机器学习算法评估标准:准确率,速度,强壮性(噪音影响较小),可规模性,可解释性。
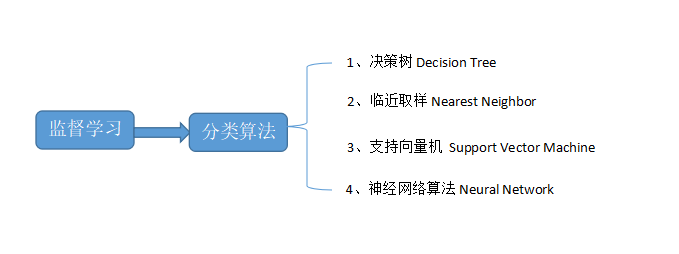
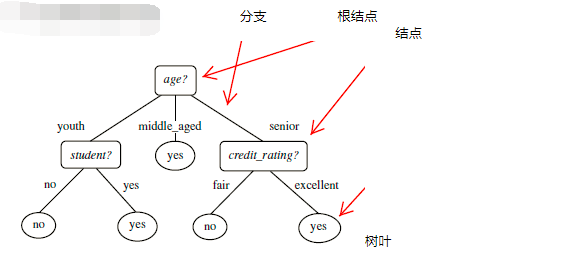
1、决策树 Decision Tree:决策树是一个类似于流程图的树结构,其中每个内部节点表示在一个属性上的测试,每一个分支代表一个属性输出,每一个树叶节点代表类(label)或类的分布。树的最顶层是根节点。
2、信息熵:发生一件事情的不确定性越大,我们需要的信息量越大,信息熵也就越大。信息量的度量就等于不确定性的多少。
用bit表示信息量的多少H = -∑P(x)logP(x)
决策树归纳算法通过信息熵计算选择属性判断节点:
信息获取量(Information Gain) Gain(A)=Info(D)-Info_A(D)
通过属性A获取的信息量=没有属性A时所需信息量-有属性A时所需信息量
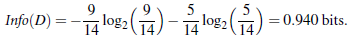
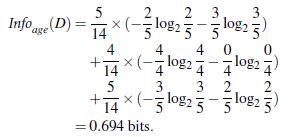

通过比较每一个节点的Gain信息获取量,来确定哪个属性作为判断节点。
3、算法
一、树以代表训练样本的单个节点开始
二、如果样本都在同一个类,则该节点成为树叶。
三、否则,算法使用基于熵的度量作为启发信息,选择能够将样本更好的进行分类的属性,该属性成为节点的“测试”或“判定”属性。
1、所有的属性都是离散的,连续属性必须离散化。
2、对测试属性的每个已知值,创建一个分支,并据此划分样本。
3、算法使用同样的过程,递归形成每个划分上的样本判定树。
递归停止条件:a、给定节点的所有样本属于同一类。b、没有剩余属性来进一步划分样本。(多数表决)
决策树优点:直观,便于理解,小规模数据有效。
缺点:处理连续变量不好,类别较多时错误增加的比较快,可规模性一般。
代码实例

from sklearn.feature_extraction import DictVectorizer
from sklearn import preprocessing
from sklearn import tree
import csv
AllElectronics=open('D:daachengPythonPythonCodemachineLearningAllElectronics.csv','rt')#打开csv文件
readers=csv.reader(AllElectronics)
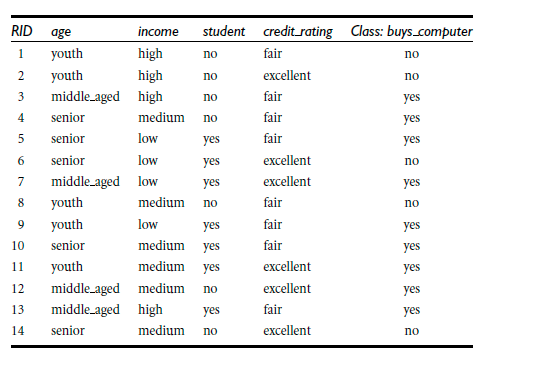
headers=next(readers)#表头 ['RID', 'age', 'income', 'student', 'credit_rating', 'class_buys_computer']
featureList=[]#特征集合
labelList=[]#标签集合
for row in readers:
rowDict={} #每一行数据以集合的形式存储,最后把这些集合存储在列表中
labelList.append(row[len(row)-1])
for i in range(1,len(row)-1):
#print(headers[i])
#print(row[i])
rowDict[headers[i]]=row[i]
featureList.append(rowDict)
vec=DictVectorizer()
dummyX=vec.fit_transform(featureList).toarray()#转换,把特征转换成列表
#names=vec.get_feature_names()
#print(names)
lb=preprocessing.LabelBinarizer()
dummyY=lb.fit_transform(labelList)#对标签进行转换
#dummyY
clf=tree.DecisionTreeClassifier(criterion='entropy')#指定通过信息熵选择节点
clf=clf.fit(dummyX,dummyY)#训练学习
#制造一个新数据来进行预测
oneRowX=dummyX[0,:]
newRowX=[]
newRowX.append(oneRowX)
newRowX[0][0]=1
newRowX[0][1]=0
#print(newRowX[0])
#predictY1=clf.predict(oneRowX)
predictY2=clf.predict(newRowX)#需要传入一个二维数组
#print(predictY1)
print(predictY2)