直播弹幕指直播间的用户,礼物,评论,点赞等消息,是直播间交互的重要手段。美拍直播弹幕系统从 2015 年 11 月到现在,经过了三个阶段的演进,目前能支撑百万用户同时在线。比较好地诠释了根据项目的发展阶段,进行平衡演进的过程。这三个阶段分别是快速上线,高可用保障体系建设,长连接演进。
一、快速上线
消息模型
美拍直播弹幕系统在设计初期的核心要求是:快速上线,并能支撑百万用户同时在线。基于这两点,我们策略是前中期 HTTP 轮询方案,中后期替换为长连接方案。因此在业务团队进行 HTTP 方案研发的同时,基础研发团队也紧锣密鼓地开发长连接系统。
直播间消息,相对于 IM 的场景,有其几个特点
-
消息要求及时,过时的消息对于用户来说不重要;
-
松散的群聊,用户随时进群,随时退群;
-
用户进群后,离线期间(接听电话)的消息不需要重发;
对于用户来说,在直播间有三个典型的操作:
-
进入直播间,拉取正在观看直播的用户列表;
-
接收直播间持续接收弹幕消息;
-
自己发消息;
我们把礼物,评论,用户的数据都当做消息来看待。经过考虑选择了 Redis 的 sortedset 存储消息,消息模型如下:
-
用户发消息,通过 Zadd,其中 score 消息的相对时间;
-
接收直播间的消息,通过 ZrangeByScore 操作,两秒一次轮询;
-
进入直播间,获取用户的列表,通过 Zrange 操作来完成;
因此总的流程是
-
写消息流程是: 前端机 -> Kafka -> 处理机 -> Redis
-
读消息流程是: 前端 -> Redis
不过这里有一个隐藏的并发问题:用户可能丢消息。
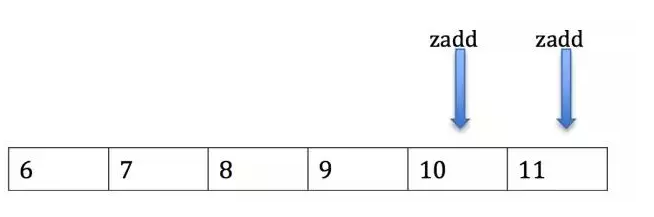
如上图所示,某个用户从第6号评论开始拉取,同时有两个用户在发表评论,分别是10,11号评论。如果11号评论先写入,用户刚好把6,7,8,9,11号拉走,用户下次再拉取消息,就从12号开始拉取,结果是:用户没有看到10号消息。
为了解决这个问题,我们加上了两个机制:
-
在前端机,同一个直播间的同一种消息类型,写入 Kafka 的同一个 partition
-
在处理机,同一个直播间的同一种消息类型,通过 synchronized 保证写入 Redis 的串行。
消息模型及并发问题解决后,开发就比较顺畅,系统很快就上线,达到预先预定目标。
上线后暴露问题的解决
上线后,随着量的逐渐增加,系统陆续暴露出三个比较严重的问题,我们一一进行解决
问题一:消息串行写入 Redis,如果某个直播间消息量很大,那么消息会堆积在 Kafka 中,消息延迟较大。
解决办法:
-
消息写入流程:前端机-> Kafka -> 处理机 -> Redis
-
前端机:如果延迟小,则只写入一个 Kafka 的partion;如果延迟大,则这个直播的这种消息类型写入 Kafka 的多个partion。
-
处理机:如果延迟小,加锁串行写入 Redis;如果延迟大,则取消锁。因此有四种组合,四个档位,分别是
-
一个partion, 加锁串行写入 Redis, 最大并发度:1
-
多个partition,加锁串行写入 Redis, 最大并发度:Kafka partion的个数
-
一个partion, 不加锁并行写入 Redis, 最大并发度: 处理机的线程池个数
-
多个partion, 不加锁并行写入 Redis,最大并发度: Kafka partition个数处理机线程池的个数
-
延迟程度判断:前端机写入消息时,打上消息的统一时间戳,处理机拿到后,延迟时间 = 现在时间 - 时间戳;
-
档位选择:自动选择档位,粒度:某个直播间的某个消息类型
问题二:用户轮询最新消息,需要进行 Redis 的 ZrangByScore 操作,redis slave 的性能瓶颈较大
解决办法:
-
本地缓存,前端机每隔1秒左右取拉取一次直播间的消息,用户到前端机轮询数据时,从本地缓存读取数据;
-
消息的返回条数根据直播间的大小自动调整,小直播间返回允许时间跨度大一些的消息,大直播间则对时间跨度以及消息条数做更严格的限制。
解释:这里本地缓存与平常使用的本地缓存问题,有一个最大区别:成本问题。
如果所有直播间的消息都进行缓存,假设同时有1000个直播间,每个直播间5种消息类型,本地缓存每隔1秒拉取一次数据,40台前端机,那么对 Redis 的访问QPS是 1000 * 5 * 40 = 20万。成本太高,因此我们只有大直播间才自动开启本地缓存,小直播间不开启。
问题三:弹幕数据也支持回放,直播结束后,这些数据存放于 Redis 中,在回放时,会与直播的数据竞争 Redis 的 cpu 资源。
解决办法:
-
直播结束后,数据备份到 mysql;
-
增加一组回放的 Redis;
-
前端机增加回放的 local cache;
解释:回放时,读取数据顺序是: local cache -> Redis -> mysql。localcache 与回放 Redis 都可以只存某个直播某种消息类型的部分数据,有效控制容量;local cache与回放 Redis 使用SortedSet数据结构,这样整个系统的数据结构都保持一致。
二、高可用保障
同城双机房部署
分为主机房和从机房,写入都在主机房,读取则由两个机房分担。从而有效保证单机房故障时,能快速恢复。
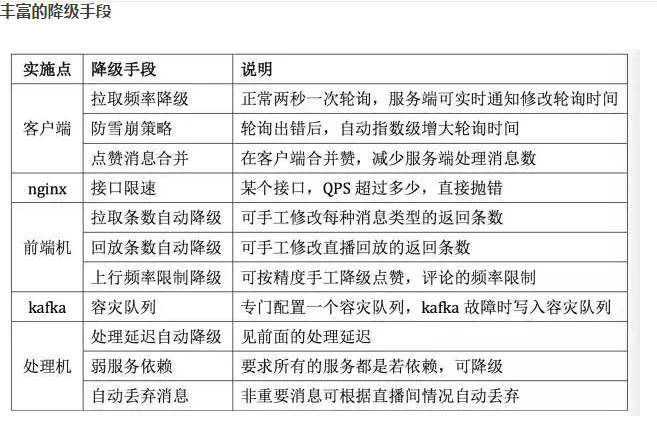
丰富的降级手段
全链路的业务监控

高可用保障建设完成后,迎来了 TFBOYS 在美拍的四场直播,这四场直播峰值同时在线人数达到近百万,共 2860万人次观看,2980万评论,26.23亿次点赞,直播期间,系统稳定运行,成功抗住压力。
使用长连接替换短连接轮询方案
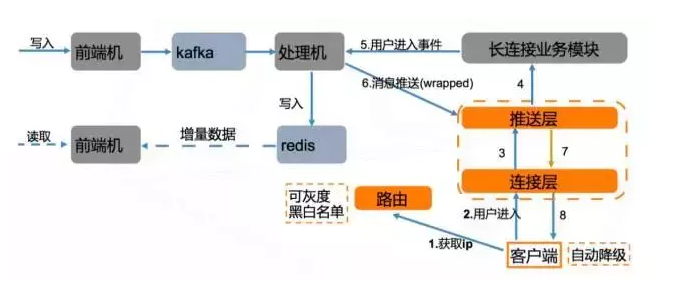
长连接整体架构图如下
详细说明:
-
客户端在使用长连接前,会调用路由服务,获取连接层IP,路由层特性:a. 可以按照百分比灰度;b. 可以对 uid,deviceId,版本进行黑白名单设置。黑名单:不允许使用长连接;白名单:即使长连接关闭或者不在灰度范围内,也允许使用长连接。这两个特性保证了我们长短连接切换的顺利进行;
-
客户端的特性:a. 同时支持长连接和短连接,可根据路由服务的配置来决定;b. 自动降级,如果长连接同时三次连接不上,自动降级为短连接;c. 自动上报长连接性能数据;
-
连接层只负责与客户端保持长连接,没有任何推送的业务逻辑。从而大大减少重启的次数,从而保持用户连接的稳定;
-
推送层存储用户与直播间的订阅关系,负责具体推送。整个连接层与推送层与直播间业务无关,不需要感知到业务的变化;
-
长连接业务模块用于用户进入直播间的验证工作;
-
服务端之间的通讯使用基础研发团队研发的tardis框架来进行服务的调用,该框架基于 gRPC,使用 etcd 做服务发现;
长连接消息模型
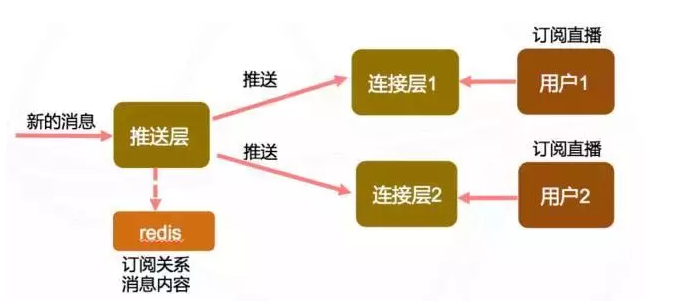
我们采用了订阅推送模型,下图为基本的介绍
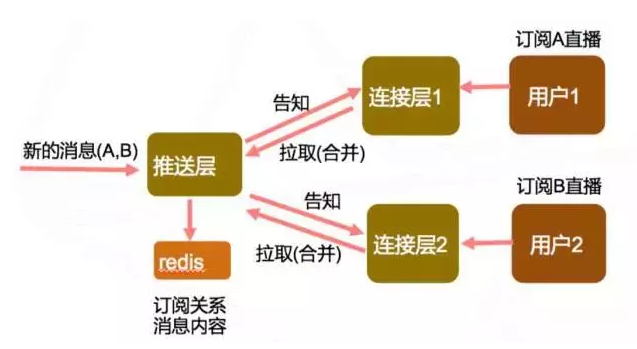
举例说明:用户1订阅了A直播,A直播有新的消息
-
推送层查询订阅关系后,知道有用户1订阅了A直播,同时知道用户1在连接层1这个节点上,那么就会告知连接层有新的消息
-
连接层1收到告知消息后,会等待一小段时间(毫秒级),再拉取一次用户1的消息,然后推送给用户1.
如果是大直播间(订阅用户多),那么推送层与连接层的告知/拉取模型,就会自动降级为广播模型。如下图所示
我们经历客户端三个版本的迭代,实现了两端(Android 与 iOS)长连接对短连接的替换,因为有灰度和黑白名单的支持,替换非常平稳,用户无感知。
总结与展望
回顾了系统的发展过程,达到了原定的前中期使用轮询,中后期使用长连接的预定目标,实践了原定的平衡演进的原则。从发展来看,未来计划要做的事情有
-
针对机房在北京,南方某些地区会存在连接时间长的情况。我们如何让长连接更靠近用户。
-
消息模型的进一步演进。