1. 一个mapper
package MapReduce; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * @Author:Dapeng * @Discription: 默认的MapReduce是通过TextInputFormat进行切片,并交给Mapper处理 * TextInputFormat:key:当前行的首字母的索引,value:当前行里面放了什么数据 * @Date:Created in 下午 15:00 2018/10/25 0025 */ public class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable> { LongWritable one = new LongWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //第一个key代表第几行 //第一个value表示某一行的内容 //将一行Text转换为String String words = value.toString(); //将一行words切片成为单词 String[] wordArr = words.split(" "); //遍历每个单词 for(String str:wordArr){ context.write(new Text(str),one); } } }
2. 一个reducer
package MapReduce; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * @Author:Dapeng * @Discription: * @Date:Created in 下午 15:16 2018/10/25 0025 */ public class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { Long sum = 0L; for(LongWritable value:values){ sum += value.get(); } context.write(key,new LongWritable(sum)); } }
3. 一个Job
package MapReduce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * @Author:Dapeng * @Discription: * @Date:Created in 下午 14:50 2018/10/25 0025 */ public class WordCount { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //0.创建一个job Configuration conf = new Configuration(); Job job = Job.getInstance(conf,"word_count"); job.setJarByClass(WordCount.class); //1.输入文件 //默认用TextInputFormat FileInputFormat.addInputPath(job,new Path(args[0])); //2.编写mapper job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //3.shuffle //4.reduce job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //5.输出 FileOutputFormat.setOutputPath(job,new Path(args[1])); //6.运行 boolean result = job.waitForCompletion(true); System.out.println(result); } }
4. 打包
https://www.cnblogs.com/blog5277/p/5920560.html
5. 运行命令
yarn jar Myhadoop.jar mapreduce.WordCount /user/out.txt /user/myout (最后一个是输出的文件夹)
jar包名字 主类 参数1 参数2
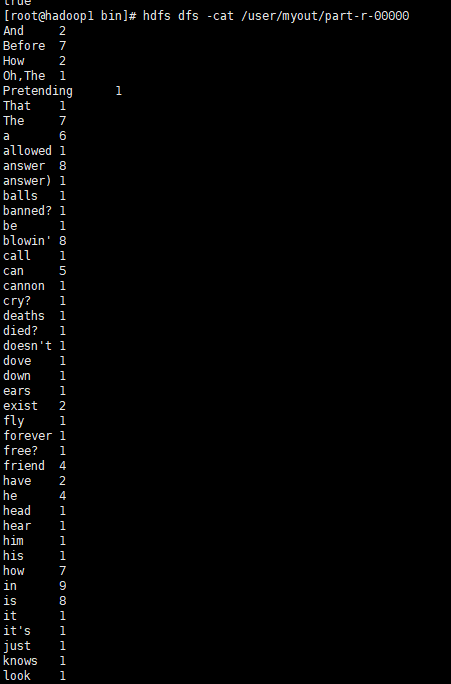
6. 结果查看

生成一个part-r-00000文件,存放结果
查看结果