1、Vector和ArrayList以及LinkedList区别和联系,以及分别的应用场景
线程安全
Vector:如果创建Vector时没有指定容量,则默认容量为10,底层基于数组实现,线程是安全的,底层采用synchronized同步方法进行加锁
ArrayList:底层基于数组,线程不安全,查询和修改效率高,但是增加和删除效率低
LinkedList:底层双向链表结构,线程不安全,查询和修改效率低,但是增加和删除效率高,另外,它还提供了List接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈,队列和双向队列使用;
使用场景
Vector很少用
如果需要大量的添加和删除则可以选择LinkedList
如果需要大量的查询和修改则可以选择ArrayList
Vector源码
/** * Adds the specified component to the end of this vector, * increasing its size by one. The capacity of this vector is * increased if its size becomes greater than its capacity. * * <p>This method is identical in functionality to the * {@link #add(Object) add(E)} * method (which is part of the {@link List} interface). * * @param obj the component to be added */ public synchronized void addElement(E obj) { modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = obj; }
ArrayList源码
/** * Appends the specified element to the end of this list. * * @param e element to be appended to this list * @return <tt>true</tt> (as specified by {@link Collection#add}) */ public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }
LinkedList源码
/** * Appends the specified element to the end of this list. * * <p>This method is equivalent to {@link #addLast}. * * @param e element to be appended to this list * @return {@code true} (as specified by {@link Collection#add}) */ public boolean add(E e) { linkLast(e); return true; }
2、如果要保证ArrayList线程安全,有几种方式
自己表写一个ArrayList集合类,根据业务一般来说,add/set/remove加锁
利用List<Object> list = Collections.synchronizedList(new ArrayList<>()); //采用synchronized加锁
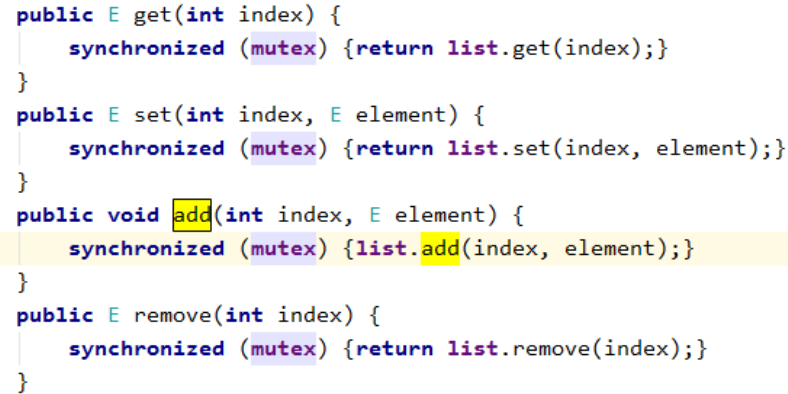
public E get(int index) { synchronized (mutex) {return list.get(index);} } public E set(int index, E element) { synchronized (mutex) {return list.set(index, element);} } public void add(int index, E element) { synchronized (mutex) {list.add(index, element);} } public E remove(int index) { synchronized (mutex) {return list.remove(index);} }
new CopyOnWriteArrayList<>().add(""); //采用 ReentrantLock加锁
public boolean add(E e) { //加锁 final ReentrantLock lock = this.lock; lock.lock(); try { //获取原始集合 Object[] elements = getArray(); int len = elements.length; //复制一个新集合 Object[] newElements = Arrays.copyOf(elements, len + 1); newElements[len] = e; //替换原始集合为新集合 setArray(newElements); return true; } finally { //释放锁 lock.unlock(); } }
3、了解CopyOnWriteArrayList底层?CopyOnWriteArrayList与Collections.synchronizedList有什么区别?
CopyOnWriteArrayList底层实现:
CopyOnWriteArrayList在执行修改操作的时候,会复制一份新的数组数据,代价昂贵,修改过来将原来的集合指向新的集合完成操作;
add添加:
在添加的时候是需要加锁的,否则多线程写的时候会Copy出N个副本出来;使用ReentrantLock保证多线程环境下的集合安全;
public boolean add(E e) { //获取了一把锁 final ReentrantLock lock = this.lock; //加锁 lock.lock(); try { //获取当前数组数据,给elements Object[] elements = getArray(); //记录当前数组的长度 int len = elements.length; //复制一个新的数组 Object[] newElements = Arrays.copyOf(elements, len + 1); /将数据填入到新数组当中 newElements[len] = e; //将当前array指针指向到新的数据 setArray(newElements); return true; } finally { //释放锁 lock.unlock(); } }
get读取:
读的时候没有加锁,如果读的时候有多个线程正在向CopyOnWriteArrayList添加数据,读还是会读到旧的数据,因为写的时候不会锁住旧的CopyOnWriteArrayList;
public E get(int index) { return get(getArray(), index); }
CopyOnWriteArrayList应用场景:
适用于读取操作远大于写操作场景(底层get读取没有加锁,直接获取)
Collections.synchronizedList几乎底层方法都加上了synchronized的锁;
场景:
写操作的性能比CopyOnWriteArrayList要好,但是读取的性能不如CopyOnWriteArrayList;
4.CopyOnWriteArrayList设计思想是怎样的,有什么缺点?
设计思想:读写分离,最终一致;
缺点:
内存占用问题:由于写时复制,内存中就会出现两个对象占用空间,如果对象大则容易发生Young GC和Full GC;
数据一致问题:CopyOnWriteArrayList容器只能保证数据最终一致性,不能保证数据实时一致性;
5.说一下ArrayList扩容机制是怎样的?
1.7以及之前版本JDK,默认的大小为10;
1.8版本集合大小如果创建时没有指定,则默认为0;若已经指定集合大小,则初始值为当前指定的大小;
当第一次添加数据的时候,集合大小扩容为10,第二次以及后续每次按照int oldCapacity=elementData.length; newCapacity = oldCapacity+(oldCapacity>>1),就是其容量扩展为原来容量的1.5倍;
属性
默认初始值的大小
private static final int DEFAULT_CAPACITY = 10;
默认的空对象数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
实际存储数据的数组
transient Object[] elementData; // non-private to simplify nested class access
无参构造器
public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; }
扩容机制
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }
//ensureCapacityInternal方法接受了size+1作为minCapacity,并且判断如果数组是空数组,那么10和minCapacity的较大值就作为新的minCapacity。 private void ensureCapacityInternal(int minCapacity) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); } ensureExplicitCapacity(minCapacity); }
//判断传入的minCapacity和elementData.length的大小,如果elementData.length大于minCapacity,说明数组容量够用,就不需要进行扩容, //反之,则传入minCapacity到grow()方法中,进行扩容 private void ensureExplicitCapacity(int minCapacity) { modCount++; // overflow-conscious code //如果其元素个数大于其容量,则进行扩容; if (minCapacity - elementData.length > 0) grow(minCapacity); }
private void grow(int minCapacity) { // overflow-conscious code //原来的容量 int oldCapacity = elementData.length; //新的容量,原来容量的1.5倍 int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; //如果大于ArrayList可以允许的最大容量,则设置为最大容量 if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: //最终进行扩容,生成一个1.5倍元素 elementData = Arrays.copyOf(elementData, newCapacity); }
进入grow()方法,会将newCapacity设置为旧容量的1.5倍,这也是ArrayList每次扩容都为原来的1.5倍的由来。然后进行判断,如果newCapacity小于minCapacity,那么就将minCapacity的值赋予newCapacity。
然后在检查新容量是否超出了定义的容量,如果超出则调用hugeCapacity方法,比较minCapacity和MAX_ARRAY_SIZE的值;如果minCapacity大,那么新容量为Integer。MAX_VALUE,否则新容量为MAX_ARRAYSIZE。最后调用Arrays.cpoyOf传递elementData和新容量,返回新的elementData;