1、 企业Linux运维场景数据同步方案
1.1 文件级别的异机同步方案
# scp/sftp/nc命令可以实现远程数据同步。
# 搭建ftp/http/svn/nfs 服务器,然后在客户端上也可以把数据同步到服务器。
# 搭建Samba文件共享服务,然后在客户端上也可把数据同步到服务器。
# 利用rsync/csync2/union等均可实现数据同步。
提示:union可实现双向同步,csync2可实现多机同步。以上文件同步方式如果结合定时任何或者inotify,sersync等功能,可以实现定时及实时的数据同步。
# 扩展思想:文件级别也可利用mysql,mongodb等软件作为容器实现。
#扩展思想:程序向两个服务器同时写数据,双写就是一个同步机制。
特点:简单,方便,效率和文件系统级别要差一些,但是被同步的节点可以提供访问。软件的自身同步机制(MySQL,oracle,mongdb,ttserver,redis…),文件放到数据库,同步到从库,再把文件拿出来。
1.2 文件系统级别异机同步方案
drbd同步数据
DRBD基于文件系统同步,相当于网络raid1,可以同步几乎任何业务数据。MySQL数据库的官方推荐DRBD同步数据,所有单点服务例如:NFS,MFS(DRBD),MYSQL等都可以用DRBD。
2、 MySQL主从复制
MySQL的主从复制方案,和上述文件及文件系统级别同步是类似的,都是数据的传输,只不过MySQL无需借助第三方的工具,而是其自带的同步复制功能,MySQL主从复制并不是磁盘上文件直接同步,而是逻辑的binglog日志同步到本地在应用执行的过程。
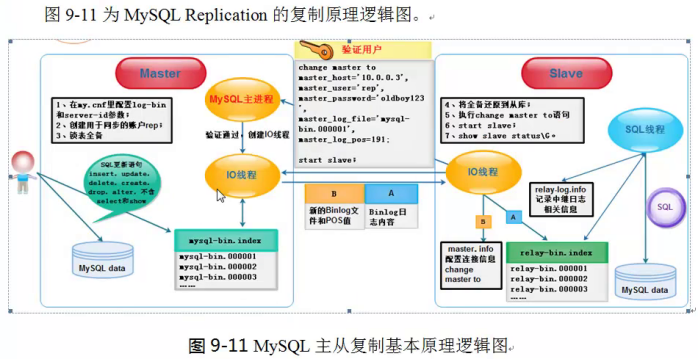
2.1、MySQL主从复制原理介绍
MySQL的主从复制是一个异步的复制过程(虽然一般感觉是实时的),数据将从一个数据库(我们称为master)复制到另外一个MySQL数据库(我们称为slave),在master和slave之间实现整个主从复制的过程是由三个线程参与完成的。其中有两个线程(SQL线程和IO线程)在slave端,另外一个线程(I/O线程)在master端。
要实现MySQL的主从复制,首先必须打开master端的binlog记录功能,否则就无法实现,因为整个复制过程实际上就是slave从master端获取binlog日志,然后再在slave上以相同顺序执行获取的binlog日志中所记录的各种SQL操作。
2.2、主从复制应用场景
A、应用场景1、主从复制实现读写分离,从服务器实现负载均衡
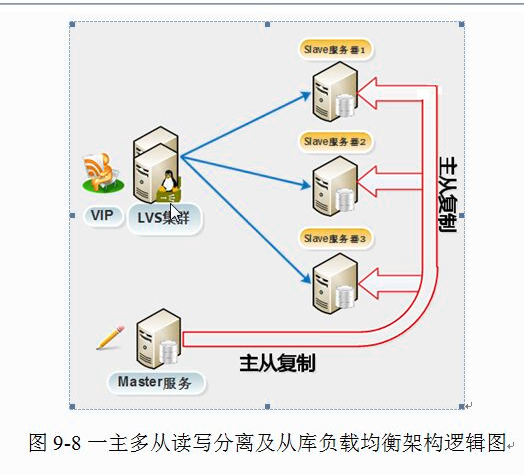
主从服务器架构可通过程序(PHP,java等)或代理软件(MySQL-proxy,amoeba)实现对用户(客户端)的请求读写分离,即让从服务器仅仅处理用户的select查询请求,降低用户查询响应时间及读写同时在主服务器带来的访问压力。对于更新的数据(例如update,insert,delete语句)仍然交给主服务器和从服务器保持实时同步。
读写分离 1.程序实现 if [select ] ##如果查询语句就连接从库 连接 从库IP PORT ELSE 连接 主库IP PORT ##其他的就连接主库 FI 2.Atlas,Maxscale、Atlas、Mycat等代理软件也可以实现读写分离功能
B、应用场景2、把多个从服务器根据业务重要性进行拆分访问
可以把几个不同的从服务器,根据公司的业务进行拆分,例如:有为外部用户提供查询服务的从服务器,有内部DBA用来数据备份的从服务器,还有为公司内部人员提供访问的后台,脚本,日志分析及供开发人员查询使用的从服务器。这样的拆分除了减轻主服务器的压力外,还可以使数据库对外部用户浏览,内部用户业务处理及DBA人员的备份等互不影响。
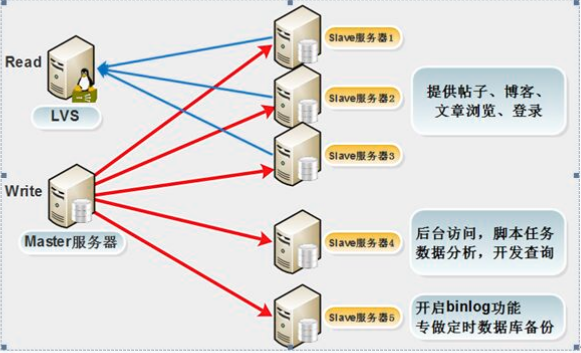
C、应用场景3、从服务器作为主服务器的实时数据备份
主从服务器架构的设置,可以大大加强MySQL数据库架构的健壮性。例如:当主服务器出现问题是,我们可以人工或设置自动切换到从服务器继续提供服务,此时从服务器的数据和宕机时的主数据库几乎是一致的。
利用MySQL的复制功能做数据备份时,在硬件故障,软件故障的场景下,该数据备份是有效的,但对于认为的执行drop,delete等语句删除数据的情况,从库的备份功能就没用了,因为从库也会执行删除的语句。因此可以做延时从库。
2.2、主从复制案例
环境:多实例 10.0.0.52 3306 10.0.0.52 3307 3306---->3307复制---->3309 ---->3008复制 3306<---->3307 架构实践: 3306---->3307
2.2.1 开启主库binlog,配置server-id
[root@db02 ~]# egrep -i "server-id|log-bin" /data/3306/my.cnf log-bin = /data/3306/mysql-bin server-id = 6 #注意id号不能一样,要区别 重启服务
开启主库binlog日志
vim /data/3306/my.cnf pid-file = /data/3306/mysql.pid log-bin = /data/3306/mysql-bin ###将此行注释去掉,然后重新启动多实例 relay-log = /data/3306/relay-bin "/data/3306/my.cnf" [dos] 72L, 1824C written [root@DB02 backup]# 从库 [root@db02 ~]# egrep -i "server-id|log-bin" /data/3307/my.cnf #log-bin = /data/3307/mysql-bin server-id = 7
2.2.2 、主库创建用户
grant replication slave on *.* to 'rep'@'172.16.1.%' identified by 'dadong123'; mysql> grant replication slave on *.* to 'rep'@'172.16.1.%' identified by 'dadong123'; Query OK, 0 rows affected (0.04 sec) mysql> select user,host from mysql.user; +------+------------+ | user | host | +------+------------+ | root | 127.0.0.1 | | rep | 172.16.1.% |
2.2.3 从主库导出数据
按照我们讲过的内容,直接取今天00点的备份就可以. mysql> flush table with read lock; ####一般大部分情况不需要锁库,因为备份的时候已经有参数备份了。 Query OK, 0 rows affected (0.00 sec) mysql> show master status; ####获取binlog日志关键点 +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000001 | 120 | | | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec) mysqldump cp/tar xtrabackup 拿到位置点是关键 mysql-bin.000001 120 [root@db02 ~]# mysqldump -B --master-data=2 --single-transaction -S /data/3306/mysql.sock -A|gzip>/data/backup/all_$(date +%F).sql.gz [root@db02 ~]# ls -l /data/backup/ 总用量 228 -rw-r--r-- 1 root root 178468 6月 28 11:11 all_2017-06-28.sql.gz 主库解锁: mysql> unlock table; Query OK, 0 rows affected (0.00 sec)
3.3.4 从库导入全备的数据
[root@db02 backup]# gzip -d all_2017-06-28.sql.gz [root@db02 backup]# mysql -S /data/3307/mysql.sock <all_2017-06-28.sql
3.3.5 找位置点,然后change master从库
[root@db02 backup]# sed -n '22p' all_2017-06-28.sql -- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=120; 进入数据库中,然后输入下面内容 CHANGE MASTER TO MASTER_HOST='172.16.1.52', ###主数据库的IP地址 MASTER_PORT=3306, ###主数据库的端口 MASTER_USER='rep', ###连接主数据库的用户名 MASTER_PASSWORD='dadong123', ####连接主数据库的密码 MASTER_LOG_FILE=' mysql-bin.000001', ###主数据库上的binlog日志 MASTER_LOG_POS=120; ###主数据库的binlog日志关键点 mysql> start slave; ###开启从库 Query OK, 0 rows affected (0.03 sec)
3.3.6 查看从库是否配置正确
mysql> show slave statusG [root@db02 backup]# mysql -S /data/3307/mysql.sock -e "show slave statusG"|egrep "_Running|Behind_Master"|head -3 Slave_IO_Running: Yes Slave_SQL_Running: Yes Seconds_Behind_Master: 0
从库的线程状态:
Slave_IO_Running: Yes #这个是I/O线程状态,I/O线程负责从库去主库读取binlog日志,并写入从库的中继日志中,状态为yes表示I/O线程工作正常。 Slave_SQL_Running: Yes #这个是SQL线程状态,SQL线程负责读取中继日志(relay-log)中的数据并转换为SQL语句应用到从数据库中,状态为YES,表示I/O线程工作正常。 Seconds_Behind_Master: 0 #这个是在复制过程中,从库比主库延迟的秒数,这个参数很重要,但企业更准确的判断主从延迟的方法为:在主库写时间戳,然后从库读取时间戳和当前数据库时间进行比较,从而认定是否延迟。
3.3.7、 reset slave清除从库信息
reset slave是各版本Mysql都有的功能,在stop slave之后使用。
主要做:
删除master.info和relay-log.info文件;
删除所有的relay log(包括还没有应用完的日志),创建一个新的relay log文件;
从Mysql 5.5开始,多了一个all参数。如果不加all参数,那么所有的连接信息仍然保留在内存中,包括主库地址、端口、用户、密码等。
这样可以直接运行start slave命令而不必重新输入change master to命令,而运行show slave status也仍和没有运行reset slave一样,有正常的输出。但如果加了all参数,那么这些内存中的数据也会被清除掉,运行show slave status就输出为空了。
运行reset slave命令需要reload权限。MHA在做故障切换时,就会在新主上运行命令RESET SLAVE /*!50516 ALL */ ,清除掉它的所有从库信息。
3、MySQL主从复制更多应用技巧实践
模拟重现故障的能力是运维人员最重要的能力。下面就模拟操作,先在从库创建一个库,然后主库创建同名的库来模拟数据冲突。


1 mysql> show slave statusG 2 3 *************************** 1. row *************************** 4 Slave_IO_State: Waiting for master to send event 5 Master_Host: 172.16.1.52 6 Master_User: rep 7 Master_Port: 3306 8 Connect_Retry: 60 9 Master_Log_File: oldboy-bin.000005 10 Read_Master_Log_Pos: 314 11 Relay_Log_File: DB01-relay-bin.000002 12 Relay_Log_Pos: 284 13 Relay_Master_Log_File: oldboy-bin.000005 14 Slave_IO_Running: Yes 15 Slave_SQL_Running: No 16 Replicate_Do_DB: 17 Replicate_Ignore_DB: 18 Replicate_Do_Table: 19 Replicate_Ignore_Table: 20 Replicate_Wild_Do_Table: 21 Replicate_Wild_Ignore_Table: 22 Last_Errno: 1007 23 Last_Error: Error 'Can't create database 'mao'; database exists' on query. Default database: 'mao'. Query: 'create database mao' 24 Skip_Counter: 0 25 Exec_Master_Log_Pos: 223 26 Relay_Log_Space: 547 27 Until_Condition: None 28 Until_Log_File: 29 Until_Log_Pos: 0 30 Master_SSL_Allowed: No 31 Master_SSL_CA_File: 32 Master_SSL_CA_Path: 33 Master_SSL_Cert: 34 Master_SSL_Cipher: 35 Master_SSL_Key: 36 Seconds_Behind_Master: NULL 37 Master_SSL_Verify_Server_Cert: No 38 Last_IO_Errno: 0 39 Last_IO_Error: 40 Last_SQL_Errno: 1007 41 Last_SQL_Error: Error 'Can't create database 'mao'; database exists' on query. Default database: 'mao'. Query: 'create database mao' 42 Replicate_Ignore_Server_Ids: 43 Master_Server_Id: 1 44 Master_UUID: c1064fa3-5b56-11e7-abcb-000c291fd8bd 45 Master_Info_File: /application/mysql-5.6.34/data/master.info 46 SQL_Delay: 0 47 SQL_Remaining_Delay: NULL 48 Slave_SQL_Running_State: 49 Master_Retry_Count: 86400 50 Master_Bind: 51 Last_IO_Error_Timestamp: 52 Last_SQL_Error_Timestamp: 170630 01:05:03 53 Master_SSL_Crl: 54 Master_SSL_Crlpath: 55 Retrieved_Gtid_Set: 56 Executed_Gtid_Set: 57 Auto_Position: 0 58 1 row in set (0.00 sec) 59 60 mysql>
3.1 解决方法1:同步指针向下移动
mysql> stop slave; ###临时停止同步开关 Query OK, 0 rows affected (0.04 sec) mysql> set global sql_slave_skip_counter=1; ##将同步指针向下移动一个,如果多次不同步,可以重复操作。 Query OK, 0 rows affected (0.00 sec) mysql> start slave; ###开启同步 Query OK, 0 rows affected (0.04 sec) mysql> show slave statusG
对于普通的互联网业务,上述的移动指针的命令操作带来的问题不是很大,当然,要在确认不影响公司业务的前提下。
若是在企业场景下,对当前业务来说,解决主从同步比主从不一致更重要,如果主从数据一致也是很重要的,那就找个时间恢复下这个从库。
主从数据不一致更重要还是保持主从同步持续状态更重要,则要根据业务选择。
这样slave就会和master同步了,主要关键点为:
Slave_IO_Running: Yes Slave_SQL_Running: Yes Seconds_Behind_Master: 0 ###0表示已经同步状态。 提示:set global sql_slave_skip_counter=n; ##n取值>0,忽略执行N个更新。 Slave_IO_Running:Yes,这是I/O线程状态,I/O线程负载从从库去主库读取binlog日志,并写入从库的中继日志中,状态为Yes表示I/O线程工作正常。 Slave_SQL_Running:Yes 这个是SQL线程状态,SQL线程负载读取中继日志(relay-log)中的数据并转换为SQL语句应用到从库数据库中,状态为Yes表示I/O线程工作正常 Seconds_Behind_Master:0 这个是在复制过程中,从库比主库延迟的描述,这个参数很重要,但企业里更准确地判断主从延迟的方法为:在主库写时间戳,然后从库读取时间戳进行比较,从而认定是否延迟。
3.2 解决方法2:跳过指定的不影响业务数据的错误。
根据可以忽略的错误号事先在配置文件中配置,跳过指定的不影响业务数据的错误。
[root@DB01 logs]# grep slave-skip /etc/my.cnf slave-skip-errors = 1032,1062,1007
4、 MySQL主从复制延迟问题原因及解决方案
问题一:一个主库的从库太多,导致复制延迟。
建议从库数量为3-5个为宜,要复制的从节点数量过多,会导致复制延迟。
问题二:从库硬件比主库差,导致复制延迟。
查看master和slave的系统配置,可能会因为机器配置的问题,包括磁盘IO,CPU,内存等各方面因素造成复制的延迟,一般发生在高并发大数据量写入场景。
问题三:慢SQL语句过多
假如一个SQL语句,执行时间是20秒,那么从执行完毕,到从库上能查到数据至少是20秒,这样就延迟了20秒了。
SQL语句的优化一般要作为常规工作不断的监控和优化,如果是单个SQL的写入时间长,可以修改后分多次写入,通过查看慢查询日志或show full processlist命令找出执行时间长的查询语句或者大的事务。
问题四:主从复制的设计问题
例如:主从复制单线程,如果主库写并发太大,来不及传送到从库就会导致延迟。
问题五:主从库之间的网络延迟。
主从库的网卡,网线,连接的交换机等网络设备都可能成为复制的瓶颈,导致复制延迟,另外,跨公网主从复制很容易导致主从复制延迟。
问题六:主库读写压力大,导致复制延迟。
主库硬件要搞好点,架构的前端要加buffer以及缓存层。
由于各种原因,mysql主从架构经常会出现数据不一致的情况出现,大致归结为如下几类 1:备库写数据 2:执行non-deterministic query 3:回滚掺杂事务表和非事务表的事务 4:binlog或者relay log数据损坏