下载安装
下载网址: http://archive.cloudera.com/cdh5/cdh/5/
首先先下载安装包:
我的版本是:hive-1.1.0-cdh5.15.1
所以下载地址是: http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.15.1.tar.gz
下载完后解压:tar xvf hive-1.1.0-cdh5.15.1.tar.gz
配置
进入hive的conf目录:
cd hive-1.1.0-cdh5.15.1/conf/
把hive-env.sh.template 复制为hive-env.sh
cp hive-env.sh.template hive-env.sh
修改hive-env.sh
HADOOP_HOME=/root/hadoop/app/hadoop-2.6.0-cdh5.15.1 export HIVE_CONF_DIR=/root/hadoop/app/hive-1.1.0-cdh5.15.1/conf
新增hive-site.xml
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.1.102:3306/immoc_hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property> </configuration>
设置快捷方式 (vi ~/.bash_profile)
export HIVE_HOME=/root/hadoop/app/hive-1.1.0-cdh5.15.1 export PATH=$HIVE_HOME/bin:$PATH
source ~/.bash_profile (加载)
启动
hive
操作语句
显示数据库: show databeses;
新建数据库: CREATE DATABASE IF NOT EXISTS hive //默认的新增
新增自定义存储位置的数据库:
CREATE DATABASE IF NOT EXISTS hive01 LOCATION '/test/location'
新增带有参数的数据库:
CREATE DATABASE IF NOT EXISTS hive02 WITH DBPROPERTIES ('name'='zhangsan')
删除数据库(只能删除空库): drop database hive01
级联删除数据库(库的所有东西都删掉): drop database hive01 CASCADE;
进入数据库: use hive
查看详细信息:desc database hive0;
查看更详细的信息: desc database EXTENDED hive02;
让命令行显示现在使用的是哪个数据库:
查看状态: set hive.cli.print.current.db

设置: set hive.cli.print.current.db=true

数据库的存储方式:
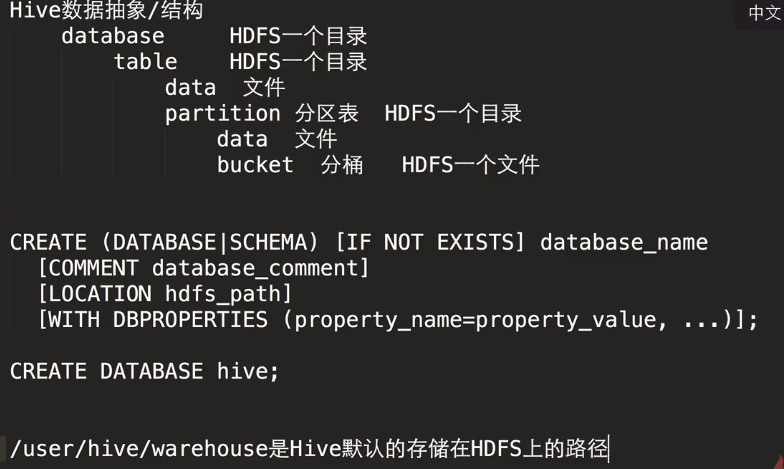
结构是存储在mysql上,数据是存在hadoop上的
查看mysql

可以看到是存储在/user/hive/warehouse上的,也可以指定相应的路径,上面命令有写到
表的ddl操作
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ';
把数据导入数据库:
load data local inpath '/root/hadoop/app/emp.txt' into table emp;
如果一下错误报错了:
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:An exception was thrown while adding/validating class(es) : Column length too big for column 'PARAM_VALUE' (max = 16383); use BLOB or TEXT instead java.sql.SQLSyntaxErrorException: Column length too big for column 'PARAM_VA
解决办法一:
启动hive之前执行 ./schematool -dbType mysql -initSchema
解决办法二:
修改字符集:
alter database hive character set latin1; flush privileges
表操作
查看表结构:
desc emp;
详细表结构:
desc extended emp;
详细表信息(有格式)
desc formatted emp;
修改表:
ALTER TABLE emp RENAME TO emp1;
数据管理

导入本地文件 LOAD DATA local inpath '/root/hadoop/app/emp.txt' INTO TABLE emp; 导入hdfs文件 LOAD DATA inpath 'hdfs://hadoop000:8020/emp.txt' INTO TABLE emp; 导入本地文件(覆盖) LOAD DATA local inpath '/root/hadoop/app/emp.txt' OVERWRITE INTO TABLE emp; OVERWRITE 有:覆盖 没有:追加 创建emp表并且把结构和数据导过去: create table emp1 as select * from emp; 导出到本地路径 INSERT OVERWRITE LOCAL DIRECTORY '/tmp/hive1' ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' select empno,ename,job,deptno from emp;
其他基本查询操作跟关系型数据库差不多所以后面就不写了。。。
额外知识:
MANAGED_TABLE:内部表 删除表: HDFS上的数据被删除 & Meta也被删除 EXTERNAL_TABLE:外部表 删除表: 只有Meta被删除 我们默认创建的都是内部表 可以用desc formmat emp; 来查看
创建一个外部表
CREATE EXTERNAL TABLE emp_external(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' '
LOCATION '/hive/external';