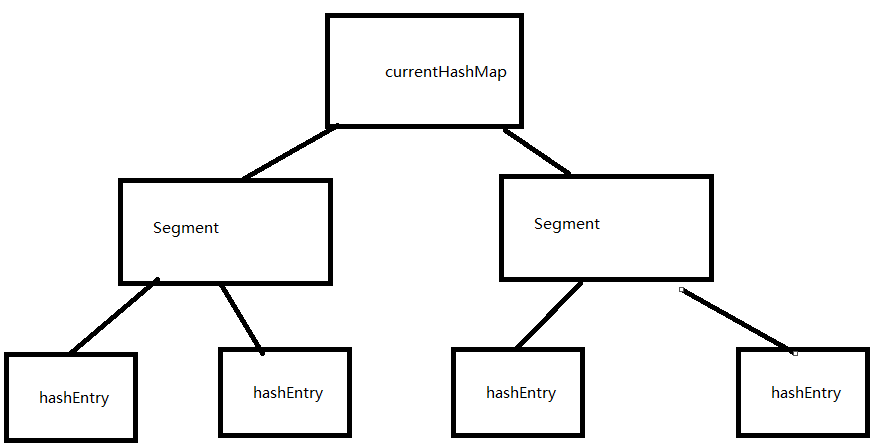
看源码前我们必须先知道一下ConcurrentHashMap的基本结构。ConcurrentHashMap是采用分段锁来进行并发控制的。
其中有一个内部类为Segment类用来表示锁。而Segment类里又有一个HashEntry<K,V>[]数组,这个数组才是真正用
来存放我们的key-value的。
大概为如下图结构。一个Segment数组,而Segment数组每个元素为一个HashEntry数组
看源码前我们还必须了解的几个默认的常量值:
-
DEFAULT_INITIAL_CAPACITY = 16 容器默认容量为16
-
DEFAULT_LOAD_FACTOR = 0.75f 默认扩容因子是0.75
-
DEFAULT_CONCURRENCY_LEVEL = 16 默认并发度是16
-
MAXIMUM_CAPACITY = 1 << 30 容器最大容量为1073741824
-
MIN_SEGMENT_TABLE_CAPACITY = 2 段的最小大小
-
MAX_SEGMENTS = 1 << 16 段的最大大小
-
RETRIES_BEFORE_LOCK = 2 通过不获取锁的方式尝试获取size的次数
以上以及默认值是ConcurrentHashMap中定义好的,下面我们很多地方会用到他们。
先从初始化开始说起
通过我们使用ConcurrentHashMap都是通过 ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();的方式
我们点进去跟踪下源码
/** * Creates a new, empty map with a default initial capacity (16), * load factor (0.75) and concurrencyLevel (16). */ public ConcurrentHashMap() { this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL); }
可以看到,默认无参构造函数内调用了另一个带参构造函数,而这个构造函数也就是不管你初始化时传进来什么参数,最终都会跳到那个带参构造函数。
点进去看看这个带参构造函数实现了什么功能
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException(); if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS; // Find power-of-two sizes best matching arguments int sshift = 0; int ssize = 1; while (ssize < concurrencyLevel) { ++sshift; ssize <<= 1; } this.segmentShift = 32 - sshift; this.segmentMask = ssize - 1; if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; int c = initialCapacity / ssize; if (c * ssize < initialCapacity) ++c; int cap = MIN_SEGMENT_TABLE_CAPACITY; while (cap < c) cap <<= 1; // create segments and segments[0] Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor), (HashEntry<K,V>[])new HashEntry[cap]); Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize]; UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0] this.segments = ss; }
我们看到该构造函数一共有三个参数,分别是容器的初始化大小、负载因子、并发度,这三个参数如果我们new 一个ConcurrentHashMap时没有指定,
那么将会采用默认的参数,也就是我们本文开始说的那几个常量值。
在这里我对这三个参数做下解释。容器初始化大小是整个map的容量。负载因子是用来计算每个segment里的HashEntry数组扩容时的阈值的。并发度是
用来设置segment数组的长度的。

开头这两个if没什么好说的。就是用来判断我们传进来的参数的正确性。当负载因子,初始容量和并发度不按照规范来时会抛出算术异常。第二个if时当传进来的
并发度大于最大段大小的时候,就将其设置为最大段大小。

这段就比较有意思了。由于segment数组要求长度必须为2的n次方,当我们传进来的并发度不是2的n次方时会计算出一个最接近它的2的n次方值
比如如何我们传进来的并发度为14 15那么通过计算segment数组长度就是16。在上图中我们可以看到两个局部变量ssize和sshift,在循环中如果ssize小于
并发度就将其二进制左移一位,即乘2。因此ssize就是用来保存我们计算出来的最接近并发度的2的n次方值。而ssfhit是用来计算偏移量的。在这里我们又
要说两个很重要的全局常量。segmentMask和segmentShift。其中segmentMask为ssize - 1,由于ssize为2的倍数。那么segmentMask就是奇数。化为
二进制就是全1,而segmentShift为32 - sshift大小。32是key值经过再hash求出来的值的二进制位。segmentMask和segmentShift是用来定位当前元素
在segment数组那个位置,和在HashEntry数组的哪个位置,后面我们会详细说说怎么算的。

这一段代码就是用来确定每个segment里面的hashentry的一些参数和初始化segment数组了。第一个if是防止我们设置的初始化
容量大于最大容量。而c是用来计算每个hashentry数组的容量。由于每个hashentry数组容量也需要为2的n次方,因此这里也需要
一个cap和循环来计算一个2的n次方值,方法和上面一样。这里计算出来的cap值就是最终hashentry数组实际的大小了。
初始化就做了这些工作了。
那么我们在说说最简单的get方法。
get方法就需要用到定位我们的元素了。而定位元素就需要我们上面初始化时设置好的两个值:segmentMask和segmentShift
上面说了,并发度默认值为16,那么ssize也为16,因此segmentMask为15.由于ssize二进制往左移了4位,那么sshift就是4,
segmentShift就是32-4=28.下面我们就用segmentMask=15,segmentShift为28来说说怎么确定元素位置的。
在这里我们要说下hash值,这里的hash值不是key的hashcode值,而是经过再hash确定下来的一个hash值,目的是为了减少hash冲突。
hash值二进制为32位。
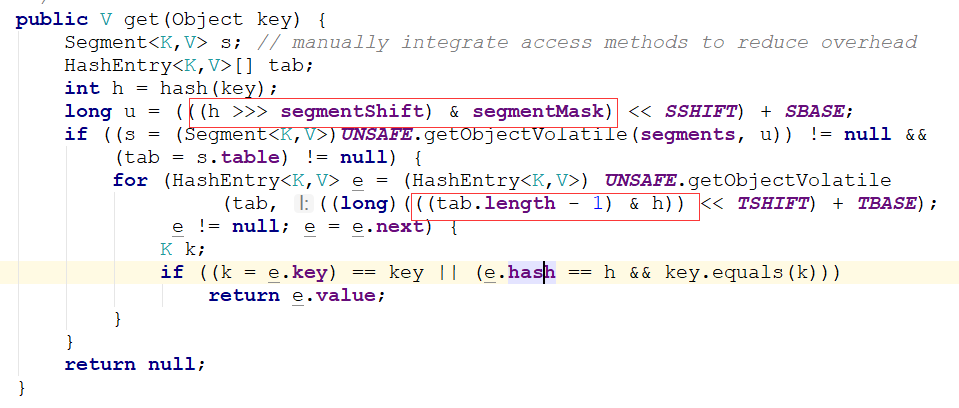
上图两个红框就是分别确定segment数组中的位置和hashentry数组中的位置。
我们可以看到确定segment数组是采用 (h >>> segmentShift) & segmentMask,其中h为再hash过的hash值。将32为的hash值往右移segmentShift位。这里我们假设移了28位。
而segmentMask为15,就是4位都为一的二进制。将高4位与segmentMask相与会等到一个小于16的值,就是当前元素再的segment位置。
确定了所属的segment后。就要确认在的hashentry位置了。通过第二个红框处,我们可以看到确定hashentry的位置没有使用上面两个值了。而是直接使用当前hashentry数组的长度减一
和hash值想与。通过两种不同的算法分别定位segment和hashenrty可以保证元素在segment数组和hashentry数组里面都散列开了。
Put方法
public V put(K key, V value) { Segment<K,V> s; if (value == null) throw new NullPointerException(); int hash = hash(key); int j = (hash >>> segmentShift) & segmentMask; if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment s = ensureSegment(j); return s.put(key, hash, value, false); }
final V put(K key, int hash, V value, boolean onlyIfAbsent) { HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { HashEntry<K,V>[] tab = table; int index = (tab.length - 1) & hash; HashEntry<K,V> first = entryAt(tab, index); for (HashEntry<K,V> e = first;;) { if (e != null) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break; } e = e.next; } else { if (node != null) node.setNext(first); else node = new HashEntry<K,V>(hash, key, value, first); int c = count + 1; if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null; break; } } } finally { unlock(); } return oldValue; }
上面两片代码就是put一个元素的过程。由于Put方法里需要对共享变量进行写入操作,因此为了安全,需要在操作共享变量时加锁。put时先定位到segment,然后在segment里及逆行擦汗如操作。
插入有两个步骤,第一步判断是否需要对segment里的hashenrty数组进行扩容。第二步是定位添加元素的位置,然后将其放在hashenrty数组里。
我们先说说扩容。

在插入元素的时候会先判断segment里面的hashenrty数组是否超过容量threshold。这个容量是我们刚开始初始化hashenrty数组时采用容量大小和负载因子计算出来的。
如果超过这个阈值(threshold)那么就会进行扩容。扩容括的时当前hashenrty而不是整个map。
如何扩容
扩容的时候会先创建一个容量是原来两个容量大小的数组,然后将原数组里的元素进行再散列后插入到新的数组里。
Size方法
由于map里的元素是遍布所有hashenrty的。因此统计size的时候需要统计每个hashenrty的大小。由于是并发环境下,可能出现有线程在插入或者删除的情况。因此会出现
错误。我们能想到的就是使用size方法时把所有的segment的put,remove和clean方法都锁起来。但是这种方法时很低效的。因此concurrenthashmap采用了以下办法:
先尝试2次通过不加锁的方式来统计各个segment大小,如果统计的过程中,容器的count发生了变化,再采用加锁的方式来统计所有segment的大小。
concurrenthashmap时使用modcount变量来判断再统计的时候容器是否放生了变化。在put、remove、clean方法里操作数据前都会将辩能力modCount进行加一,那么在统计
size千后比较modCount是否发生变化,就可以知道容器大小是否发生变化了。