(一)编程实现将 RDD 转换为 DataFrame
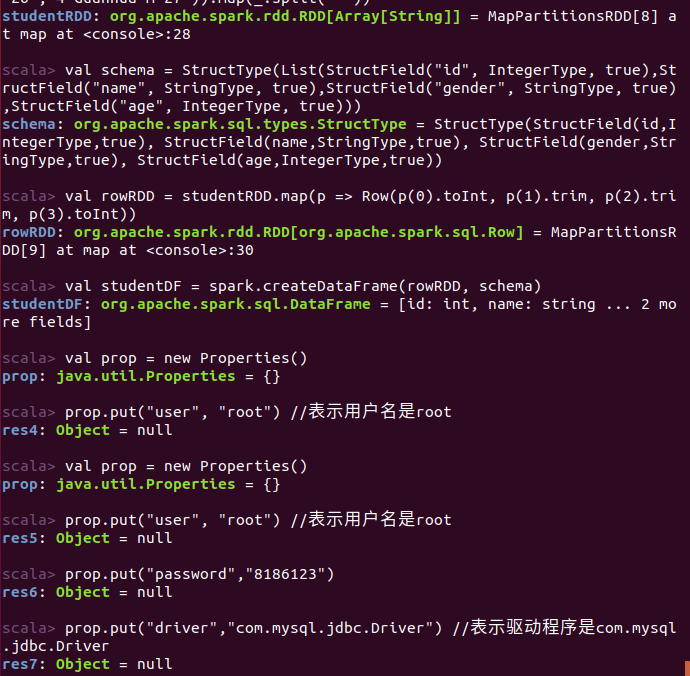
使用编程接口,构造一个 schema 并将其应用在已知的 RDD 上。
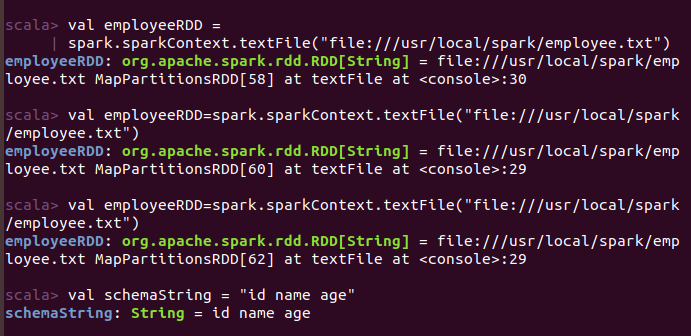
命令:
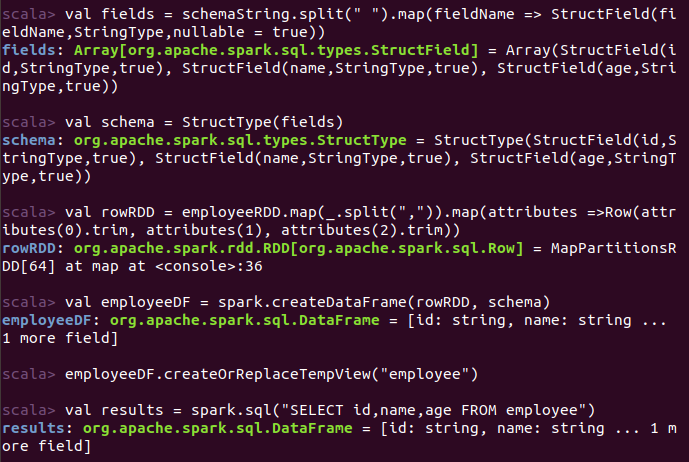
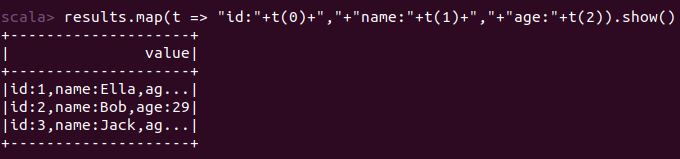
结果:
(二)编程实现利用 DataFrame 读写 MySQL 的数据
数据库中已有的表:
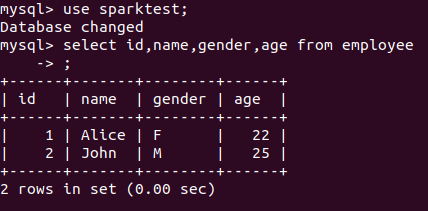
对此表插入两个数据操作:
导包:
代码解说:
1.//下面我们设置两条数据表示两个学生信息
2.val studentRDD = spark.sparkContext.parallelize(Array("3 Rongcheng M 26","4 Guanhua M 27")).map(_.split(" "))
3.
4.//下面要设置模式信息
5.val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("gender", StringType, true),StructField("age", IntegerType, true)))
6.
7.//下面创建Row对象,每个Row对象都是rowRDD中的一行
8.val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt))
9.
10.//建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
11.val studentDF = spark.createDataFrame(rowRDD, schema)
12.
13.//下面创建一个prop变量用来保存JDBC连接参数
14.val prop = new Properties()
15.prop.put("user", "root") //表示用户名是root
16.prop.put("password", "hadoop") //表示密码是hadoop
17.prop.put("driver","com.mysql.jdbc.Driver") //表示驱动程序是com.mysql.jdbc.Driver
18.
19.//下面就可以连接数据库,采用append模式,表示追加记录到数据库spark的student表中
20.studentDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/spark", "spark.student", prop)
21.val jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/spark").option("driver","com.mysql.jdbc.Driver").option("dbtable","student").option("user","root").option("password", "8186123").load()//配置Spark通过jdbc连接数据库mysql
22.jdbcDF.agg("age" -> "max", "age" -> "sum").show()//最后打印age的最大值和总和