服务熔断也称服务隔离,来自于Michael Nygard 的《Release It》中的CircuitBreaker应用模式,Martin Fowler在博文CircuitBreaker中对此设计进行了比较详细说明。
本文认为服务熔断是服务降级的措施。服务熔断对服务提供了proxy,防止服务不可能时,出现串联故障(cascading failure),导致雪崩效应。服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
如下面来自Martin文中的图示:
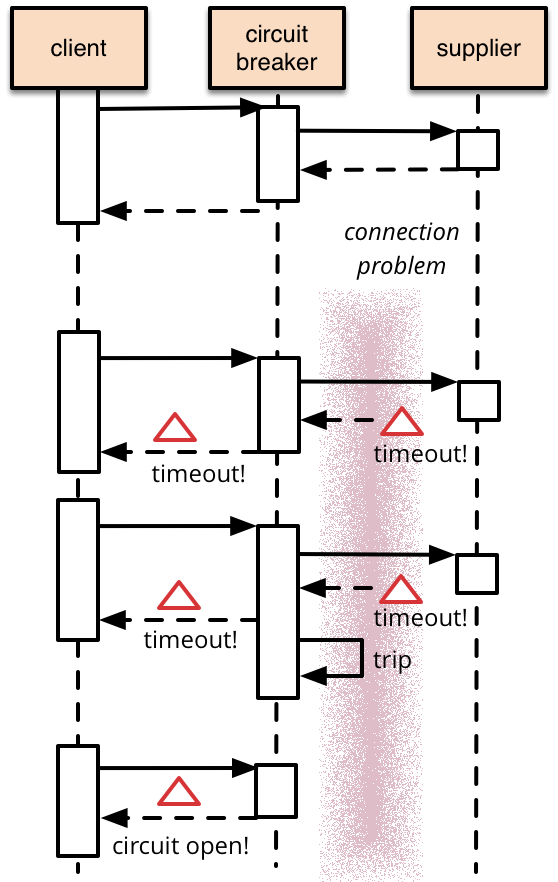
服务熔断和服务降级所考虑关注的目标也不一样,熔断是每个微服务都需要的,是一个框架级的处理,而服务降级一般是关注业务,对业务进行考虑,抓住业务的层级,从而决定在哪一层上进行处理:比如在IO层,业务逻辑层,还是在外围进行处理。
Martin设计一个状态机,代表服务的不同状态,
状态机来实现,内部模拟以下几种状态。
- 闭合(closed)状态:对应用程序的请求能够直接引起方法的调用。代理类维护了最近调用失败的次数,如果某次调用失败,则使失败次数加1。如果最近失败次数超过了在给定时间内允许失败的阈值,则代理类切换到断开(Open)状态。此时代理开启了一个超时时钟,当该时钟超过了该时间,则切换到半断开。
- 半开(Half-Open)状态。该超时时间的设定是给了系统一次机会来修正导致调用失败的错误。
- 断开(Open)状态: 在该状态下,对应用程序的请求会立即返回错误响应。
如图:
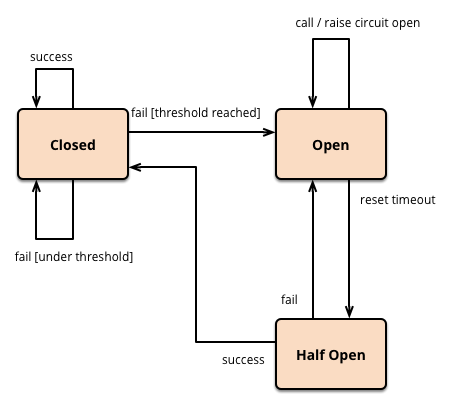
说明: 半断开(Half-Open)状态,允许对服务一定数量的请求可以去调用服务,能够有效防止正在恢复中的服务被突然而来的大量请求再次拖垮。也有称为限流模式、预防模式。如果这些请求对服务的调用成功,那么可以认为之前导致调用失败的错误已经修正,此时熔断器切换到闭合状态(并且将错误计数器重置);如果这一定数量的请求有调用失败的情况,则认为导致之前调用失败的问题仍然存在,熔断器切回到断开方式,然后开始重置计时器来给系统一定的时间来修正错误。
博主张善友认为对服务熔断的设计中要考虑包括这些设计:
异常处理:调用受熔断器保护的服务的时候,我们必须要处理当服务不可用时的异常情况。这些异常处理通常需要视具体的业务情况而定。比如,如果应用程序只是暂时的功能降级,可能需要切换到其它的可替换的服务上来执行相同的任务或者获取相同的数据,或者给用户报告错误然后提示他们稍后重试。
异常的类型:请求失败的原因可能有很多种。一些原因可能会比其它原因更严重。比如,请求会失败可能是由于远程的服务崩溃,这可能需要花费数分钟来恢复;也可能是由于服务器暂时负载过重导致超时。熔断器应该能够检查错误的类型,从而根据具体的错误情况来调整策略。比如,可能需要很多次超时异常才可以断定需要切换到断开状态,而只需要几次错误提示就可以判断服务不可用而快速切换到断开状态。
日志:熔断器应该能够记录所有失败的请求,以及一些可能会尝试成功的请求,使得的管理员能够监控使用熔断器保护的服务的执行情况。
测试服务是否可用:在断开状态下,熔断器可以采用定期的ping远程的服务或者资源,来判断是否服务是否恢复,而不是使用计时器来自动切换到半断开状态。这种ping操作可以模拟之前那些失败的请求,或者可以使用通过调用远程服务提供的检查服务是否可用的方法来判断。
手动重置:在系统中对于失败操作的恢复时间是很难确定的,提供一个手动重置功能能够使得管理员可以手动的强制将熔断器切换到闭合状态。同样的,如果受熔断器保护的服务暂时不可用的话,管理员能够强制的将熔断器设置为断开状态。
并发问题:相同的熔断器有可能被大量并发请求同时访问。熔断器的实现不应该阻塞并发的请求或者增加每次请求调用的负担。
资源的差异性:使用单个熔断器时,一个资源如果有分布在多个地方就需要小心。比如,一个数据可能存储在多个磁盘分区上(shard),某个分区可以正常访问,而另一个可能存在暂时性的问题。在这种情况下,不同的错误响应如果混为一谈,那么应用程序访问的这些存在问题的分区的失败的可能性就会高,而那些被认为是正常的分区,就有可能被阻塞。
加快熔断器的熔断操作:有时候,服务返回的错误信息足够让熔断器立即执行熔断操作并且保持一段时间。比如,如果从一个分布式资源返回的响应提示负载超重,那么应该等待几分钟后再重试。(HTTP协议定义了"HTTP 503 Service Unavailable"来表示请求的服务当前不可用,他可以包含其他信息比如,超时等)
重复失败请求:当熔断器在断开状态的时候,熔断器可以记录每一次请求的细节,而不是仅仅返回失败信息,这样当远程服务恢复的时候,可以将这些失败的请求再重新请求一次。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
注意:
服务熔断恢复重试问题:如果服务是幂等性的,则恢复重试不会有问题;而如果服务是非幂等性的,则重试会导致数据出现问题。
互联网公司Netflix,其Hystrix作为Netflix开源框架中的最受喜爱组件之一,可以用来处理依赖隔离,实现熔断机制。
在Hystrix中,最重要的class是HystrixCommand和HystrixObservableCommand。
下面是Netflix的wiki:
You can support graceful degradation in a Hystrix command by adding a fallback method that Hystrix will call to obtain a default value or values in case the main command fails. You will want to implement a fallback for most Hystrix commands that might conceivably fail, with a couple of exceptions:
- a command that performs a write operation
If your Hystrix command is designed to do a write operation rather than to return a value (such a command might normally return a void in the case of a HystrixCommand or an empty Observable in the case of a HystrixObservableCommand), there isn’t much point in implementing a fallback. If the write fails, you probably want the failure to propagate back to the caller. - batch systems/offline compute
If your Hystrix command is filling up a cache, or generating a report, or doing any sort of offline computation, it’s usually more appropriate to propagate the error back to the caller who can then retry the command later, rather than to send the caller a silently-degraded response.
Whether or not your command has a fallback, all of the usual Hystrix state and circuit-breaker state/metrics are updated to indicate the command failure.
In an ordinary HystrixCommand you implement a fallback by means of a getFallback() implementation. Hystrix will execute this fallback for all types of failure such as run() failure, timeout, thread pool or semaphore rejection, and circuit-breaker short-circuiting. The following example includes such a fallback: