多级存储体系
当前计算机普遍使用的存储架构即如下图:
寄存器+三级高速缓存+内存(主存)+disk(本地磁盘和外连存储)
所以可以看到我们的当前玩的内存在哪个具体位置。

高速缓存,可以做暂存,以便相关单元再次使用;再合适的时候,回写进内存,比如空间不够、周期性等
进程和内存关系
进程大小各不相同,在内存置换过程中,能否准确无误放置于内存将成为关键。(详细细节自己想,不累述)方案如下:
|
技术 |
说明 |
优势 |
劣势 |
|
固定分区 |
在系统生成阶段,内存被划分成许多静态分区。进程可装入大于等于自身大小的分区中。 |
实现简单,只需要极少的操作系统开销。 |
由于有内部碎片,对内存的使用不充分;活动进程的最大数量是固定的。 |
|
动态分区 |
分区是动态创建的,因而每个进程可装入于自身大小正好相等的分区中 |
没有内部碎片;可以更充分地使用内存 |
由于需要压缩外部碎片的开销,处理器利用率低。 |
基于以上两项技术的缺陷,发起了另外一种技术,叫伙伴系统。
相邻块可以任意拆分组合。最初合成为一个大块,当需要使用的时候,比如1MB生2个512KB,再其中1个512KB生2个256KB,直到大小约等于进程大小容量的块。当最后使用的块空闲时,块将自动合并成大块。
分页技术
- 相当于固定分区,但是块更小;
- 采用页表,映射逻辑地址到物理地址的关系,因此存储同一个进程的分区可以不连续
进程最后一个占用块可能会有内部碎片。
分段技术
- 相当于动态分区,但是块更小;
- 也采用页表技术。
同动态分区,会有较小的外部碎片。
页表技术
逻辑地址:页号+偏移量(即单个页的大小)
物理地址:页框号+偏移量
虚拟内存
受限于内存的大小瓶颈,考虑在磁盘内划定特定区域用于内存。使用I/O来换取内存空间。
细节如下:
- 需要执行的部分,才放入内存,其他部分放入虚拟内存;
- 当访问一个不再内存中的逻辑地址时,将产生一个中断;
- 为了减少中断次数,使用局部性原理,提前将程序从虚拟内存存入主存;
优势:
- 进程的大小可以大于内存空间;
- 内存可以运行更多的进程
备注:
对于进程来说,默认是可以使用所有内存(包括虚存),
linux内存管理模块架构:
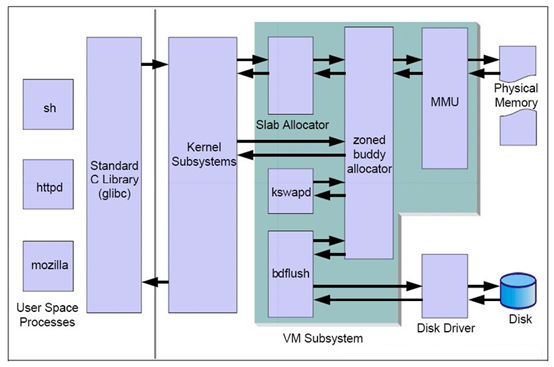
根据以上架构我们来看内存还做了哪些优化:
a. 页表技术
MMU(Memory Management Unit),负责通过页表技术将物理地址转化为虚拟(逻辑)地址,表现为伙伴系统(buddy system)。
为了提高地址变换速度,可在地址变换机构中增设一个具有并行查询能力的特殊高速缓存存储器,又称为联想寄存器(Associative Memory)或块表,在IBM系统中取名为(Translation Look-aside Buffer)TLB用来存放 当前访问的那些页表项。
b. Zoned buddy allocator 分区伙伴系统分配器
内核可以直接读取被伙伴系统重新组织过的虚拟地址内存块,提供给进程的是页(page)
c. Slap allocator
伙伴系统里基本单元可能对某些对象来说还是太大了,造成过大的内部碎片。所以搭建slap系统,将基本单元再细分为更小的内存单元,再分配页,给进程使用。
d. Kswapd
监控交换swap分区(虚拟内存)页面进出。
e. Bdflush
脏页(dirty),因为硬盘(图中通过buffer对接Disk Driver)的读写速度远赶不上内存的速度,系统就把读写比较频繁的数据事先放到内存中,以提高读写速度,这就叫高速缓存,linux是以页作为高速缓存的单位,当进程修改了高速缓存里的数据时,该页就被内核标记为脏页。
Bdflush作为核心守护进程在合适的时间将内存中的dirty(脏页)缓存写到磁盘上,以保持高速缓存中的数据和磁盘中的数据是一致的。
hugetlbfs 特殊文件系统(大页面文件系统)
当对象很大的时候,由于其采用的默认页面大小为 4KB,因而将会产生较多 TLB Miss 和缺页中断,增加了寻址时间,从而大大影响应用程序的性能。因此引入大页面系统来优化,将page单元弄得更大,比如2M。
内存分类:
[root@cbs1 sos]# free -h
total used free shared buff/cache available
Mem: 30G 573M 4.7G 90M 25G 29G
Swap: 31G 331M 31G
1.buffer和cache都是为了解决互访的两种设备存在速率差异,使磁盘的IO的读写性能或cpu更加高效,减少进程间通信等待的时间
2.buffer:缓冲区-用于存储速度不同步的设备或优先级不同的设备之间传输数据,通过buffer可以减少进程间通信需要等待的时间,当存储速度快的设备与存储速度慢的设备进行通信时,存储快的设备先把数据缓存到buffer上,等到系统统一把buffer上的数据写到速度慢的设备上。常见的有把内存的数据往磁盘进行写操作(bdflush),这时你可以查看一下buffers
3.cache:缓存区-用于对读取速度比较严格,却因为设备间因为存储设备存在速度差异,而不能立刻获取数据,这时cache就会为了加速缓存一部分数据。常见的是CPU和内存之间的数据通信,因为CPU的速度远远高于主内存的速度,CPU从内存中读取数据需等待很长的时间,而Cache保存着CPU刚用过的数据或循环使用的部分数据,这时Cache中读取数据会更快,减少了CPU等待的时间,提高了系统的性能。
4.shared
共享内存,顾名思义就是允许两个不相关的进程访问同一个逻辑内存,共享内存是两个正在运行的进程之间共享和传递数据的一种非常有效的方式。
共享内存实现进程间通信。
5. free 是真正尚未被使用的物理内存数量。
available 是应用程序认为可用内存数量,available = free + buffer + cache (注:只是大概的计算方法)
所以总的优化手段如下:
使用buffer cache缓存文件元数据(metadata)以及写操作;
使用page cache缓存DISK IO(文件内容);
使用shared memory完成进程间通信;
使用buffer cache、arp cache和connetion tracking提升网络IO性能。
DMA/内核空间/用户空间:
32位系统中:
内核空间(低端内存)又分为线性区(ZONE_NORMAL)和非线性区,非线性区用来管理超过1G的高端内存(用户空间)。
每个区间划分是不恒定的。不过4G内存如下划分:
其低地址位置有16MB给DMA(ZONE_DMA),从16M到896M才是内核可以直接访问的地址空间(ZONE_NORMAL),从896M到1G这段空间是预留的物理地址空间(非线性区),来管理用户空间。
在Linux64位系统中,
低地址空间的1G内存都给了DMA,这个时候DMA的寻址能力就大大加强了;1G以上的地址空间给划分了ZONE_NORMAL,这段空间都可以被内核直接访问。所以在64位上,内核可以直接访问大于1G的内存地址,不再需要额外的步骤,效率和性能上也大大增加。
Sysctl优化内存:
报错:“Out of socket memory”或者“TCP:too many of orphaned sockets”

参考书籍:
《操作系统-精髓与设计原理》
《深入Linux内核 架构》
《深入理解linux内核》
参考链接:
https://blog.csdn.net/Celeste7777/article/details/49560401
http://edsionte.com/techblog/archives/4019#comments
https://www.oschina.net/translate/understanding-virtual-memory
https://www.ibm.com/developerworks/cn/linux/l-cn-hugetlb/#alloc_huge_page
http://www.ibm.com/developerworks/cn/linux/l-linux-slab-allocator/
http://oss.org.cn/kernel-book/ch06/6.3.3.htm
http://oss.org.cn/kernel-book/ch06/6.6.2.htm
http://wiki.dzsc.com/info/6624.html
http://www.cnblogs.com/daoluanxiaozi/archive/2012/03/12/2392281.html
http://os.51cto.com/art/201309/411937.htm
http://www.2cto.com/os/201407/315641.html
http://blog.chinaunix.net/uid-11278770-id-148460.html
http://blog.csdn.net/duqi_2009/article/details/15811693
http://blog.chinaunix.net/uid-28236237-id-3513958.html
https://www.jianshu.com/p/2ffeb3a3aa90
https://blog.csdn.net/ysdaniel/article/details/7307091