RDD(Resilient Distributed Datasets)弹性分布式数据集。RDD可以看成是一个简单的"数组",对其进行操作也只需要调用有限的"数组"中的方法即可,但它与一般数组的区别在于:RDD是分布式存储,可以跟好的利用现有的云数据平台,并在内存中进行。此处的弹性指的是数据的存储方式,及数据在节点中进行存储的时候,既可以使用内存也可以使用磁盘。此外,RDD还具有很强的容错性,在spark运行计算的过程中,不会因为某个节点错误而使得整个任务失败;不通节点中并发运行的数据,如果在某个节点发生错误时,RDD会自动将其在不同的节点中重试。
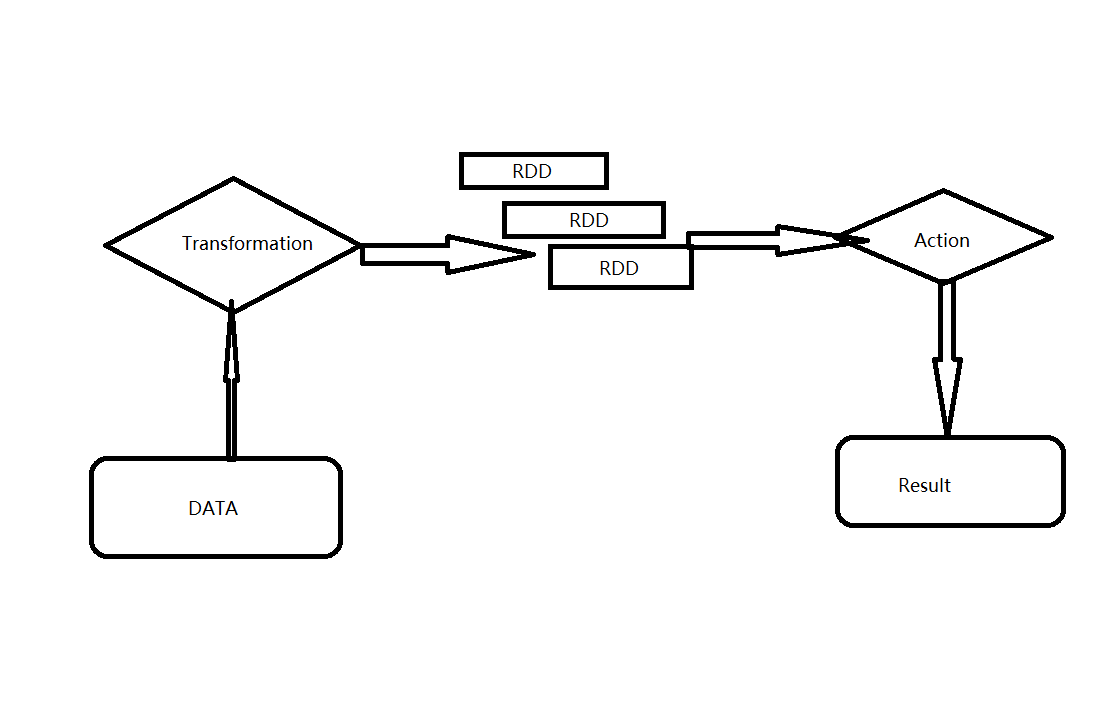
RDD一大特性是延迟计算,即一个完整的RDD运行任务被分成2部分:Transformation和Action。
Transformation用于对RDD的创建。在spark中,RDD只能使用Transformation来创建,同时Transformation还提供了大量的操作方法。RDD还可以利用Transformation来生成新的RDD,这样可以在有限的内存空间中生成竟可能多的数据对象。无论发生了多少次Transformation,此时,在RDD中真正数据计算运行的操作Action都没真正的开始运行。

Action是数据的执行部分,其也提供了大量的方法去执行数据的计算操作部分。

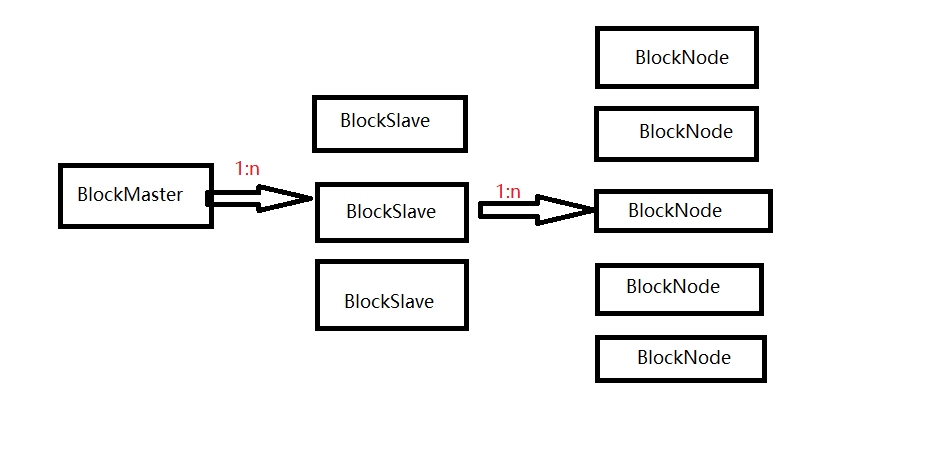
RDD可以将其看成一个分布在不同节点中的分布式数据集,并将数据以数据块(Block)的形式存储在各个节点的计算机中。每个BlockMaster管理着若干个BlockSlave,而每个BlockSlave又管理着若干个BlockNode。当BlockSlave获得了每个Node节点的地址,又会反向向BlockMaster注册每个Node的基本信息,这样就形成了分层管理。
RDD依赖

import org.apache.spark.{SparkConf, SparkContext} object test { def main(args: Array[String]): Unit = { val conf=new SparkConf().setMaster("local").setAppName("test") val sc=new SparkContext(conf) val arr=sc.parallelize(Array(1,2,3,4,5,6,7,8))//parallelize将内存数据读入Spark系统中,作为整体数据集 val result=arr.aggregate(0)(math.max(_,_),_+_)//_+_ 对传递的第一个方法的结果集进行进一步处理 println(result) } }
结果为8
import org.apache.spark.{SparkConf, SparkContext} object test { def main(args: Array[String]): Unit = { val conf=new SparkConf().setMaster("local").setAppName("test") val sc=new SparkContext(conf) val arr=sc.parallelize(Array("abd","hello world","hello sb"))//parallelize将内存数据读入Spark系统中,作为整体数据集 val result=arr.aggregate("")((value,word)=>value+word,_+_)//_+_ 对传递的第一个方法的结果集进行进一步处理 println(result) } }
结果为abdhello worldhello sb
3、cache是将数据内容计算并保存在计算节点的内存中
4、cartesion是用于对不同的数组进行笛卡尔操作,要求是数组的长度必须相同
import org.apache.spark.{SparkConf, SparkContext} object test { def main(args: Array[String]): Unit = { val conf=new SparkConf().setMaster("local").setAppName("test") val sc=new SparkContext(conf) val arr1=sc.parallelize(Array(1,2,3,4))//parallelize将内存数据读入Spark系统中,作为整体数据集 val arr2=sc.parallelize(Array(4,3,2,1)) val res=arr1.cartesian(arr2) res.foreach(print) } }
结果:(1,4)(1,3)(1,2)(1,1)(2,4)(2,3)(2,2)(2,1)(3,4)(3,3)(3,2)(3,1)(4,4)(4,3)(4,2)(4,1)
5、Coalesce是将已经存储的数据重新分片后再进行存储(repartition与Coalesce类似)
import org.apache.spark.{SparkConf, SparkContext} object test { def main(args: Array[String]): Unit = { val conf=new SparkConf().setMaster("local").setAppName("test") val sc=new SparkContext(conf) val arr1=sc.parallelize(Array(1,2,3,4,5,6))//parallelize将内存数据读入Spark系统中,作为整体数据集 val arr2=arr1.coalesce(2,true) val res1=arr1.aggregate(0)(math.max(_,_),_+_) println(res1) val res2=arr2.aggregate(0)(math.max(_,_),_+_) println(res2) } }
结果为6 11
6、countByValue是计算数据集中某个数据出现的个数,并将其以map的形式返回
7、countByKey是计算数据集中元数据键值对key出现的个数


import org.apache.spark.{SparkConf, SparkContext} object test { def main(args: Array[String]): Unit = { val conf=new SparkConf().setMaster("local").setAppName("test") val sc=new SparkContext(conf) val arr1=sc.parallelize(Array((1,"a"),(2,'b'),(1,'c'),(1,'d'),(2,'a')))//parallelize将内存数据读入Spark系统中,作为整体数据集 val res1=arr1.countByValue() res1.foreach(println) val res2=arr1.countByKey() res2.foreach(println) } } //结果:((1,c),1) ((2,a),1) ((1,a),1) ((1,d),1) ((2,b),1) (1,3) (2,2)
8、filter是对数据集进行过滤
9、flatMap是对RDD中的数据进行整体操作的一个特殊方法,其在定义时就是针对数据集进行操作
10、map可以对RDD中的数据集进行逐个操作,其与flatmap不同得是,flatmap是将数据集中的数据作为一个整体去处理,之后再对其中的数据做计算,而map则直接对数据集中的数据做单独的处理
11、groupBy是将传入的数据进行分组
12、keyBy是为数据集中的每个个体数据添加一个key,从而形成键值对
13、reduce同时对2个数据进行处理,主要是对传入的数据进行合并处理
14、sortBy是对已有的RDD进行重新排序
import org.apache.spark.{SparkConf, SparkContext} object test { def main(args: Array[String]): Unit = { val conf=new SparkConf().setMaster("local").setAppName("test") val sc=new SparkContext(conf) val arr1=sc.parallelize(Array((1,"a"),(2,"c"),(3,"b"),(4,"x"),(5,"f")))//parallelize将内存数据读入Spark系统中,作为整体数据集 val res1=arr1.sortBy(word=>word._1,true) val res2=arr1.sortBy(word=>word._2,true) res1.foreach(println) res2.foreach(println) } }
15、zip可以将若干个RDD压缩成一个新的RDD