一.字符串处理函数
我们从文件中将数据读取出来以后,很多情况下并不是直接将数据打印出来,而是要做相应的处理。例如:去掉空格等一些特殊的符号,对一些内容进行替换等。
这里就涉及到对一些字符串的处理。在对字符串进行处理时,需要借助于包"strings"。
下面讲解一下常用的字符串处理函数:
(1)Contains
func Contains(s, substr string) bool
功能:字符串s中是否包含substr,返回bool值
演示如下:
func main() {
str := "hellogo"
fmt.Println(strings.Contains(str, "go"))
fmt.Println(strings.Contains(str, "abc"))
}
结果如下:
true false
(2)Join
func Join(a []string, sep string) string
功能:将一系列字符串连接为一个字符串,之间用sep来分隔。
演示如下:
func main() {
s := []string{"abc", "hello", "mike", "go"}
buf := strings.Join(s, "|")
fmt.Println("buf = ", buf)
}
结果如下:
buf = abc|hello|mike|go
(3)Index
func Index(s, sep string) int
功能:子串sep在字符串s中第一次出现的位置,不存在则返回-1。
演示如下:
func main() {
fmt.Println(strings.Index("hellogohelloworld", "ll"))
fmt.Println(strings.Index("hellogohelloworld", "abc"))
}
结果如下:
2 -1
(4)Repeat
func Repeat(s string, count int) string
功能:返回count个s串联的字符串。
演示如下:
func main() {
buf := strings.Repeat("go", 3)
fmt.Println("buf = ", buf)
}
结果如下:
buf = gogogo
(5)Repalce
func Replace(s, old, new string, n int) string
功能:在s字符串中,把old字符串替换为new字符串,n表示替换的次数,小于0表示全部替换。
演示如下:
func main() {
fmt.Println(strings.Replace("oink onik onik", "k", "ky", 2))
fmt.Println(strings.Replace("onik onik onik", "onik", "moo", -1))
}
结果如下:
oinky oniky onik moo moo moo
(6)Split
func Split(s, sep string) []string
功能:用去掉s中出现的sep的方式进行分割,会分割到结尾,并返回生成的所有片段组成的切片(每一个sep都会进行一次切割,即使两个sep相邻,也会进行两次切割)。如果sep为空字符,Split会将s切分成每一个unicode码值一个字符串。
演示如下:
func main() {
buf := "hello@name@go@milk"
slice := strings.Split(buf, "@")
fmt.Println(slice)
}
(7)Trim
func Trim(s string, cutset string) string
功能:在s字符串的头部和尾部去除cutset指定的字符串,常用于去掉字符串首位空格。
演示如下:
func main() {
str := " hello worldand go "
fmt.Println(strings.Trim(str, " ")) //
}
结果如下:
hello worldand go
(8) Fields
func Fields(s string) []string
功能:去除s字符串的空格符,并且按照空格分割返回切片。
演示如下:
func main() {
str := " hello worldand go "
fmt.Println(strings.Fields(str))
}
结果如下:
[hello worldand go]
(9)HasPrefix
func HasPrefix(s, prefix string) bool
功能:判断s是否有前缀字符串prefix。
演示如下:
func main() {
str := "hello world and hello go"
fmt.Println(strings.HasPrefix(str, "hello"))
fmt.Println(strings.HasPrefix(str, "world"))
}
结果如下:
true false
(10)HasSuffix
func HasSuffix(s, suffix string) bool
功能:判断s是否有后缀字符串suffix。
演示如下:
func main() {
str := "hello world and hello go"
fmt.Println(strings.HasSuffix(str, "go"))
fmt.Println(strings.HasSuffix(str, "and"))
}
结果如下:
true false
二.字符串转换函数
2.1 字符串和字符切片的转换
字符串本身就是一个字符切片,将字符串转成字符切片,可以通过强制类型转换。
语法是:[]byte(字符串)
演示如下:
func main() {
str := "hello world"
s := []byte(str) //将字符串转换成字符切片
fmt.Println("slice = ", s)
fmt.Printf("type(s) = %T
", s)
}
结果如下:
slice = [104 101 108 108 111 32 119 111 114 108 100] type(s) = []uint8
我们可以通过for循环来输出字符切片中的每个字符:
func main() {
str := "hello world"
s := []byte(str)
for k, v := range s {
fmt.Printf("index:%d,value:%c
", k, v)
}
}
结果如下:
index:0,value:h index:1,value:e index:2,value:l index:3,value:l index:4,value:o index:5,value: index:6,value:w index:7,value:o index:8,value:r index:9,value:l index:10,value:d
字符串也可以通过下标的方式进行截取,截取后得到的还是字符串。
语法是:字符串[n:m],跟切片的截取方式一样,左闭右开,演示如下:
func main() {
var str = "hello world"
newstr := str[:5]
fmt.Println(newstr)
fmt.Printf("%T
", newstr)
}
结果如下:
hello string
但要注意,字符串是不能通过下标来修改其内容的。
func main() {
var str = "hello world"
str[0] = 'H' //这样是错误的
fmt.Println(str)
}
会得到如下报错:
cannot assign to str[0]
下面再看一下字符串的内存布局,先看一下下面的代码:
func main() {
var str = "helloworld"
var str2 = "a"
fmt.Println(unsafe.Sizeof(str))
fmt.Println(unsafe.Sizeof(str2))
}
结果如下:
16 16
我们发现,长度明显不同的两个字符串,在内存中都占16个字节,这是因为字符串在内存中由两部分组成,分别是一个指向字符串存储数据的指针和字符串的长度,如下图。
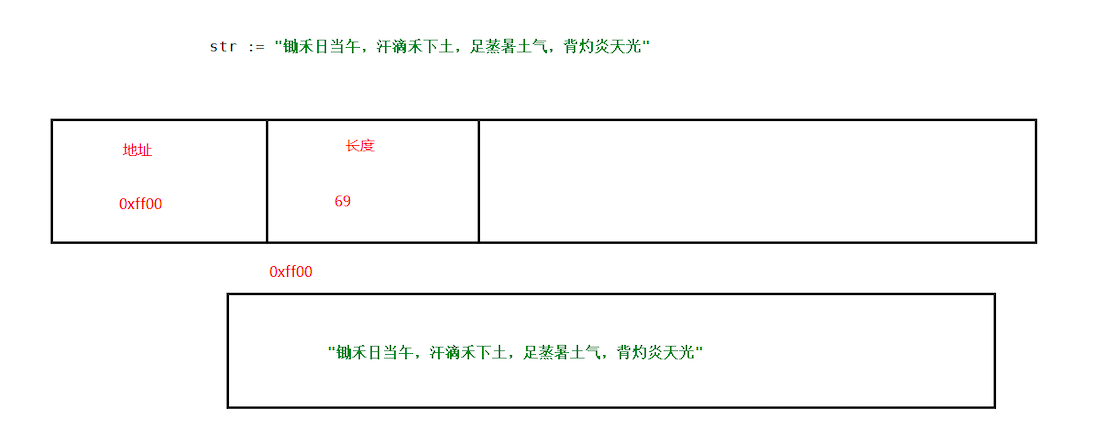
下面是go源码中对字符串的定义:
type stringStruct struct {
str unsafe.Pointer
len int
}
现在我们只需记住字符串在内存中占16个字节即可。
字符切片转换成字符串也可以通过强制类型转化。
语法是:string(字符切片)
演示如下:
func main() {
slice := []byte{'h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd'}
//字符切片转化成字符串
//强制类型转化
str := string(slice)
fmt.Println(str)
}
结果如下:
helloworld
GO语言也提供了字符串与其它类型之间相互转换的函数。相应的字符串转换函数都在"strconv"包。
2.2 其他类型转换成字符串
(1)FormatBool
func FormatBool(b bool) string
功能:bool类型转换为字符串类型
演示如下:
func main() {
str := strconv.FormatBool(true)
str2 := strconv.FormatBool(false)
//%q是一个占位符,表示输出一个带双引号的字符串
fmt.Printf("str = %q
", str)
fmt.Printf("str2 = %q
", str2)
}
结果如下:
str = "true" str2 = "false"
(2)Itoa
func Itoa(i int) string
功能:将int类型转换成字符串类型
演示如下:
func main() {
a := 10
str := strconv.Itoa(a)
//%q是一个占位符,表示输出带双引号的字符串
fmt.Printf("str = %q
", str)
}
结果如下:
str = "10"
(3)FormatFloat
func FormatFloat(f float64, fmt byte, prec, bitSize int) string
功能:将浮点类型转换成字符串类型
bitSize表示f的来源类型(32:float32、64:float64),会据此进行舍入。
fmt表示格式:'f'(-ddd.dddd)、'b'(-ddddp±ddd,指数为二进制)、'e'(-d.dddde±dd,十进制指数)、'E'(-d.ddddE±dd,十进制指数)、'g'(指数很大时用'e'格式,否则'f'格式)、'G'(指数很大时用'E'格式,否则'f'格式),这里常用的是'f'。
prec控制精度(排除指数部分):对'f'、'e'、'E',它表示小数点后的数字个数;对'g'、'G',它控制总的数字个数。如果prec 为-1,则代表使用最少数量的、但又必需的数字来表示f。
演示如下:
func main() {
i := 3.1415926
str := strconv.FormatFloat(i, 'f', 2, 64)
//%q是一个占位符,表示输出带双引号的字符串
fmt.Printf("str = %q
", str)
}
结果如下:
str = "3.14"
2.3 字符串转换成其他类型
(1)ParseBool
func ParseBool(str string) (value bool, err error)
功能:将字符串类型转换成bool类型;它接受1、0、t、f、T、F、true、false、True、False、TRUE、FALSE;否则返回错误。
演示如下:
func main() {
str := "true"
res, err := strconv.ParseBool(str)
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("res = %t
", res)
fmt.Printf("type(res) = %T
", res)
}
}
结果如下:
res = true type(res) = bool
(2)Atoi
func Atoi(s string) (i int, err error)
功能:将字符串类型转换成int类型。
演示如下:
func main() {
str := "110"
res, err := strconv.Atoi(str)
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("res = %d
", res)
fmt.Printf("type(res) = %T
", res)
}
}
结果如下:
res = 110 type(res) = int
(3)ParseFloat
func ParseFloat(s string, bitSize int) (f float64, err error)
功能:将字符串类型转换成浮点类型。
如果s合乎语法规则,函数会返回最为接近s表示值的一个浮点数。bitSize指定了期望的接收类型,32是float32(返回值可以不改变精确值的赋值给float32),64是float64。
演示如下:
func main() {
str := "3.1415926"
res, err := strconv.ParseFloat(str, 64)
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("res = %f
", res)
fmt.Printf("type(res) = %T
", res)
}
}
结果如下:
res = 3.141593 type(res) = float64
2.4 其他类型转换成字符切片
(1)AppendBool
func AppendBool(dst []byte, b bool) []byte
功能:将bool类型转换成字符切片。
演示如下:
func main() {
slice := make([]byte, 0, 1024)
slice = strconv.AppendBool(slice, true)
fmt.Println("slice = ", slice)
for i, val := range slice {
fmt.Printf("index = %d,value = %c
", i, val)
}
}
结果如下:
slice = [116 114 117 101] index = 0,value = t index = 1,value = r index = 2,value = u index = 3,value = e
(2)AppendInt
func AppendInt(dst []byte, i int64, base int) []byte
功能:将int64类型转换成字符切片。
其中形参i是int64类型的。
base指定进制(2到36),如果base为0,则会从字符串前置判断,"0x"是16进制,"0"是8进制,否则是10进制。
演示如下:
func main() {
slice := make([]byte, 0, 1024)
slice = strconv.AppendInt(slice, 1234, 10)
fmt.Println("slice = ", slice)
for i, val := range slice {
fmt.Printf("index = %d,value = %c
", i, val)
}
}
结果如下:
slice = [49 50 51 52] index = 0,value = 1 index = 1,value = 2 index = 2,value = 3 index = 3,value = 4
(3)AppendFloat
func AppendFloat(dst []byte, f float64, fmt byte, prec int, bitSize int) []byte
功能:将浮点类型转换成字符切片。
bitSize表示f的来源类型(32:float32、64:float64),会据此进行舍入。
fmt表示格式:'f'(-ddd.dddd)、'b'(-ddddp±ddd,指数为二进制)、'e'(-d.dddde±dd,十进制指数)、'E'(-d.ddddE±dd,十进制指数)、'g'(指数很大时用'e'格式,否则'f'格式)、'G'(指数很大时用'E'格式,否则'f'格式),这里常用的是'f'。
prec控制精度(排除指数部分):对'f'、'e'、'E',它表示小数点后的数字个数;对'g'、'G',它控制总的数字个数。如果prec 为-1,则代表使用最少数量的、但又必需的数字来表示f。
演示如下:
func main() {
slice := make([]byte, 0, 1024)
slice = strconv.AppendFloat(slice, 3.1415, 'f', 2, 64)
fmt.Println("slice = ", slice)
for i, val := range slice {
fmt.Printf("index = %d,value = %c
", i, val)
}
}
结果如下:
slice = [51 46 49 52] index = 0,value = 3 index = 1,value = . index = 2,value = 1 index = 3,value = 4
三. Map
前面我们学习了GO语言中数组,切片类型。我们要从数组或切片中取出某一特定值时需要知道其下标,例如:
func main() {
names := []string{"张三", "李四", "王五", "赵六", "钱七"}
fmt.Println(names[2])
}
如果我们想取出"王五",就需要数其下标是多少。切片或数组的长度如果较短还能这么做,但如果切片或数组中的元素很多,这么做就会很麻烦。那有没有一种结构能够帮我们快速的取出数据呢?就是字典结构。
说道字典大家首先想到的就是:

在使用新华字典查询某个字,我们一般都是根据前面的部首或者是拼音来确定出要查询的该字在什么位置,然后打开对应的页码,查看该字的解释。
GO语言中的字典结构是有键和值构成的。
所谓的键,就类似于新华字典的部首或拼音,可以快速查询出对应的数据。
如下图所示:
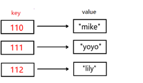
通过该图,发现某个键(key)都对应的一个值(value),如果现在要查询某个值,直接根据键就可以查询出某个值。
在这里需要注意的就是 字典中的键是不允许重复的,就像身份证号一样。
3.1 map的定义和初始化
map[keyType]valueType
定义字典结构使用map关键字,[ ]中指定的是键(key)的类型,后面紧跟着的是值的类型。
键的类型,必须是支持==和!=操作符的类型,切片、函数以及包含切片的结构类型不能作为字典的键,使用这些类型会造成编译错误:
func main() {
var dict map[[]string]int /error
fmt.Println(dict)
}
报错如下:
invalid map key type []string
下面定义一个字典m,键的类型是整型,值的类型是字符串。
func main() {
var m map[int]string
fmt.Println(m)
}
定义完后,直接打印,结果为空map。
map[]
注意:字典中不能使用cap函数,只能使用len( )函数。len( )函数返回map拥有的键值对的数量
func main() {
var m map[int]string
fmt.Println(len(m))
}
以上代码值为0,也就是没有值。
但此时的map是无法无法创建数据,因为内存地址编号0-255都被系统占用,无法读写。
注:map如果想使用,就必须先初始化。
map的初始化有两种方法:
(1)在声明map的同时直接为其初始化赋值:
func main() {
var m map[int]string = map[int]string{1: "a", 2: "b", 3: "c"}
fmt.Println("m = ", m)
fmt.Println("len(m) = ", len(m))
}
此时的map是可以为其创建数据的,创建方法是:map名[key] = value,但要注意map中的key是唯一的,当你新添加的数据的key已在map中存在,这就相当于修改map中key对应的value值,演示如下:
func main() {
var m map[int]string = map[int]string{1: "a", 2: "b", 3: "c"}
fmt.Println("m = ", m)
//为map添加数据
m[4] = "d"
m[5] = "e"
fmt.Println("m = ", m)
//如果key重复,表示修改值
m[3] = "f"
fmt.Println("m = ", m)
}
结果如下:
m = map[1:a 2:b 3:c] m = map[1:a 2:b 3:c 4:d 5:e] m = map[1:a 2:b 3:f 4:d 5:e]
(2)可以使用make为其初识化,语法是:make(map[keyType]valueType)
func main() {
//使用自动推导类型创建map
m := make(map[int]string)
fmt.Println("m = ", m)
fmt.Println("len(m) = ", len(m))
}
通过make初始化的map,也是空的,但可以存储数据:
func main() {
//使用自动推导类型创建map
m := make(map[int]string)
fmt.Println("m = ", m)
//为map添加数据
m[1001] = "路飞"
m[1002] = "索隆"
m[1003] = "山治"
m[1004] = "乌索普"
m[1005] = "鹰眼"
//如果key重复,表示修改值
m[1003] = "白胡子"
fmt.Println("m = ", m)
}
map可以直接使用键完成赋值,再次强调键是唯一的,这里一定要注意:map是无序的,我们无法决定它的返回顺序,所以,每次打印结果的顺利有可能不同。
3.2 打印字典中的值
(1)可以直接通过键输出,如下所示:
func main() {
//自动推导类型创建map
m := map[int]string{1001: "刘备", 1002: "关羽", 1003: "张飞", 1004: "赵云", 1005: "马超", 1006: "黄忠"}
fmt.Println("m[1001] = ", m[1001])
fmt.Println("m[1002] = ", m[1002])
fmt.Println("m[1003] = ", m[1003])
fmt.Println("m[1004] = ", m[1004])
}
结果如下:
m[1001] = 刘备 m[1002] = 关羽 m[1003] = 张飞 m[1004] = 赵云
(2)通过循环遍历的方式输出:
func main() {
//自动推导类型创建map
m := map[int]string{1001: "刘备", 1002: "关羽", 1003: "张飞", 1004: "赵云", 1005: "马超", 1006: "黄忠"}
//第一个返回值是key,第二个返回值是value,遍历结果是无序的
for key, value := range m {
fmt.Printf("key = %d,value = %s
", key, value)
}
}
结果如下:
key = 1002,value = 关羽 key = 1003,value = 张飞 key = 1004,value = 赵云 key = 1005,value = 马超 key = 1006,value = 黄忠 key = 1001,value = 刘备
3.3 map中key的操作
(1)在map中如果查询一个不存在的key,则输出的值为空字符串。
func main() {
//自动推导类型创建map
m := map[int]string{1001: "刘备", 1002: "关羽", 1003: "张飞", 1004: "赵云", 1005: "马超", 1006: "黄忠"}
if m[1007] == "" {
fmt.Println(true)
} else {
fmt.Println(false)
}
}
结果如下:
true
(2)判断map中的key是否存在,可以使用value,status := map[key]来判断,如果map中的key存在,则会返回key对应的value和true,否则只会返回false
func main() {
//自动推导类型创建map
m := map[int]string{1001: "刘备", 1002: "关羽", 1003: "张飞", 1004: "赵云", 1005: "马超", 1006: "黄忠"}
if value, status := m[1002]; status {
fmt.Printf("该key在map中存在,对应的值为%s
", value)
} else {
fmt.Println("该key在map中不存在")
}
}
结果如下:
该key在map中存在,对应的值为关羽
3.4 删除map中的某个元素
map可以根据键,删除对应的元素,也是非常的方便,方法是delete(map名,key).
func main() {
//自动推导类型创建map
m := map[int]string{1001: "刘备", 1002: "关羽", 1003: "张飞", 1004: "赵云", 1005: "马超", 1006: "黄忠"}
fmt.Println(m)
delete(m, 1003)
fmt.Println(m)
}
结果如下:
map[1001:刘备 1002:关羽 1003:张飞 1004:赵云 1005:马超 1006:黄忠] map[1001:刘备 1002:关羽 1004:赵云 1005:马超 1006:黄忠]
当填写的key不存在时,delete不会报错。
func main() {
//自动推导类型创建map
m := map[int]string{1001: "刘备", 1002: "关羽", 1003: "张飞", 1004: "赵云", 1005: "马超", 1006: "黄忠"}
fmt.Println(m)
delete(m, 2000)
fmt.Println(m)
}
结果如下:
map[1001:刘备 1002:关羽 1003:张飞 1004:赵云 1005:马超 1006:黄忠] map[1001:刘备 1002:关羽 1003:张飞 1004:赵云 1005:马超 1006:黄忠]
3.5 map作为函数的参数
map作为函数参数时是地址传递(引用传递),形参可以修改实参的值。
func test(m map[int]string) {
//添加数据
m[2020] = "泰达米尔"
//修改数据
m[1002] = "白胡子"
//删除数据
delete(m, 2010)
}
func main() {
m := map[int]string{1001: "路飞", 1002: "黑胡子", 1005: "索隆", 1008: "乌索普", 2010: "艾希"}
//map作为函数参数时是地址传递(引用传递),形参可以修改实参的值
test(m)
fmt.Println(m)
}
结果如下:
map[1001:路飞 1002:白胡子 1005:索隆 1008:乌索普 2020:泰达米尔]