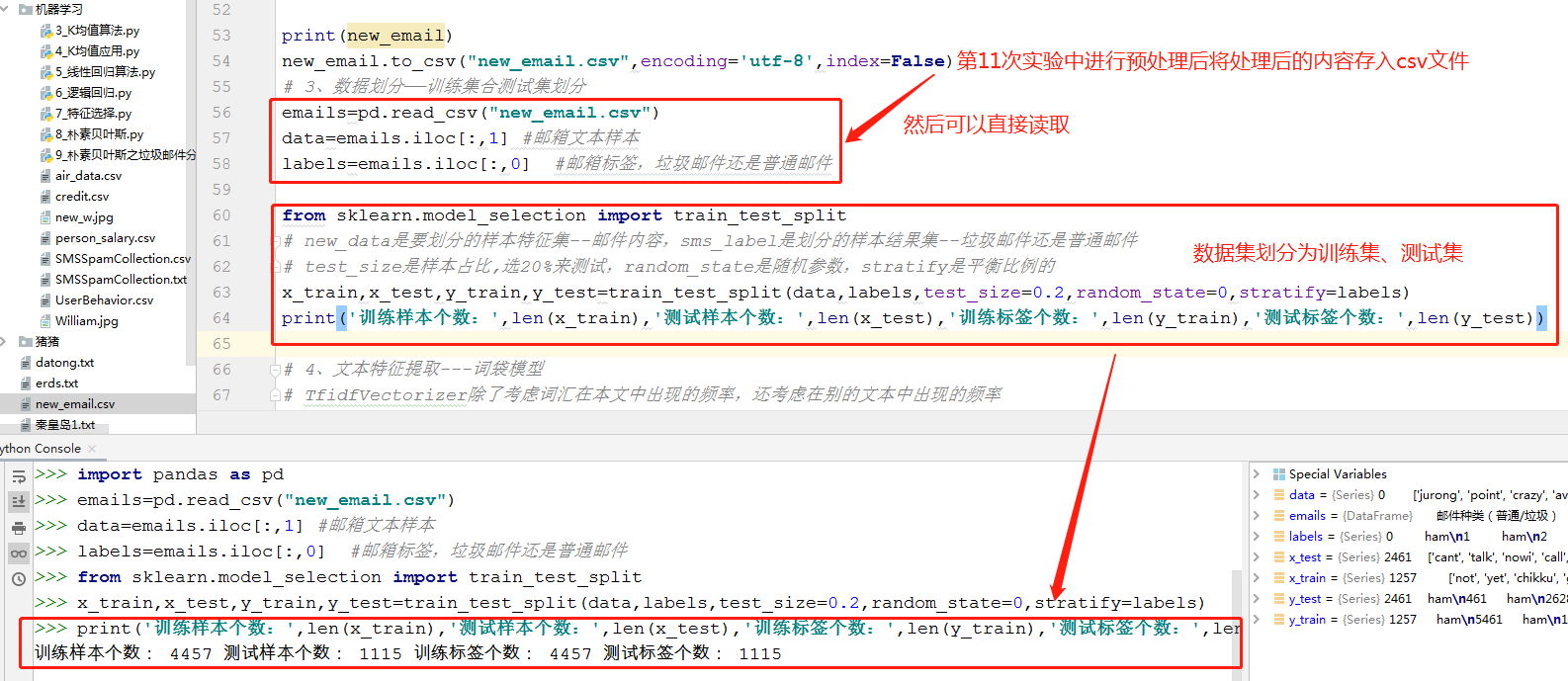
1 emails=pd.read_csv("new_email.csv") #要import pandas as pd
2 data=emails.iloc[:,1] #邮箱文本样本
3 labels=emails.iloc[:,0] #邮箱标签,垃圾邮件还是普通邮件
4
5 from sklearn.model_selection import train_test_split
6
7 x_train,x_test,y_train,y_test=train_test_split(data,labels,test_size=0.2,random_state=0,stratify=labels)
8 print('训练样本个数:',len(x_train),'测试样本个数:',len(x_test),'训练标签个数:',len(y_train),'测试标签个数:',len(y_test))
运行结果:
4.文本特征提取
sklearn.feature_extraction.text.CountVectorizer
sklearn.feature_extraction.text.TfidfVectorizer
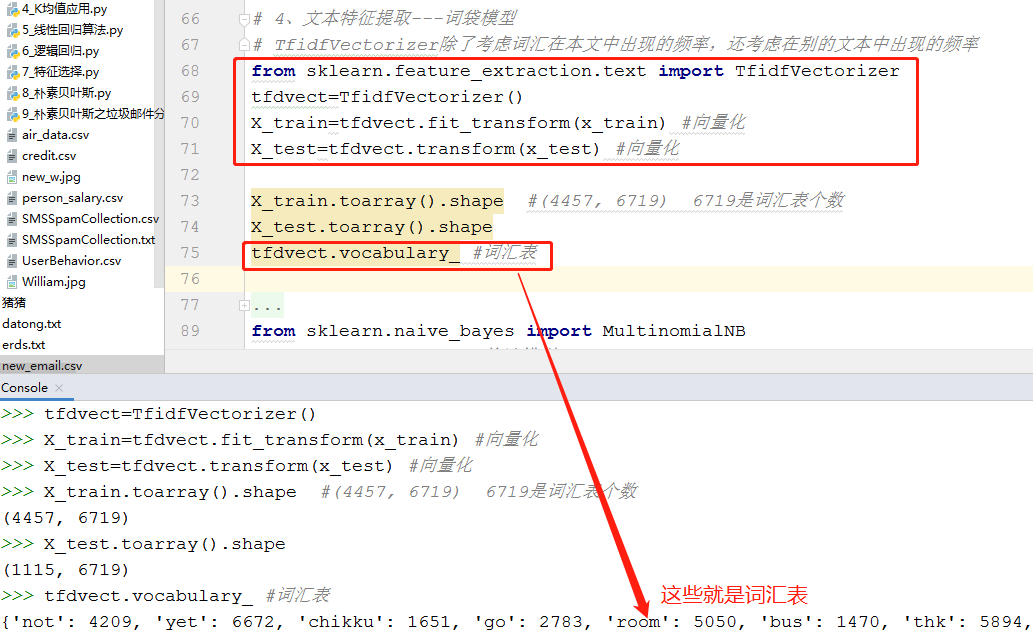
1 # 4、文本特征提取---词袋模型
2 # TfidfVectorizer除了考虑词汇在本文中出现的频率,还考虑在别的文本中出现的频率
3 from sklearn.feature_extraction.text import TfidfVectorizer
4
5 tfdvect=TfidfVectorizer()
6 X_train=tfdvect.fit_transform(x_train) #向量化
7 X_test=tfdvect.transform(x_test) #向量化
8
9 X_train.toarray().shape #(4457, 6719) 6719是词汇表个数
10 X_test.toarray().shape
11 tfdvect.vocabulary_ #词汇表
运行结果:
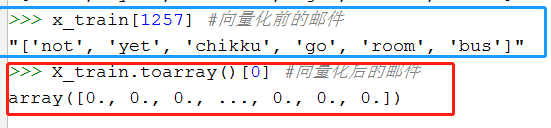
观察邮件与向量的关系
词汇表出来以后,每个邮件的shape变成了(1,len(tfdvect.vocabulary_)),所以变成了[0,0,0.....0,0]这样的形式,如果邮件中的单词在词汇表里有的话,就不为0。
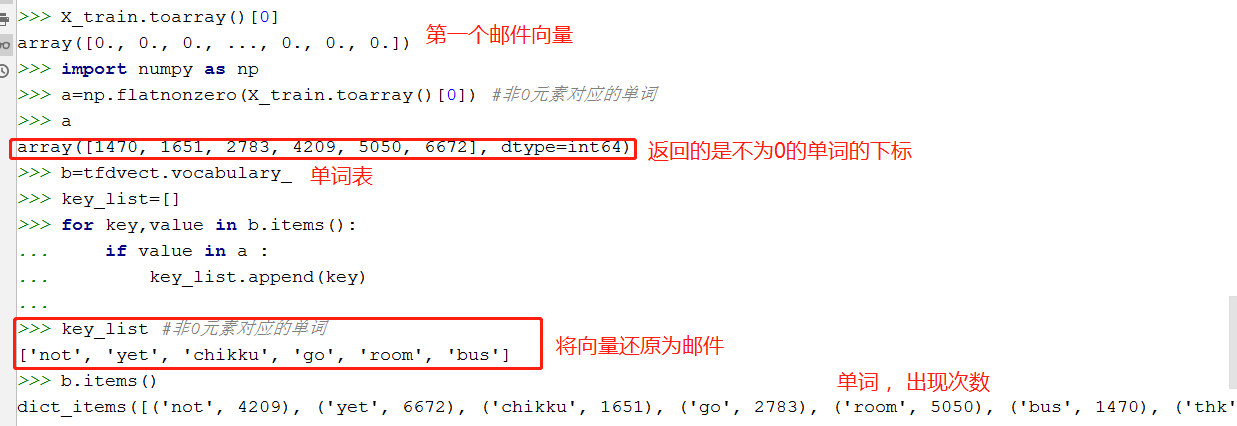
向量还原为邮件
5.模型选择
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
说明为什么选择这个模型?
1 from sklearn.naive_bayes import MultinomialNB 2 3 mnb=MultinomialNB() #构造模型 4 mnb.fit(X_train,y_train) #训练模型 5 y_pre=mnb.predict(X_test) #预测 6 print('预测值',y_pre,' ',"真实值",y_test) 7 print('不符合预测值的个数:',(y_pre!=y_test).sum(),"符合预测的个数",(y_pre==y_test).sum())
运行结果:
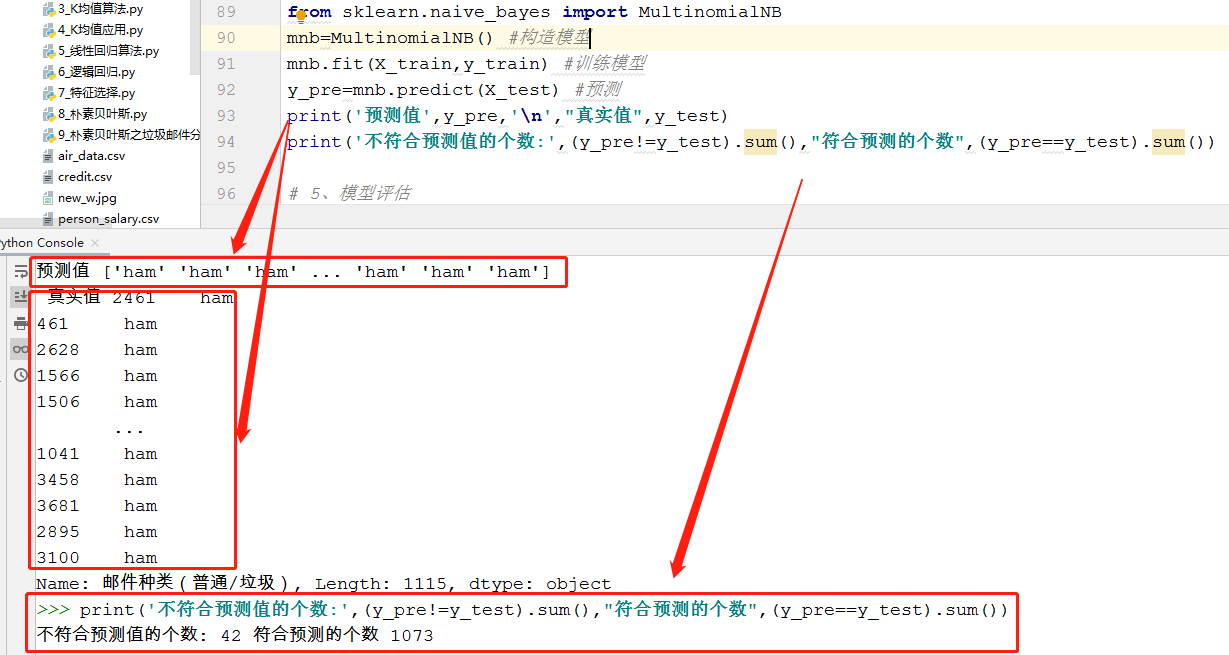
根据分类的特征来选模型
高斯朴素贝叶斯是呈正态分布的,更多的是当样本中数据特征相似时处于一个区间,而其他的特征出现的较少
垃圾邮件分类是单词对与文本的重要性,是单词变量出现次数在其文本中所占比例,以及在其他文本中所占比例,是n次独立重复实验中随机事件出现的次数分别为n1,n2,....,nk的概率符合多项式分布概率。
6.模型评价:混淆矩阵,分类报告
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_predict)
说明混淆矩阵的含义
from sklearn.metrics import classification_report
说明准确率、精确率、召回率、F值分别代表的意义
# 5、模型评估 from sklearn.metrics import confusion_matrix #混淆矩阵 from sklearn.metrics import classification_report #回归报告 import numpy as np con_m=confusion_matrix(y_test,y_pre) print("混淆矩阵",con_m) print((con_m[0][0]+con_m[1][1])/np.sum(con_m)) c_r=classification_report(y_test,y_pre) print("回归报告: ",c_r)
运行结果:
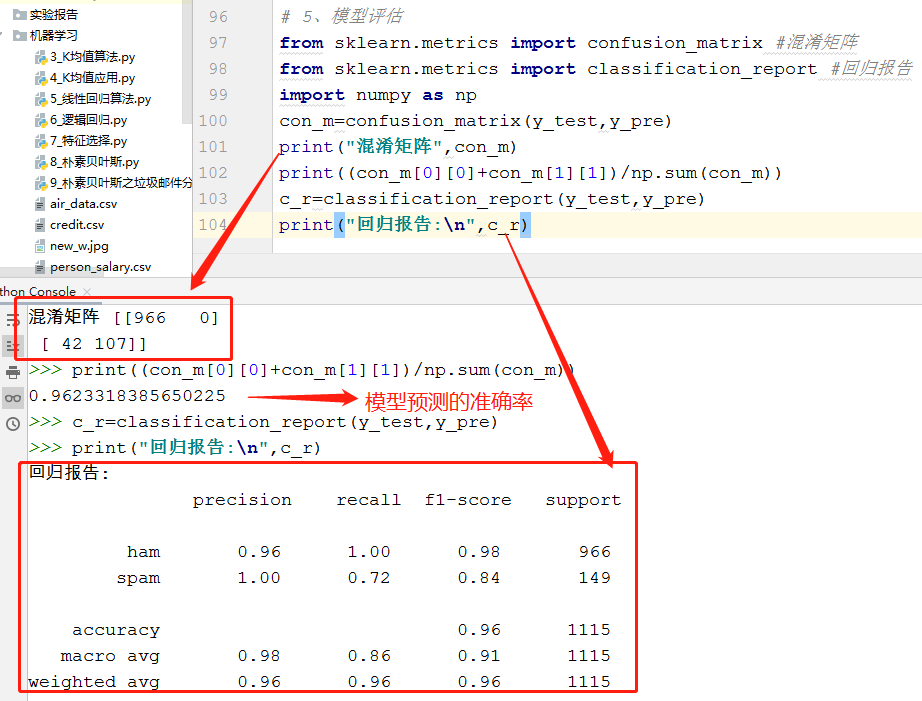
说明混淆矩阵的含义

说明准确率、精确率、召回率、F值分别代表的意义

7.比较与总结
如果用CountVectorizer进行文本特征生成,与TfidfVectorizer相比,效果如何?
CountVectorizer()函数只考虑词汇在文本中出现的频率,属于词袋模型特征。
TfidfVectorizer()除了考量某词汇在文本出现的频率,还关注包含这个词汇的所有文本的数量。能够削减高频没有意义的词汇出现带来的影响, 挖掘更有意义的特征。属于Tfidf特征。


1 from sklearn.feature_extraction.text import CountVectorizer 2 cvect=CountVectorizer() 3 XX_train=cvect.fit_transform(x_train)#向量化 4 XX_test=cvect.transform(x_test)#向量化 5 XX_train.toarray()[0] 6 import numpy as np 7 aa=np.flatnonzero(XX_train.toarray()[0])#非0元素对应的单词 8 aa 9 from sklearn.naive_bayes import MultinomialNB 10 mnb1=MultinomialNB() #构造模型 11 mnb1.fit(XX_train,y_train) #训练模型 12 yy_pre=mnb1.predict(XX_test) #预测 13 print('CountVectorizer的的预测值',yy_pre,' ',"CountVectorizer的真实值",y_test) 14 print('CountVectorizer的不符合预测值的个数:',(yy_pre!=y_test).sum(),"CountVectorizer的符合预测的个数",(yy_pre==y_test).sum()) 15 from sklearn.metrics import confusion_matrix #混淆矩阵 16 from sklearn.metrics import classification_report #回归报告 17 import numpy as np 18 con_m1=confusion_matrix(y_test,yy_pre) 19 print("CountVectorizer的混淆矩阵",con_m1) 20 print((con_m1[0][0]+con_m1[1][1])/np.sum(con_m1)) 21 c_r1=classification_report(y_test,yy_pre) 22 print("CountVectorizer的回归报告: ",c_r1)
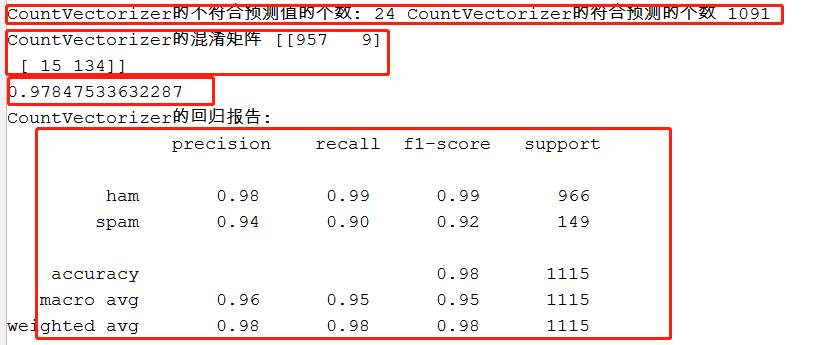
用CountVectorizer进行文本特征生成,与TfidfVectorizer相比,进行代码编写,结果运行后,发现CountVectorizer的效果似乎更好一点。
CountVectorizer在混淆矩阵中,正确的预测会比TfidfVectorizer更加少一点。
参考:https://blog.csdn.net/weixin_40547993/article/details/90296785?utm_medium=distribute.pc_relevant.none-task-blog-baidujs-6
https://blog.csdn.net/u013063099/article/details/80964865