本文翻译自How Self-Attention with Relative Position Representations works, 介绍 Google的研究成果。
引言
本文基于Shaw 等人发表的论文 《Self-Attention with Relative Position Representations》 展开。论文介绍了一种在一个Transformer内部编码输入序列的位置信息的方法。特别的是,论文改进了Tranformer的自注意力机制,让其能够更有效地将序列中的词之间的相对距离考虑进来。
本文旨在用易于理解的语言解释论文中的要点。读懂本文的前提是对 Recurrent Neural Networks (RNNs) 和Transformers 中的多头注意力机制(multi-head self-attention mechanism)有基本的了解。
动机
利用隐状态hidden state,RNN能够让模型隐式地编码序列的顺序信息。例如,下图展示了RNN输出输入序列“I think therefore I am” 中每一个词的向量表示。
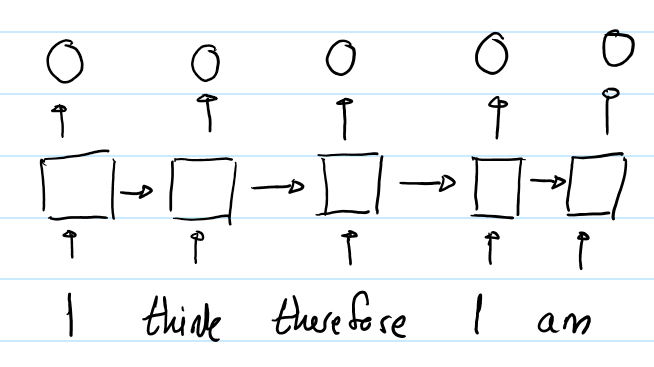
第二个“I”的输出不同于第一个“I”的输出,因为他们隐状态的输入是不一样的。对第二个“I”而言,隐状态经过了 “I think therefore”三个词,而第一个“I” 的隐状态仅是一个初始值。因此,RNN的隐状态保证了在不同位置上的相同的词会有不同的输出向量表示。
相比之下,Transformer的自注意力层(不带位置表示)对不同位置出现的相同词给出的是同样的输出向量表示。例如:
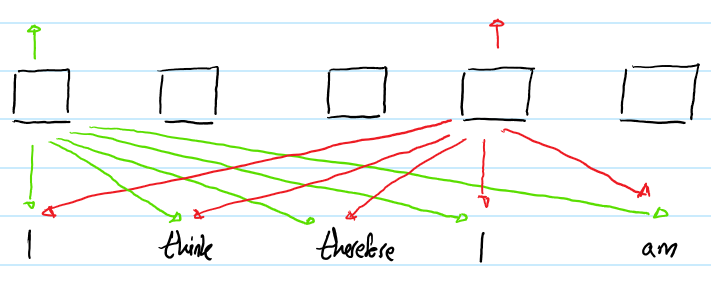
上图展示了输入序列“I think therefore I am”送入Transformer的过程。 为了方便阅读,仅仅画出两个“I”的输出。注意,尽管两个“I”在不同输入序列的不同位置上,他们对应的输出向量表示还是相同的。
解决方案
概览
作者提出的方法是,在Transformer中加入一组可训练的嵌入表示,从而让输出带有一定的顺序信息。这一嵌入表示在计算第i个词和第j个词之间的注意力权重和注意力值的时候会用到。他们代表了第i个词和第j个词之间的距离(间隔多少个词),因此将这种方法称为相对位置表示(RPR)。
例如,一个句子由五个词,一共会有9个嵌入表示需要学习(一个是当前词的嵌入,有4个是上文4个词的嵌入,4个是下文4个词的嵌入。译者注:k=4)。9个嵌入如下所示:

下图清晰地展示了如何使用这些嵌入:
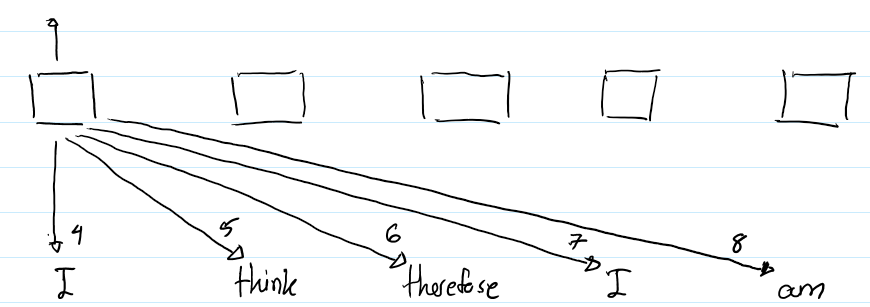
上图描绘了第一个“I”的输出表示的计算过程。箭头旁的数字表示在计算注意力的时候使用的是哪一种相对位置表示。例如,当Transformer正在计算“I”和“therefore”之间的注意力时,它会利用包含在第6个RPR中的信息,因为“therefore” 是第一个“I”右边的第2个词。(译者注:因为k设置为4,因此词i到词i的距离对应index4,词i到词i+1的距离对应index5,词i到词i+2的距离对应index6,以此类推)
下图描绘了第二个“I”的输出表示的计算过程。
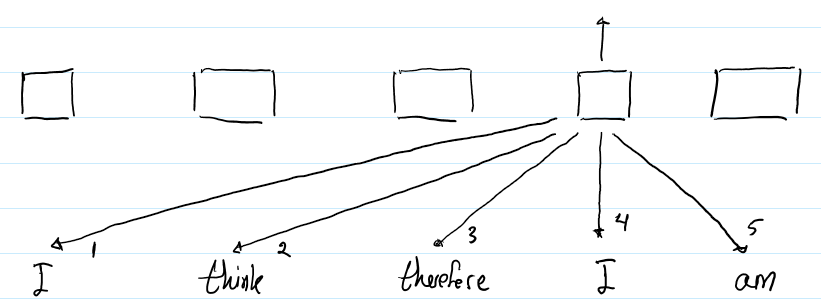
但是,每个词的RPR又是不一样的。例如,第3个RPR是用来计算 “I”和“therefore” 之间的注意力的,因为“therefore”是第二个“I”的左边的第一个词。这就是RPR帮助Transformer编码输入序列的顺序信息。
注释
下面的符号注释在本文后面的阐述中会用到。

注意,这其中共有两组RPR嵌入需要学习:一个用于计算词i的输出表示zᵢ,另一个用于计算词i到词j的权重系数eᵢⱼ。不同于投影矩阵,这些嵌入在注意力头间是共享的。
另一个值得注意的关键点是,需要考虑的词间距离的最大值被限制在一个常数k。这意味着,需要学习的RPR嵌入的数量是2k+1(上文k个词,下文k个词以及当前词)。向右间隔词i超过k个词的词对应第2k个RPR, 向左间隔词i超过k个词的词对应第0个RPR。例如,一个有10个词的输入序列,k设为3,那么RPR嵌入的lookup表如下:
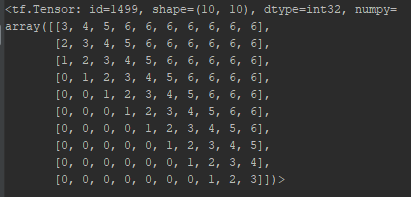
按照这种设计,行i对应第i个词,列j代表第j个词。索引号3对应第i个词,索引号6对应第i个词右边第3个以及更右的词,索引号0对应第i个词左边第3个以及更左的词。第1个词(第1行)的嵌入表示的通过查表可得。注意,从第i个词右边第3个词起的所有词的索引号都是6。这意味着即使输入序列的第一个词和最后一个词之间的距离是9,最后一个词使用的RPR嵌入也与右边第3个词的RPR嵌入相同。
这么设计有两个原因:
- 作者假定在一定距离之外,再精确的相对位置信息也是没有用的。
- 限制住最长距离能够提升模型对未在训练阶段出现过的长度的序列的泛化能力。
实现
下面的等式展示了在没有使用RPR嵌入的情况下,计算 zᵢ 的过程:

引入RPR嵌入后的式子 (1)变成了:
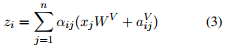
式子 (2)变成了 :
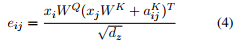
总而言之,式子3是当要计算词i的输出表示时,我们对相对词j的value向量的权重的计算进行了改进,方法就是将相对于词j的value向量加上词i和词j之间的RPR嵌入。同理,式子4告诉我们,如何改进词i和词j之间的缩放的点积操作,就是通过将相对于词j的key向量加上词i和词j之间的RPR嵌入。根据作者的描述,使用加法作为一种将RPR嵌入整合进来的方法让算法实现更高效,本文后面会继续介绍。
高效实现
Transformer的输入是一个大小为 (batch_size, seq_length, embedding_dim)的张量。在不带RPR嵌入的情况下,Transformer能够利用batch_size * h 并行地进行矩阵乘法来计算 eᵢⱼ (式子2) 。每一次矩阵乘法都会计算给定输入序列和注意力头中所有的元素的eᵢⱼ 。这个过程使用下面的表达式实现的:
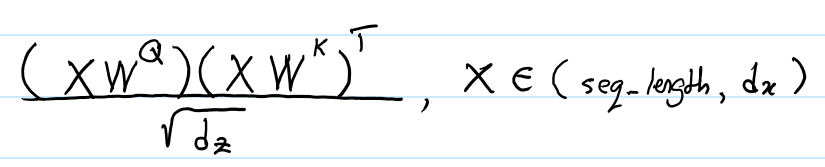
X是给定输入序列中所有元素按行拼接起来的矩阵。
为了在加入了RPR嵌入之后也能有相近的计算效率(时间上和空间上),我们首先使用了矩阵乘法的性质将式子(4)重写为:
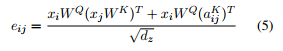
分子的左半部分和式子 (2)相同,因此在矩阵乘法中能够高效运算。右半部分就有点技巧性了。这部分代码实现定义在函数 relative_attention_inner 中,因此我会较简单地把大体逻辑介绍一下。
- 分子左半部分的大小为 (batch_size, h, seq_length, seq_length)。这个张量的行i列j上的元素代表了词i的query向量和词j的key向量的点积的结果 。因此,我们的目标是产生另一个和这个张量大小相同的张量,而这个张量的各个元素应该是词i的query向量和词i与词j之间的RPR嵌入的点积的结果(译者注:也就是分子右半部分)。
- 首先,我们使用查表的形式为一个给定的输入序列生成RPR嵌入张量A,A的形状是(seq_length, seq_length, dₐ)。然后,我们对A进行转置,使它的形状变成 (seq_length, dₐ , seq_length) ,写成 Aᵀ。
- 接下来,我们计算输入序列所有元素的query向量,得到一个 (batch_size, h, seq_length, dz)形状的张量。然后对其进行转置,形状变为 (seq_length, batch_size, h, dz) ,然后变形为 (seq_length, batch_size * h, dz)的张量。这个张量现在就能与 Aᵀ相乘了。这个乘法可以视为矩阵 (batch_size * h, dz) 和矩阵 (dₐ, seq_length)的乘法。基本上就是计算每个位置的query向量和对应的RPR嵌入的点积。
- 上面的乘法得到一个形状为 (seq_length, batch_size * h, seq_length)的张量。我们只需要将其变形为(seq_length, batch_size, h, seq_length)的形状,然后再转置得到形状为 (batch_size, h, seq_length, seq_length) 的张量,这样我们就能将它和分子左半部分进行相加了。
同样的逻辑也用在式子 (3)的计算中。
结果
作者在与Vaswani 等人发表的论文《Attention is All You Need》 中相同的机器翻译任务上评价他的改进方法的对翻译效果的影响。尽管每秒钟的训练步数下降了7个百分点,其模型在英译德任务上的BLEU还是提高了1.3,在英译法上提高了0.5。
结论
在本文中,笔者解释了为什么Transformer中的自注意力机制无法编码输入序列的位置信息,以及Shaw 等人相对位置表示嵌入(RPR)如何解决这一问题。笔者希望本文能帮助你更好的理解Shaw的文章。
参考文献
-
Self-Attention with Relative Position Representations; Shaw et al. 2018.
-
Attention Is All You Need; Vaswani et al., 2017.
-
Transformer: A Novel Neural Network Architecture for Language Understanding; Uszkoreit. 2017
-
The Unreasonable Effectiveness of Recurrent Neural Networks; Karpathy. 2015.