数据库「MySQL」
Jdbc 链接数据库的具体过程
- 加载 JDBC 驱动;
- 指定连接属性,创建连接;
- 创建 Statement;
- 执行 SQL ,获取结果集;
- 关闭链接;
数据库事务特性
- 原子性:一个事务不可分割,要么都执行成功,要么都不执行;
- 一致性:事务是将数据库从一个一致的状态变为另一个一致性的状态,和原子性密切相关;
- 隔离性:两个事务之间不会互相影响;
- 持久性:一旦事务提交之后对于数据库的操作是永久性的;
数据库并发存在的问题「https://blog.csdn.net/yuxin6866/article/details/52649048」
- 脏读:A 事务读取了 B 事务未提交的数据;
- 不可重复读:在 A 事务读取两次之间,B 事务进行了修改提交,A 事务两次读取的数据内容不一致;
- 幻读:在 A 事务读取两次之间,B 事务进行了事务新增提交,A 事务两次读取的数据条数不一致;
不可重复读和幻读的区别
不可重复读和幻读的区别:从总的来看,两者都是对数据进行了两次查询,但两次查询的结果都不一样。但如果你从控制的角度来看, 两者的区别就比较大,对于前者, 只需要锁住满足条件的记录,对于后者, 要锁住满足条件及其相近的记录;所以对于不可重复读需要行锁,对于幻读需要表锁。
如果使用锁机制来实现这两种隔离级别,在可重复读中,当 SQL 第一次读取到数据后,就将这些数据行加锁,其它事务无法修改这些数据,就实现了可重复读。但这种方法却无法锁住 insert 的数据,所以当事务 A 先前读取了数据,或者修改了全部数据,事务 B 还是可以 insert 数据提交,这时事务 A 就会发现莫名其妙多了一条之前没有的数据,这就是幻读,不能通过行锁来避免。
数据库隔离级别(由低到高)
- 读未提交(Read Uncommitted):存在脏读、不可重复读、幻读;
- 读已提交(Read Committed):存在不可重复读、幻读;
- 可重复读(Repeatable Read):存在幻读「MySQL 在该级别下没有幻读」;
- 串行化(Serializable):安全;
MVCC
多版本并发控制机制,在各种事务隔离级别会有不同的体现。
MVCC 在 MySQL InnoDB 中的实现主要是为了提高数据库并发性能,用更好的方式去处理读-写冲突,做到即使有读-写冲突时,也能做到读不加锁,非阻塞并发读。
- 当前读
读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁「像select lock in share mode(共享锁), select for update ; update, insert ,delete(排他锁)」
- 快照读
不加锁的 select 操作就是快照读,即不加锁的非阻塞读
MVCC(多版本并发控制) 的实现
- 3个隐式字段「当前数据行的事务 id(tax_id)、回滚指针(roll_pointer)、删除标志(delete_flag)」
- undo 日志
- Read View「一致性视图」
MVCC 带来的好处
MVCC 是一种用来解决读-写冲突的无锁并发控制,也就是为事务分配单向增长的时间戳,为每个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据库的快照。 所以 MVCC 可以为数据库解决以下问题:
- 在并发写数据库时,保证并发读不会阻塞写操作,写操作也不用阻塞读操作,提高了数据库并发读写的性能;
- 同时还可以解决脏读,幻读,不可重复读等事务隔离问题,但不能解决更新丢失问题;
MVCC 的原理图:
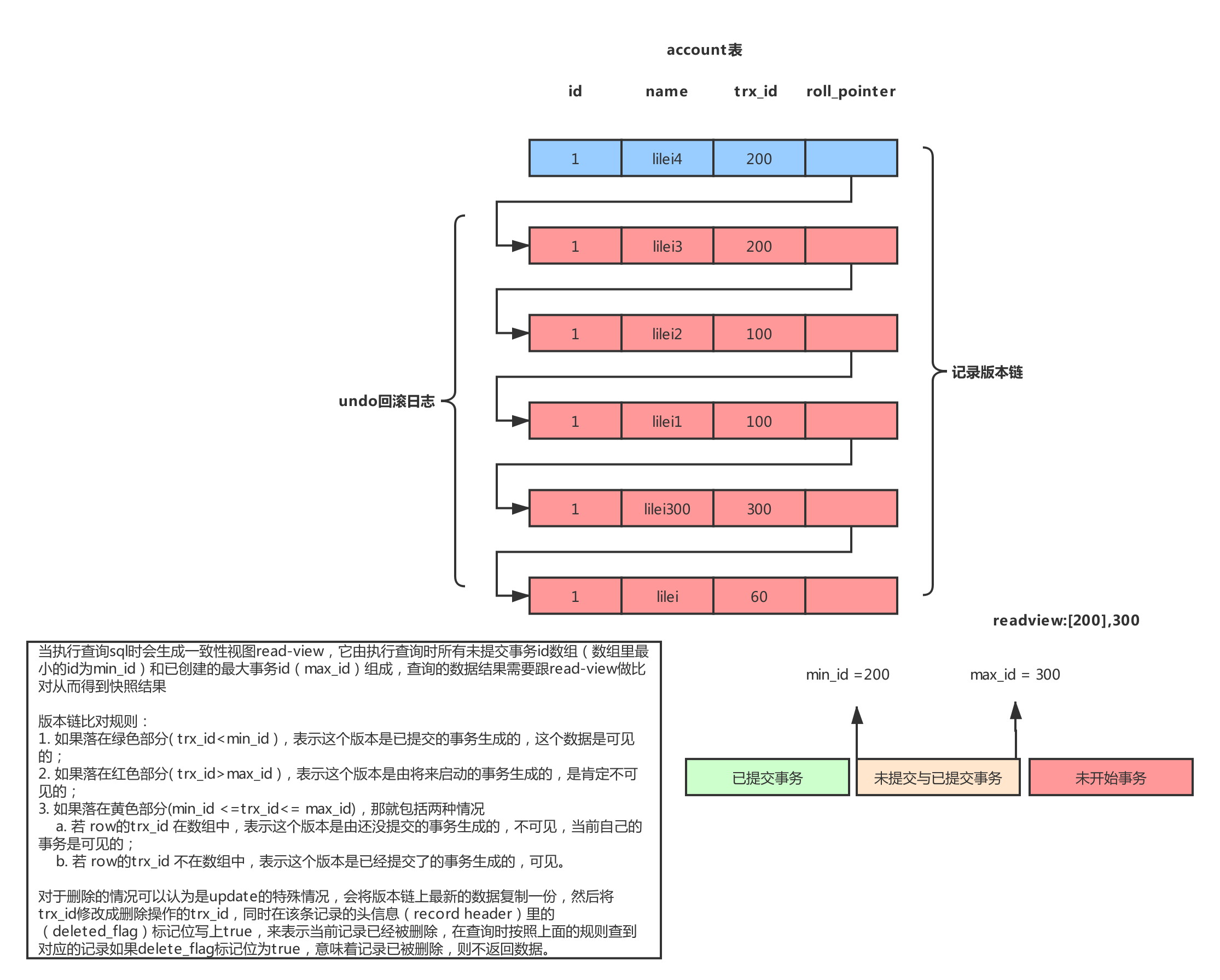
MySQL 在可重复读的隔离级别下解决了幻读,如何解决的呢?
索引分类
- 组合索引
- 单列索引
- 普通索引
- 唯一索引
- 主键索引
- 全文索引『只有在 MyISAM 引擎上才使用』
解释
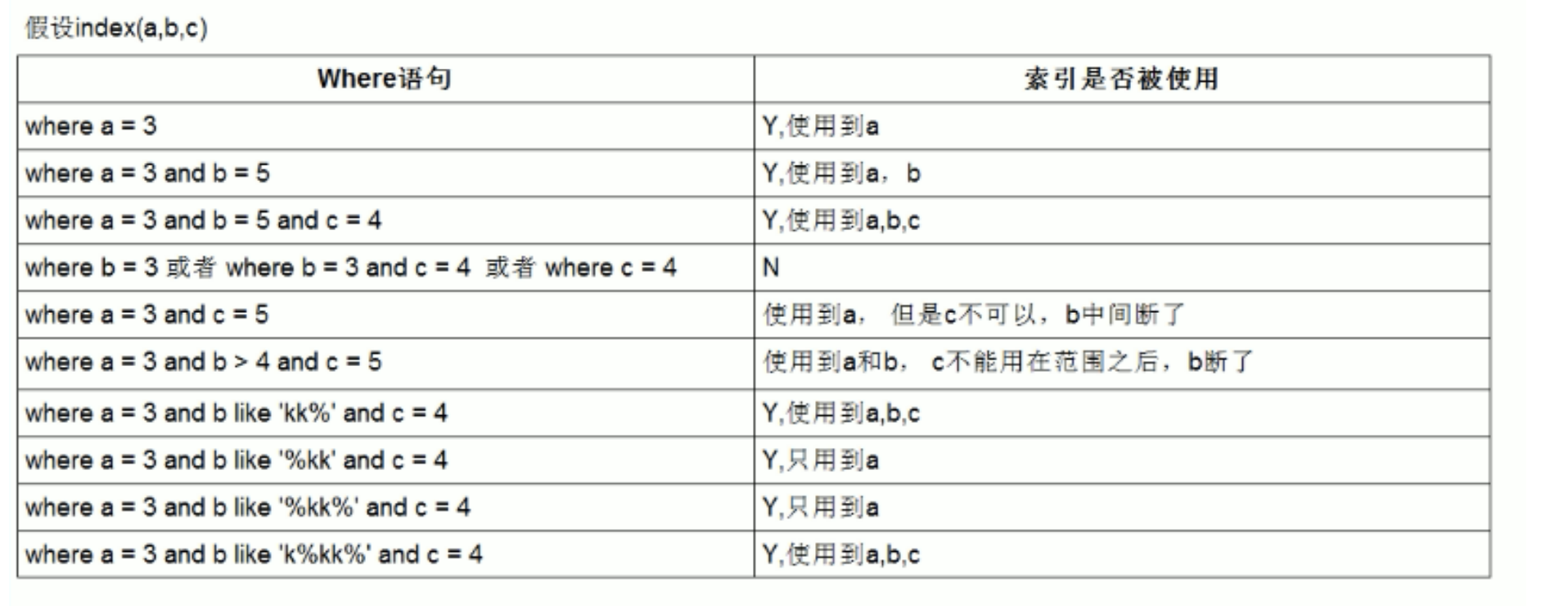
- 组合索引:在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀集合;
- 普通索引:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点;
- 唯一索引:索引列中的值必须是唯一的,但是允许为空值;
- 主键索引:是一种特殊的唯一索引,不允许有空值;
- 全文索引:
MySQL 索引失效的场景,以及解决办法「https://www.jianshu.com/p/3ccca0444432」
- 查询条件中有 or;『使用 union all』
- 查询条件中有 !=;『可以改为大于和小于,分两次查询』
- 查询条件中判空(is null 或 is not null);『修改字段默认值,为 0 或空字符串』
- like '%xyz'(组合索引中最左匹配会生效);『将 xyz 倒排使用 like 'zyx%'或者直接使用 reverse 函数』
- 对查询的列上有运算或者函数的;『可以把计算放在等号右边或者用 like』
- 字符串列没有使用单引号;『因为 SQL 会自动转换类型,那么就会导致索引失效,可以加上单引号来解决』
- 左连接查询或者右连接查询查询关联的字段编码格式不一样;『改编码』
- MySQL 估计使用全表扫描要比使用索引快;『可以分多次查询』
- 连接查询中,按照优化器顺序的驱动表不会走索引;『换驱动表』
- 查询中没有用到联合索引的第一个字段;『按最左匹配规则调整 where 以及 order by 后的字段顺序』
为什么 innoDB 中非主键索引的叶子节点存储的不是值,而是主键
- 保持一致性,当数据库表进行DML操作时,同一行记录的页地址会发生改变,因非主键索引保存的是主键的值,无需进行更改;
- 节省存储空间,所以会出现回表;
联合索引使用情况
SQL 优化的方式
-
查询优化:
- 在 where 和 order by 后面尽量使用索引,select 后面的字段只选需要的,做到索引覆盖,不要全写星号,可以避免回表;
- 在 where 后面不要进行 null 值的判断,对于可为 null 的字段,可以设定默认值;
- 在 where 后面不要使用 or,可以使用 union all 代替;
- 不要对列进行计算,使用 like 时不要在前面加%;
- 在连续的字段上使用 in,如果可以用 between 代替最好;
-
分页查询优化:
-
保证分页的时候 id 是规律的,比如递增,那么在分页的时候,可以在 where 后面带上上次的查询的最大 id;
-
如果是基于某个字段进行排序查询非索引内的字段,可以先查出主键,然后使用 inner join 进行关联查询;「扫描整个索引并查找到没索引的行(可能要遍历多个索引树)的成本比扫描全表的成本更高,所以优化器放弃使用索引」
-
-
索引优化:
- 不要在重复值比较多的列上建立索引;
- 不要在长字段上建索引;
-
对于关联 SQL 的优化:
- 关联字段加索引;
- 尽量把小表作为驱动表放在前面,不要让 MySQL 优化器自己去优化「MySQL 优化器也是需要时间去优化」;
-
in 和 exsits 优化:
- 小表驱动大表;
-
count(*) 查询优化:
- 如果表特别大的话,可以在另外的表里面记录行数,将两者放在同一个事务中;
- 使用 show table status,比如“show table status 'user' ”,效率特别高;
- 将数据行加载到缓存中,但是会出现数据不一致;「不推荐」
MySQL 读写分离
主从架构
- MySQL 主从延迟的可能原因?如何避免?
- 网络原因、机器磁盘性能下降等
- 避免大事务尽量拆小、读写分离分散读压力
- 数据库领域有哪些锁以及分类?
行/表、间隙锁、乐观/悲观锁、共享/排他,读/写锁
缓存「Redis」
缓存击穿
- 描述
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力 - 解决办法
- 设置缓存永久不过期;
- 根据 key 设置互斥锁;
缓存穿透
- 描述
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。 - 解决办法
- 接口层增加校验,如用户鉴权校验,id 做基础校验,id <= 0的直接拦截;
- 使用布隆过滤器;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将 key-value 对写为 key-null,缓存有效时间可以设置短点,如 30 秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个 id 暴力攻击;
缓存雪崩
- 描述
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至 down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。 - 解决办法
- 在设定缓存过期时间时,在过期时间上加上随机时间;
- 部分热点数据设置永不过期;
Redis 的跳跃表「https://www.cnblogs.com/hunternet/p/11248192.html」
Redis 缓存过期策略
- 惰性删除:访问一个过期的 key 进行操作时,Redis 会将该 key 删除;
- 定期删除:由于惰性删除策略无法保证冷数据被及时删掉,所以 Redis 会定期淘汰一批已过期的 key;
- 主动删除:当达到最大内存设定值,会主动删除部分数据;
定期删除采取的方案:
默认情况下 Redis 定期检查的频率是每秒扫描 10 次,用于定期清除过期键。当然此值还可以通过配置文件进行设置,在 redis.conf 中修改配置 “hz” 值即可, 默认的值为“hz 10”。定期删除的扫描并不是遍历所有的键值对,这样的话比 较费时且太消耗系统资源。Redis 服务器采用的是随机抽取形式,每次从过期字典中,取出 20 个键进行过期检测,过期字典中存储的是所有设置了过期时间的键值对。如果这批随机检查的数据中有 25% 的比例过期,那么会再抽取 20 个 随机键值进行检测和删除,并且会循环执行这个流程,直到抽取的这批数据中过 期键值小于 25%,此次检测才算完成。Redis 服务器为了保证过期删除策略不 会导致线程卡死,会给过期扫描增加了最大执行时间为 25ms,保证每次扫描不会超过 25ms。
主动删除包含的策略如下:「默认是第一种」
- allkeys-lru:根据 LRU 算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止;
- allkeys-random:随机删除所有键,直到腾出足够空间为止;
- volatile-random: 随机删除过期键,直到腾出足够空间为止;
- volatile-ttl:根据键值对象的 ttl 属性,删除最近将要过期数据。如果没有,回退到 noeviction 策略;
- noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息,此时 Redis 只响应读操作。