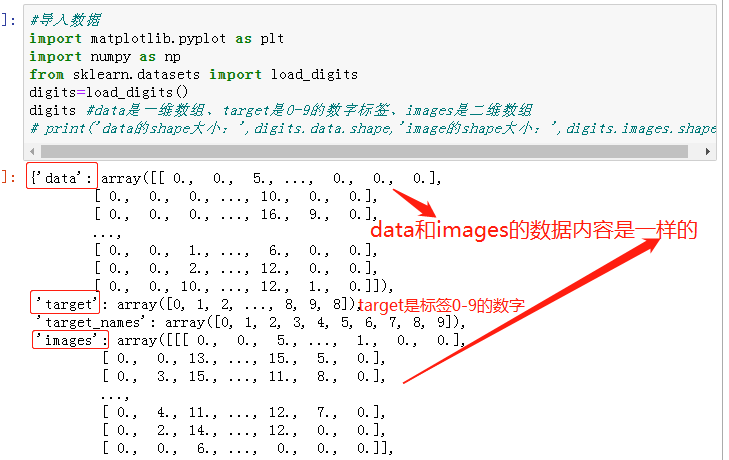
1.手写数字数据集
- from sklearn.datasets import load_digits
- digits = load_digits()

2.图片数据预处理
- x:归一化MinMaxScaler()
- y:独热编码OneHotEncoder()或to_categorical
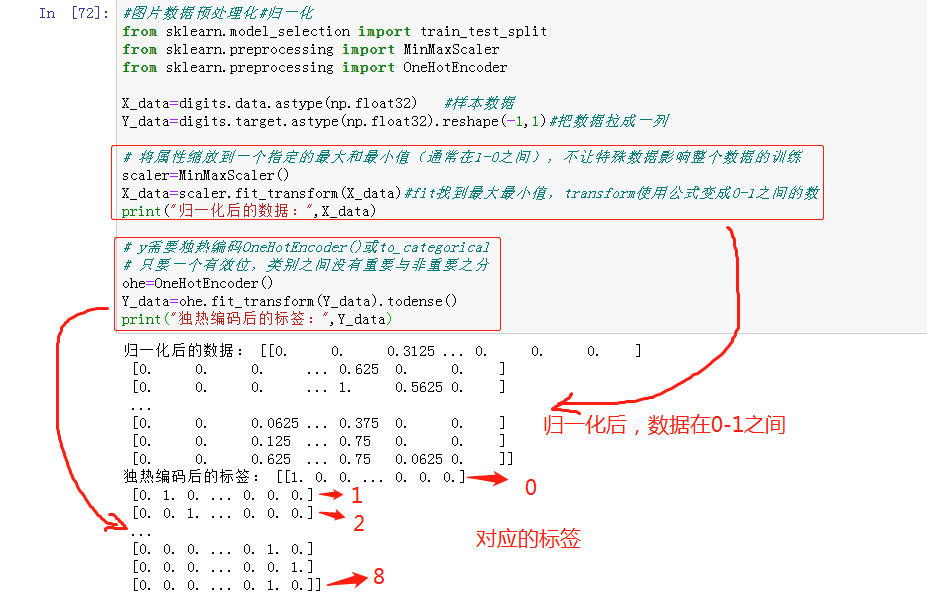
- 训练集测试集划分
- 张量结构

3.设计卷积神经网络结构
- 绘制模型结构图,并说明设计依据。
先导入相关的包
然后设计模型结构,因为图片是(8,8)的像素规模,在池化方面,就最多能池化3次
在卷积上,可以多次卷积,我选择的(3,3)的卷积核,然后卷积的方式是same,即卷积完成后,得到和卷积前同样大小的结果。
构建模型结果:



4.模型训练
- model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
- train_history = model.fit(x=X_train,y=y_train,validation_split=0.2, batch_size=300,epochs=10,verbose=2)

5.模型评价
- model.evaluate()
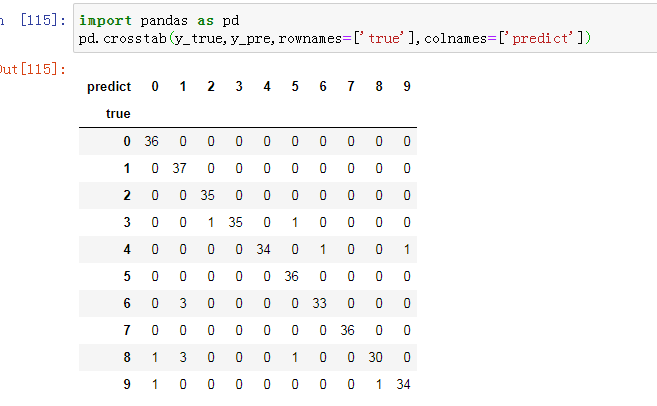
- 交叉表与交叉矩阵
- pandas.crosstab
- seaborn.heatmap

观察预测值和实际值

通过交叉矩阵观察预测值与实际值的符合情况
通过热力图观察预测值与实际值的符合程度
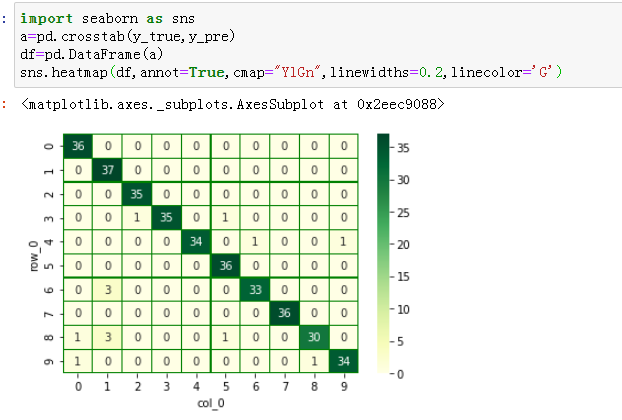
小结:模型构建完成后,得到的精确率在96%左右,说明模型的构建还是有一定的不足,应该更加优化卷积和池化的安排,尝试不同的卷积核得到的模型
从热力图看得出来,在预测数字8的时候容易和数字1混淆,如果是实际应用中则需要加多数字8的样本,让模型能够更好的学习到数字8的特征。也能进行更好的预测。