方向:java开发 —应届
Q:说说面向对象编程思想?
A:面向对象是一种编程思想,也许和面向过程对比一下会好一些:面向过程编程,更注重函数功能的开发,面向对象则以java为代表,通过规定类,属性,方法;然后实例化并执行方法来实现功能。
面向对象还拥有三种特性,`继承`,`封装`,`多态`,其中`封装`是面向对象和面向过程思想共有的;
ps:
继承: 继承的主要目的是实现方法的多态性和代码的可重用性
多态: 多态是为了解决现实生活中的情况的多样性问题, 根据不同的条件, 做出对应的行为
封装: 封装就是把属性和方法封装到一个类中, 通过方法来修改和执行业务, 有利于后期的修改和维护
面向对象和面向过程的区别:
面向过程:将问题分解成步骤,然后按照步骤实现函数,执行时依次调用函数。数据和对数据的操作是分离的。
面向对象:将问题分解成对象,描述事物在解决问题的步骤中的行为。对象与属性和行为是关联的。
面向过程的优点是性能比面向对象高,不需要面向对象的实例化;缺点是不容易维护、复用和扩展。
面向对象的优点是具有封装、继承、多态的特性,因而容易维护、复用和扩展,可以设计出低耦合的系统;缺点是由于需要实例化对象,因此性能比面向过程低。
Q:那说说多态和重载吧
A:多态是为了应对多种情况而出现的,具体由重写和重载方法的形式来表现出来,重写,字面意思,重新书写,是子类使用父类的方法并进行修改的意思,重写方法时其方法名,参数类型和参数个数都是不变的;重载,是局限于本类的一种方式,同一种行为,比如eat(),可以制定多种实现方式,eat(素食);eat(肉食);eat(用叉子,用筷子),等等,参数名相同但是参数类型和参数个数都不能相同,重载可以提高代码可读性,避免我们在代码里看到eat1(),eat2(),eat3().....eat10086()
Q:集合与数组的区别?
A:首先,数组是静态的,创建后长度不可改变(至少java是这样,js那个另说....),只能存储单一的数据类型,而集合的长度可以动态扩容,存放的类型可以是多种;
事实上,数组可以理解为同一类型的集合,它基本所有数据类型都可以存储,而集合是无法存储基本数据类型的,不过包装类可以
Q:这里有一个算法问题,List<>集合中存储了很多很多的字符串,他们的长度(大小)都很短,我想删除其中的所有特定元素,怎么做时间复杂度会低一些?
A:从List中删除元素,不能通过索引的方式遍历后删除,如果出现重复元素的话,直接使用for循环会导致删除不干净的问题,所以只能使用迭代器的remove,
Iterator<String> it = data.iterator(); while (it.hasNext()) { String item = it.next(); if ("cde".equals(item)) { it.remove(); } }
如果数百万个元素中想要删除的特定元素是随机分布,那么怎么查找效率应该都不会太高(当然遍历肯定效率是很低的),而且用迭代器Iterator不用担心因为删除造成的元素前移报错;听说从后向前遍历可以避免删除造成的内存移动,也就是:it.previous()方法
(所以这个应该不算是算法问题吧....小声,这个题我可能是理解不太到位,也许还有其余方法,暂时先这样写上去hh)
Q1:你了解hashmap吗,Q2:为什么hashmap是线程不安全?
A1:hashmap是Map的衍生,也是map接口的实现类,底层为:数组+链表实现(jdk1.8后采用数组+链表+红黑树的数据结构),以键值对的形式存储,存储数据的时候,是取的key值的哈希值,然后计算数组下标,再通过哈希函数计算存储地址;根据hash函数来实现映射关系,HashMap用Key的哈希值来存储和查找键值对。当插入一个value时,HashMap会计算Key的哈希值然后把value和这个哈希值相关联。
- 取关键字被某个不大于散列表长度 m 的数 p 求余,得到的作为散列地址。
- 即 H(key) = key % p, p < m。
hashmap是线程不安全的,并且k-v可以为null;
A2(关于线程安全问题):首先,hashmap是存储在一个数组(哈希表)中,数组里每个下标都对应一个桶位,每个桶位下都有很多entry对象(entry表示实体:也就是k-v),同一个桶下的entry对象的hash值(K,key)都相等,这些entry对象组成了一个Entry链表,(图片引用https://blog.csdn.net/u011277123/article/details/91524064)
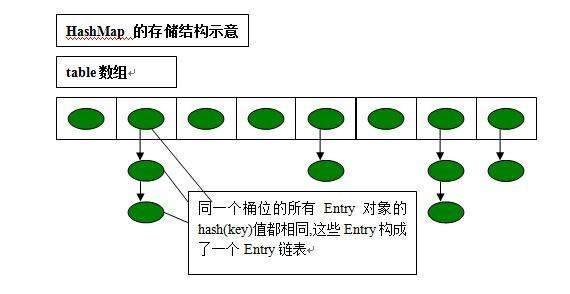
1.链表是为了解决可能出现的hash冲突而存在的,(而当链表长度大于8的时候会转化为红黑树,因为每次遍历链表效率太低,红黑树时间复杂度为logn ,这个先不提);
2.在源码中有一种结构:Node<K,V>,node即链表节点,我们数据结构中都学习过,链表插入元素有头插法和尾插法,插入可能会导致线程不安全,下面会解释
3.HashMap的扩容机制就是重新申请一个容量是当前的2倍的桶数组,即resize操作,这个操作也可能导致线程不安全,下面会说
如果多个线程,在某一时刻同时操作HashMap并执行put操作,而有大于两个key的hash值相同,如图中a1、a2,这个时候需要解决碰撞冲突,而解决冲突先不提,暂且不讨论是从链表头部插入还是从尾部初入,这个时候两个线程如果恰好都取到了对应位置的头结点e1,而最终的结果可想而知,a1、a2两个数据中势必会有一个会丢失,
线程不安全体现在很多方面:
第一:put的时候导致的多线程数据不一致
if ((p = tab[i = (n - 1) & hash]) == null) // 如果没有hash碰撞则直接插入元素
Q:TCP/UDP协议区别(中间穿插提到了TCP三次握手)
2.每条TCP传输连接只能有两个端点,只能进行点对点的数据传输,不支持多播和广播传输方式
3.TCP不像UDP一样那样一个个报文独立地传输,而是在不保留报文边界的情况下以字节流方式进行传输
4.可靠传输:对于可靠传输,判断丢包,误码靠的是TCP的段编号以及确认号。TCP为了保证报文传输的可靠,就给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已成功收到的字节发回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据(假设丢失了)将会被重传
UDP:
1.UDP面向无连接,想发就发(太放肆了..)
2.UDP 提供了单播,多播(1对多),广播的功能
3.只是搬运报文,并不对报文进行拆分处理
4.不可靠(想发就发,也不拆分处理,结果可想而知)
TCP发送报文三次握手:
第一次握手
客户端向服务端发送连接请求报文段。报文段中包含数据的 通讯初始序号(SYN)。请求发送后,客户端便进入 SYN-SENT (发送)状态。
第二次握手
服务端收到连接请求报文段后,如果同意连接,则会发送一个应答,该应答中也会包含自身的数据通讯初始序号(SYN+ACK),发送完成后便进入 SYN-RECEIVED 状态。
第三次握手
当客户端收到连接同意的应答后,还要向服务端发送一个确认报文(ACK)。客户端发完这个报文段后便进入 ESTABLISHED 状态(表示已建立连接状态),服务端收到这个应答后也进入 ESTABLISHED 状态,此时连接建立成功。
握手与挥手次数都是有理由的,为了避免网络波动造成的信号丢失,三次握手以及断开的第四次挥手是有必要的;
TCP断开连接三次握手+第四次挥手
第一次握手
客户端 认为数据发送完成,则它需要向服务端发送连接释放请求(FIN)。
第二次握手
服务器端收到连接释放请求后,会告诉应用层要释放 TCP 链接。然后会发送 ACK 包,并进入 CLOSE_WAIT 状态,此时表明 A 到 B 的连接已经释放,不再接收 A 发的数据了。但是因为 TCP 连接是双向的,所以 服务器端仍旧可以发送数据给 A。
第三次握手
服务器端 如果此时还有没发完的数据会继续发送,完毕后会向 A 发送连接释放请求(FIN),然后 B 便进入 LAST-ACK 状态。
第四次握手(挥手)
A 收到释放请求后,向 B 发送确认应答,此时 A 进入 TIME-WAIT 状态。该状态会持续 2MSL(最大段生存期,指报文段在网络中生存的时间,超时会被抛弃) 时间,若该时间段内没有 B 的重发请求的话,就进入 CLOSED 状态。当 B 收到确认应答后,也便进入 CLOSED 状态。
Q:你了解堆和栈这两种存储方式吗?
A:(当时很糊涂就是说了说数据结构上的不同),栈是先入后出,不太自由,堆分为大顶堆和小顶堆,堆的存取相比栈来说是很随意的。
内存分配中的栈和堆
百度百科中的内存堆栈介绍:
堆栈空间分配
栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
堆栈缓存方式
栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放。
堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
Q:向数据库表中添加新的字段
A:添加 alter table 表名 add 新字段名 varchar(100) default null COMMENT 'xxxxx' ;
修改字段名 alter table 表名 change 旧字段名 新字段名 旧数据类型;
修改字段数据类型 alter table 表名 modify 字段名 数据类型;
删除 alter table 表名 drop 要删除的属性名;
Q:int和Integer
A:int是一种基本数据类型,Integer是其的包装类,两个new出来的Integer变量不相等(因为是不同对象,地址都不一样);int默认值是0,Integer默认值是null,
Q:基本数据类型?
A:byte,short,int,long,float,double,boolean,char,除此之外都是引用类型
To be continued.....