1. 网站链接
2. 本次作业的分工
- 我(学号031602510):爬虫和附加题实现
- 我的队友(学号031602511):修改后的词频统计功能
3. PSP表格
| PSP2.1 | ersonal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 15 |
| Estimate | 估计这个任务需要多少时间 | 15 | 15 |
| Development | 开发 | 550 | 580 |
| Analysis | 需求分析 (包括学习新技术) | 50 | 50 |
| Design Spec | 生成设计文档 | 30 | 40 |
| Design Review | 设计复审 | 10 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 20 | 30 |
| Coding | 具体编码 | 210 | 180 |
| Code Review | 代码复审 | 80 | 80 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | 155 | 105 |
| Test Repor | 测试报告 | 120 | 100 |
| Size Measurement | 计算工作量 | 15 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 720 | 700 |
4. 解题思路描述与设计实现说明
爬虫使用
1. 爬虫使用
采用的爬虫工具:后羿采集器
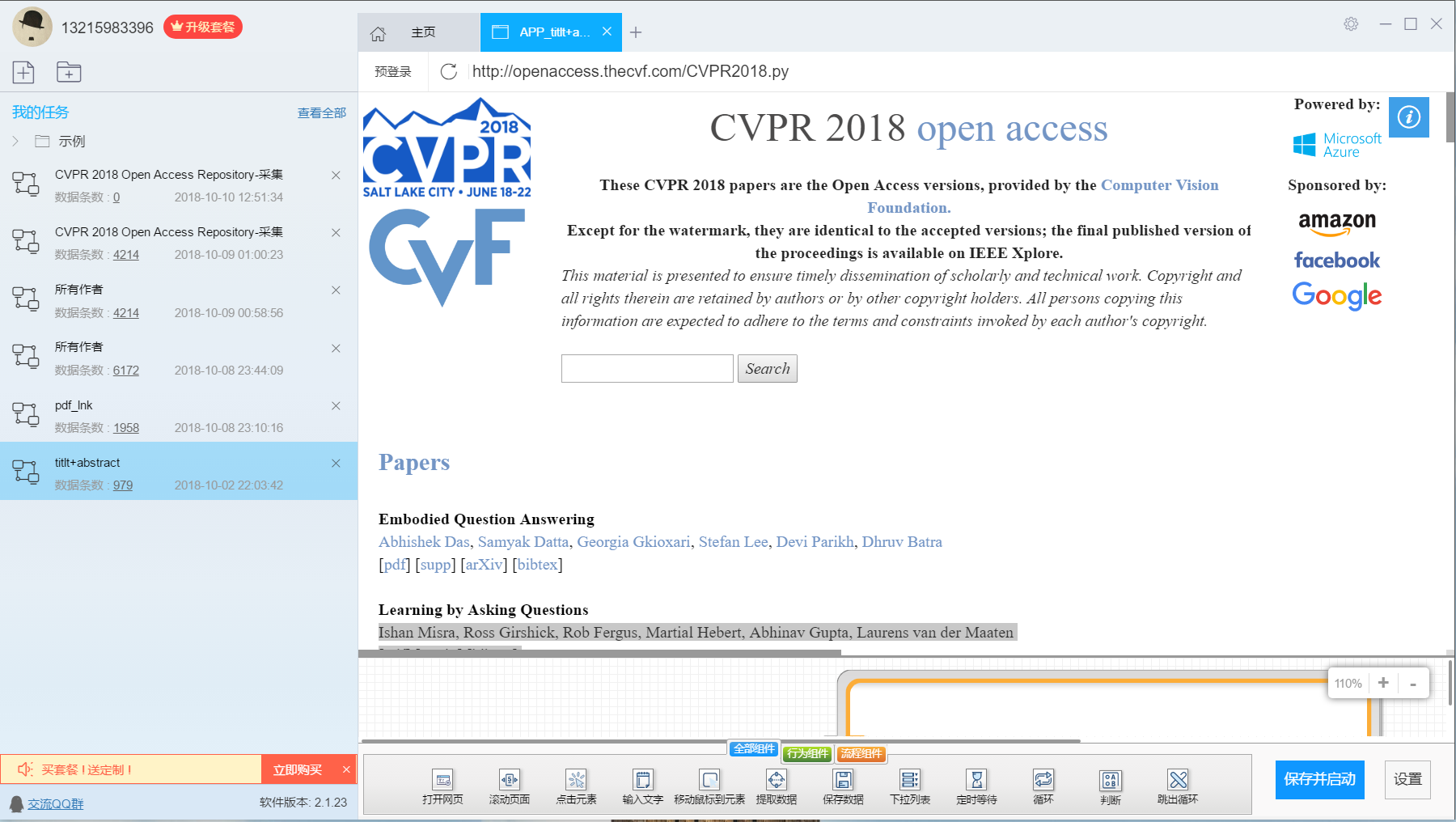
2. 使用过程
-
采集模式——流程图模式
-
输入采集的url
-
打开采集主页

-
制做流程图进行采集
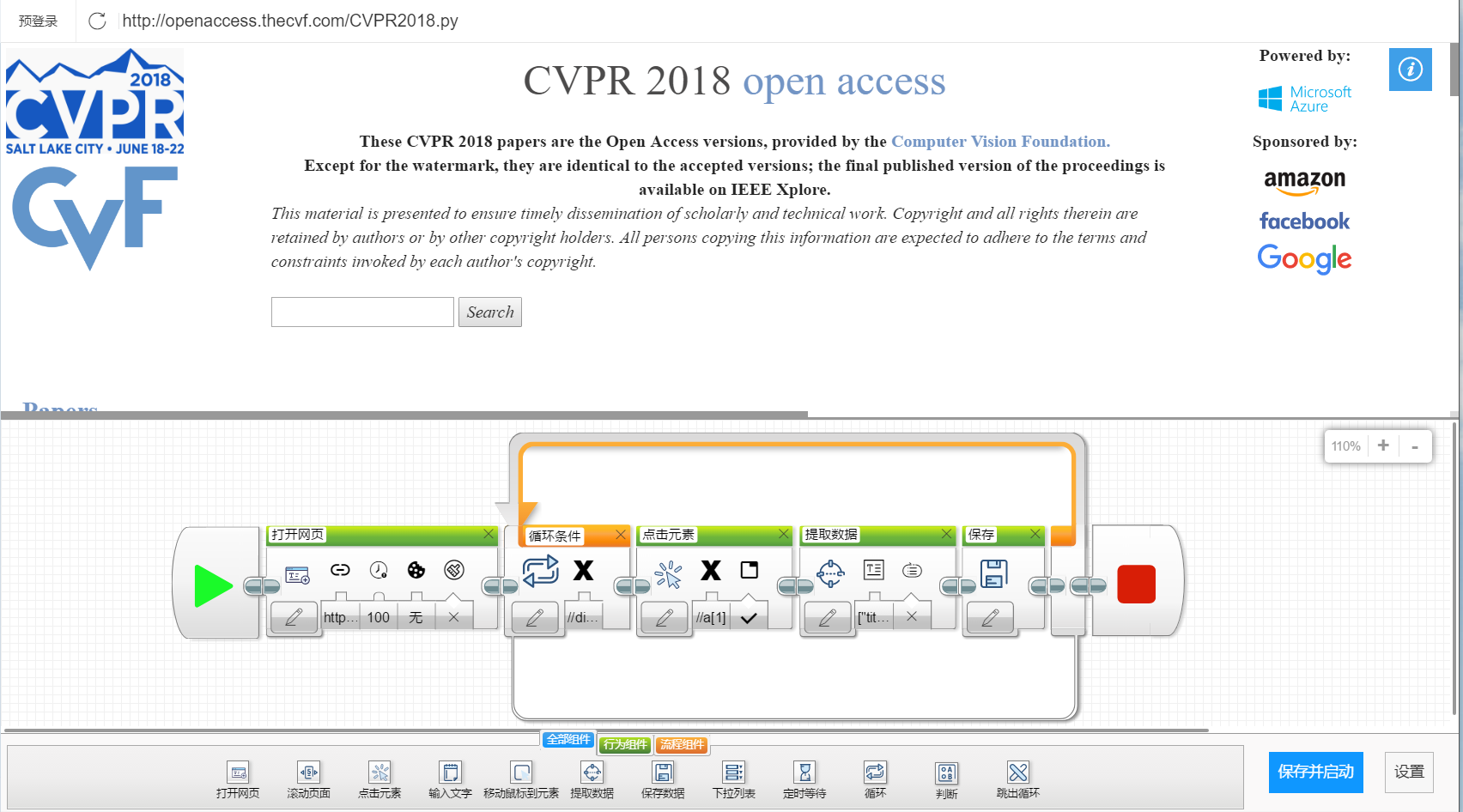
-
运行爬虫
3. 说明算法的关键与关键实现部分流程图
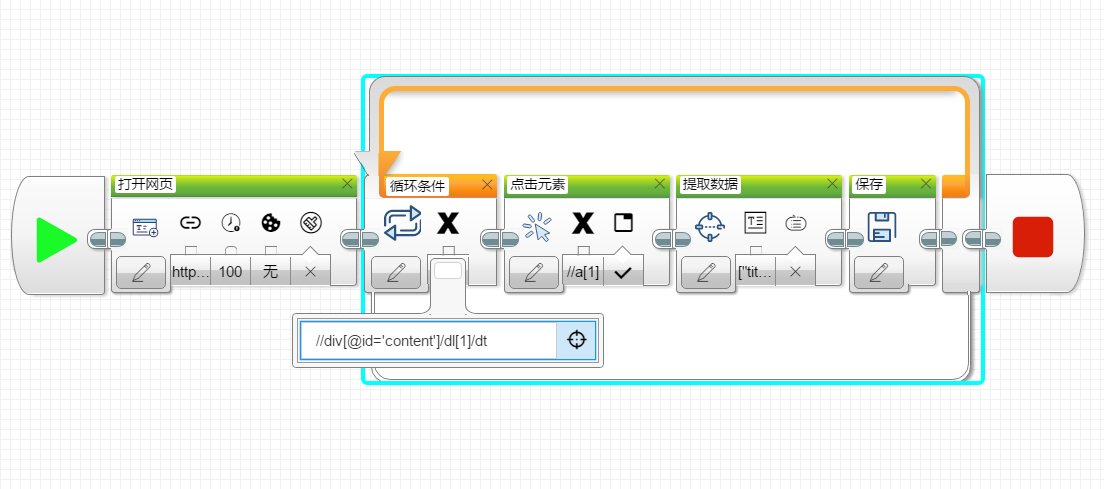
先打开网页CVPR2018主页,
然后进入一个循环:
- 依次点击论文标题(元素位置://div[@id='content']/dl[1]/a[1]);
- 进入论文详情页面,爬取论文的Title(元素位置://div[@id='papertitle'])和Abstract(元素位置://div[@id='abstract'])元素的文本内容;
- 将文本保存;
就这样简单地获得了论文的基本信息。(用工具解放双手)
代码组织与内部实现设计
1. 设计思路
这次编码题目是第一次个人作业即词频统计的升级版,故先给出上一次作业题目链接和上一次作业中我的博客链接。
这次作业题目早早就发布了,但我真正开始编码是在国庆假期的时候(之前都在干什么我也记不大清了)。因为题目的编码要求和上一次的个人项目(普通的词频统计)差不多,功能方面其实只是增加了词组的词频统计和词频权重,并不需要学习新的知识,因此只需在上一次的基础上增加要求功能即可。
2. 难点及解决方案
在题目中,明确要求了论文编号及其紧跟着的换行符、分隔论文的两个换行符、“Title: ”、“Abstract: ”(英文冒号,后有一个空格)均不纳入所有字符、单词、有效行、词频统计范围;且要求加入词组词频统计功能。这些是我认为本次编码中有难处的地方,故难点如下:
- 区别并跳过
论文编号行Title:Abstract:及后续两个空行
解决方案:在查看爬虫格式并询问助教后得知,测试所用输出都是论文爬取结果,也就是说格式是固定的(论文编号的下一行开头一定是
Title:固定是7个字符;Abstract:同理,固定是10个字符)所以可以使用取巧的办法,对于每篇爬取的论文跳过固定的字符数从而实现题目要求。
- 按题目要求识别并保存指定单词个数的词组
在我原来的词频统计中判断单词的基础上(可点击前面的博客链接查看上一次的思路,下文也会给出完整的流程图)。默认词组长度为1(=1时即普通的词频统计)),当词组长度>1时在原先的缓存区数组中缓存单词词缀(单词及其末尾与下一个字母之间分隔符)。当单词数达到词组要求时,将数组缓存存入无序容器,同时缓存数组指针向后移动缓存中第一个词缀的距离;若单词数达到要求前遇见非法单词,则清空数组缓存。
3. 设计实现过程
-
代码思路
代码设计的大致思路图如下,其中词频统计的具体实现在后文的关键代码解释部分

-
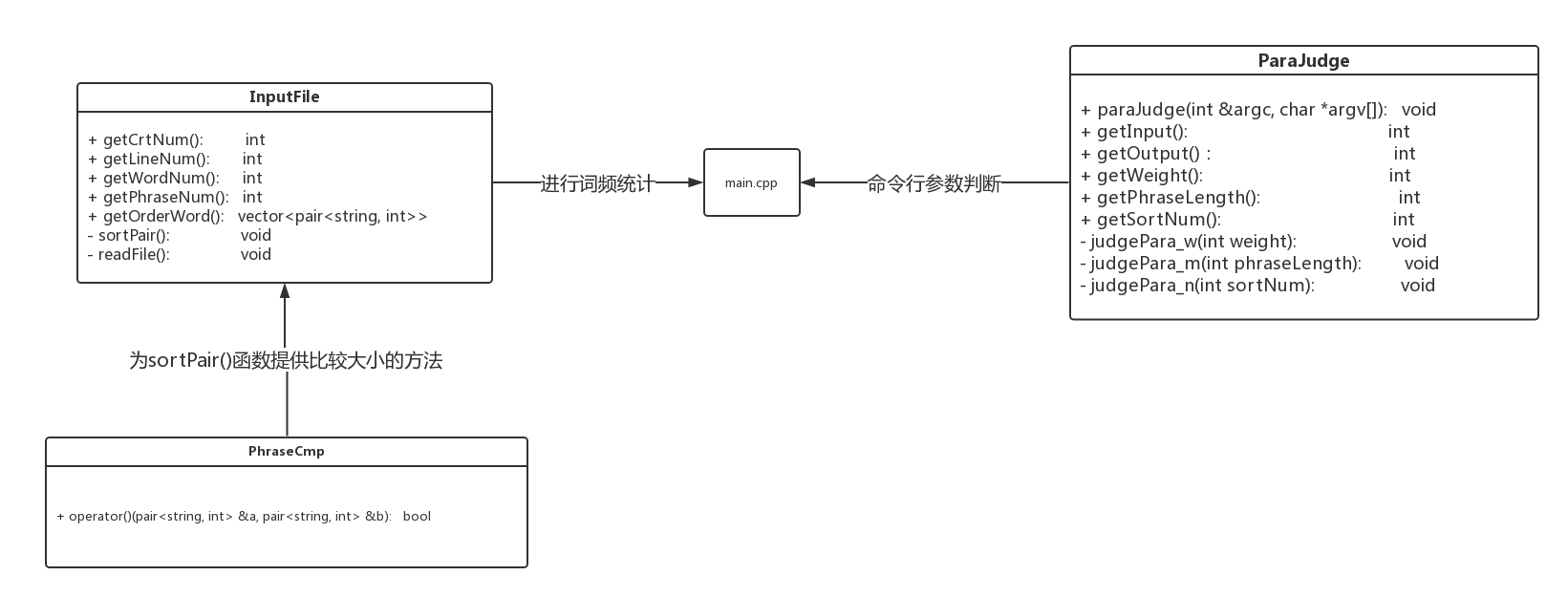
内部实现设计(类图)
5. 附加题设计与展示
-
设计的创意独到之处
- 爬取论文的pfl下载链接,可以通过论文;
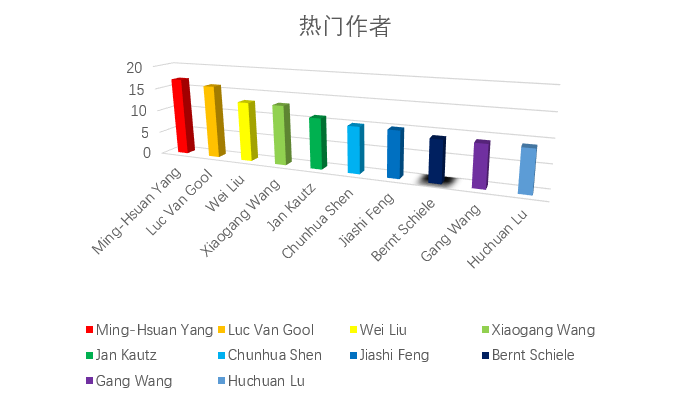
- 爬取论文作者信息,并统计发表论文最多的前十位;
-
实现思路
PDF_LINK思路:
循环元素(元素位置://div[@id='content']/dl[1]/dd)中的元素,爬取文本为"pdf"的元素a的链接内容;
热门作者统计思路:
循环爬取元素(元素位置://div[@id='content']/dl[1]/dd/form)中元素的文本内容,就可以获得作者的姓名信息列表。自己写一个代码(C++)将作者的姓名进行频率统计,并得出论文发表篇数排名前十的作者;
-
实现成果展示(具体文件附在github作业中)
PDF_link:

热门作者统计:

-
6. 关键代码解释
1. 在判断词组(或是单词)的同时进行词频统计
因为这一算法比较复杂,故先这里贴出算法流程图

接下去是这一算法的代码
/*读取字符为非分隔符*/
if ((tempChar >= 'a' && tempChar <= 'z') || (tempChar >= 'A' && tempChar <= 'Z') || (tempChar >= '0' && tempChar <= '9'))
{
/*存在非法单词时无法构成词组,清空缓存*/
if ((tempChar >= '0' && tempChar <= '9') && (alpLength < 4))
{
alpLength = 0;
arrayLength = 0;
_phraseLength = 0;
flag_numBefAlp = true;
tempInt = 0;
continue;
}
else if (!(tempChar >= '0' && tempChar <= '9'))
{
if (flag_numBefAlp && alpLength < 4) continue;
if (tempChar >= 'A' && tempChar <= 'Z') tempChar = tempChar - 'A' + 'a';
alpLength++; //本单词开头的连续字母数目+1
/*新的单词读入,字符数组前一串为词缀*/
if (alpLength == 1 && _phraseLength > 0 && phraseLength > 1)
{
wordLength[tag] = tempInt; //存入上一个词缀
tempInt = 0; //重置当前词缀长度
tag = (tag + 1) % 10;
}
}
wordArray[arrayLength++] = tempChar; //符合要求的字符存入数组且游标后移
tempInt++;
}
/*读取字符为分隔符*/
else
{
if (flag_numBefAlp) flag_numBefAlp = false;
/*分隔符前是一个完整的单词*/
if (alpLength >= 4)
{
_phraseLength++; //数组中单词个数+1
_wordNum++;
tempInt++;
/*单词个数满足词组个数要求*/
//满足要求应将当前词组存入phrase,并将后两个词缀留在数组
if (_phraseLength == phraseLength)
{
/*词组存至phrase*/
wordArray[arrayLength] = 0;
phrase = wordArray;
phraseNum++;
/*词组存入无序容器*/
itor = phraseMap.find(phrase);
if (itor != phraseMap.end()) itor->second += _weight;
else phraseMap[phrase] = _weight;
/*将后两个词缀留在数组*/
if (phraseLength > 1)
{
tempTag = tag - phraseLength + 1;
if (tempTag < 0) tempTag += 10;
phrase = phrase.substr(wordLength[tempTag]);
strcpy_s(wordArray, phrase.c_str());
arrayLength -= (wordLength[tempTag]); //相当于字符数组指针后移一个词缀的长度
}
_phraseLength--; //字符数组中词缀数目-1
}
if (phraseLength > 1) wordArray[arrayLength++] = tempChar;
else arrayLength = 0;
alpLength = 0;
}
/*分隔符在起词组间分割单词作用,需保存*/
else if (alpLength == 0 && _phraseLength > 0 && phraseLength > 1)
{
wordArray[arrayLength++] = tempChar;
tempInt++;
}
/*分隔符前面是非法单词,清空数组缓存*/
else if (alpLength > 0 && alpLength < 4)
{
alpLength = 0;
arrayLength = 0;
_phraseLength = 0;
tempInt = 0;
}
}
2. 对单词(或词组)进行排序
/*将单词按要求排序后保存到orderWord容器中*/
void InputFile::sortPair()
{
hasSort = true;
/*通过迭代器将unordered_map中的pair数据复制到vector中*/
for (itor = phraseMap.begin(); itor != phraseMap.end(); itor++) {
orderWord.push_back(make_pair(itor->first, itor->second));
//cout << "<" << itor->first << ", " << itor->second << ">" << endl;
}
int i = (int)phraseMap.size();
if (i > sortNum) i = sortNum;
/*通过paritial_sort函数对vector中的单词按题目要求排序*/
partial_sort(orderWord.begin(), orderWord.begin() + i, orderWord.end(), PhraseCmp());
}
7.性能分析与改进
1. 代码初始性能分析
对CVPR网站论文的爬取结果,运行100次程序,耗时2.05分钟。得性能分析图如下:
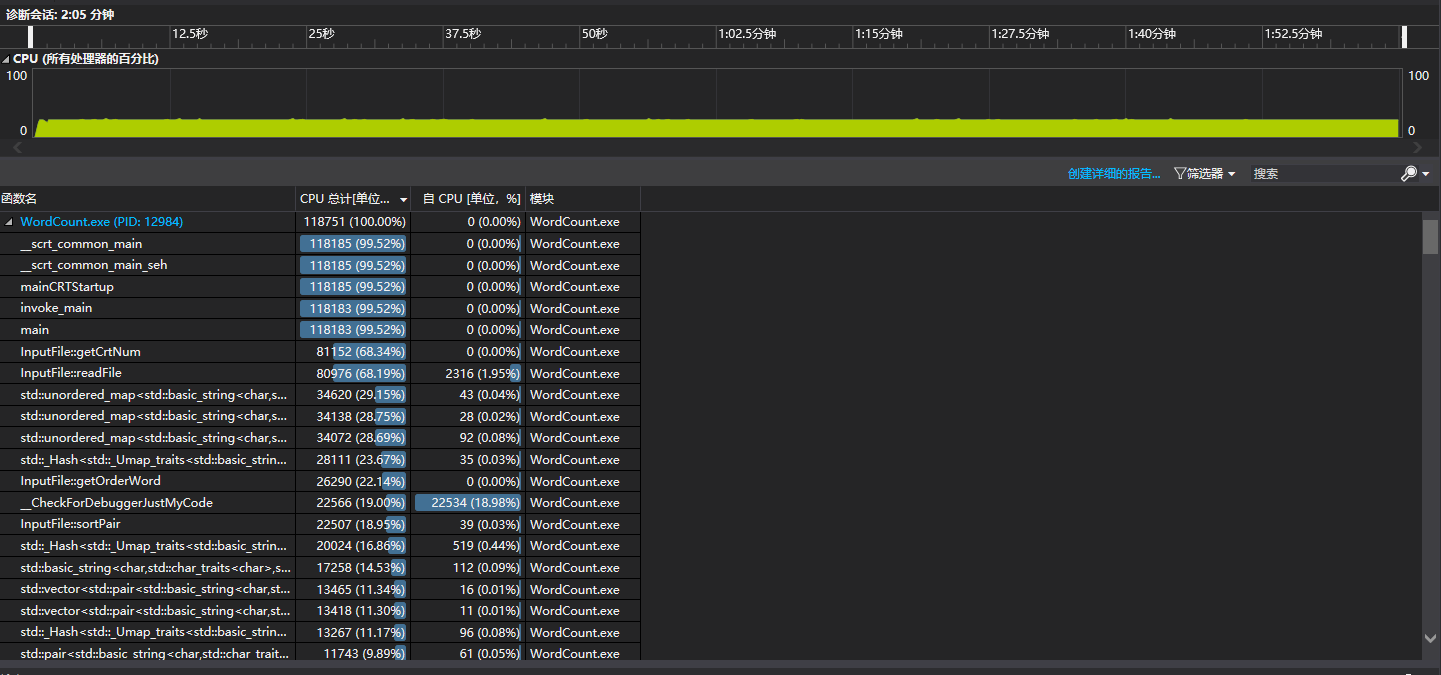
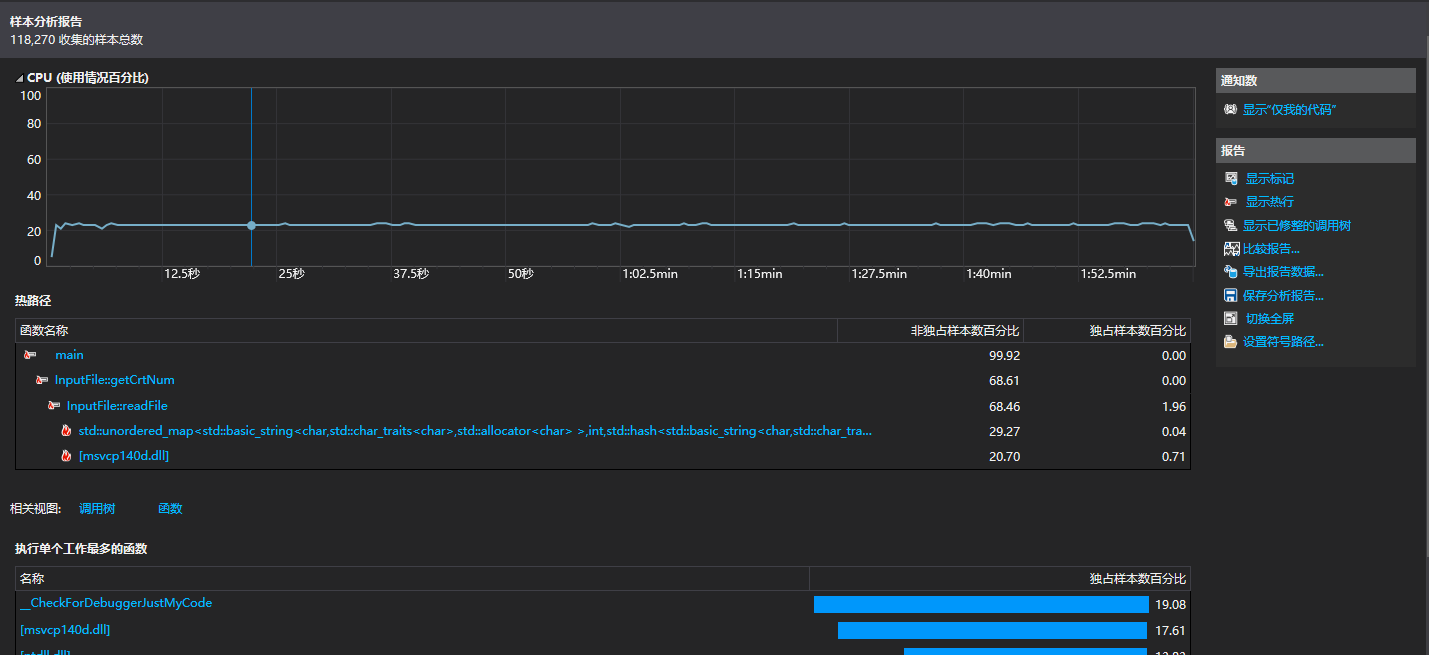
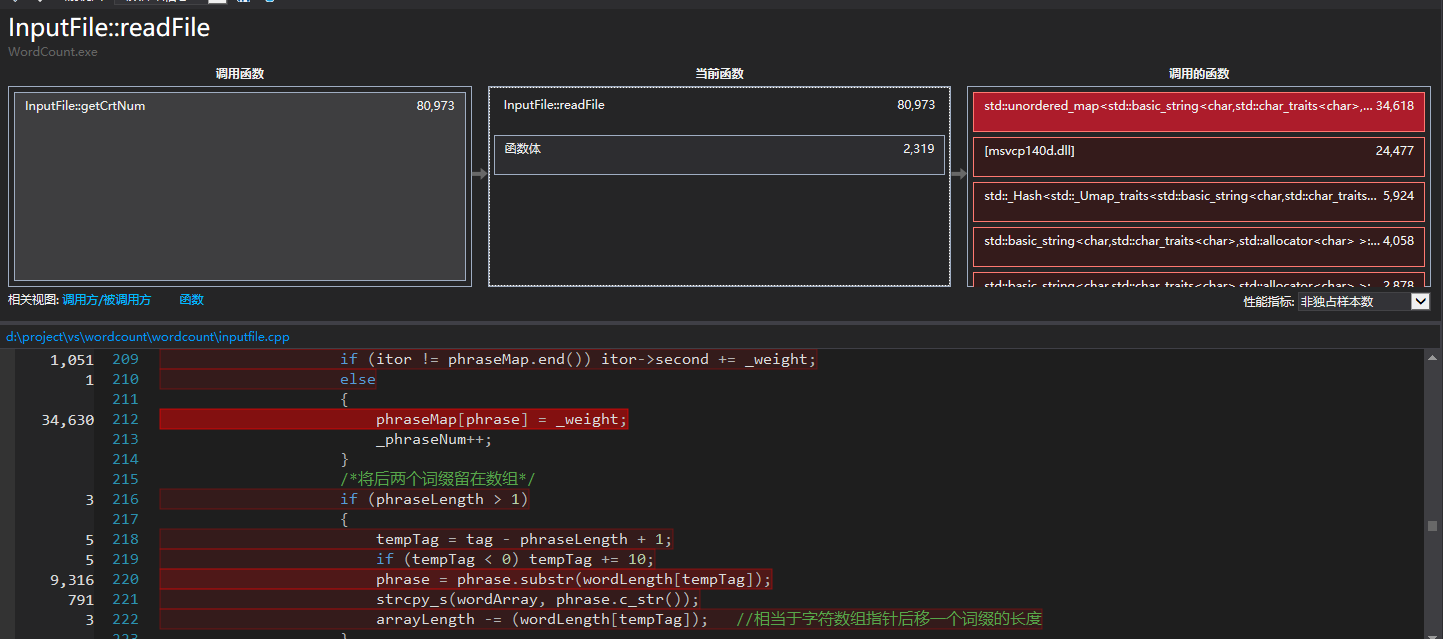
可以看出程序运行时占用CPU时间最久的是InputFile类中的readFile()函数,占总用时68.19%。详细查看其性能分析,可以发现词组存入unordered_map容器占用了大量的运行时间。
2. 改进思路
词组存入容器属于STL中的操作,我在网络上查询资料时找到了这篇关于高效使用STL的博客。从中找出对此次编码作业有帮助思路在下面列出。
- 当对象很大时,建立指针的容器而不是对象的容器
1) STL基于拷贝的方式的来工作,任何需要放入STL中的元素,都会被复制。STL工作的容器是在堆内开辟的一块新空间,而我们自己的变量一般存放在函数栈或另一块堆空间中;为了能够完全控制STL自己的元素,为了能在自己的地盘随心干活;这就涉及到复制;而如果复制的对象很大,由复制带来的性能代价也不小 ;对于大对象的操作,使用指针来代替对象能消除这方面的代价;
2)只涉及到指针拷贝操作, 没有额外类的构造函数和赋值构造函数的调用;
- 在map的insert()和operator[]中仔细选择
插入时,insert效率高;因为operator会先探查是否存在这个元素,如果不存在就构造一个临时的,然后才涉及到赋值,多了一个临时对象的构造。
更新时,[]效率更高,insert会创造一个对象,然后覆盖一个原有对象;而[]是在原有的对象上直接赋值操作。
3. 改进后代码及性能分析
在实际改进代码的时候,我发现上面的第一点并不适用于这次作业:这次作业中我将<string, int>的pair存入容器,但在在函数结束后pair指针指向的对象会自动销毁。我还考虑了改进排序函数,但排序函数使用的是STL中的partial_sort(),是在上一次个人作业中改进的,这次在查阅资料时(即前述STL博客)发现应尽量用STL中算法替代手写的循环,故放弃这一想法。因此最后仅将phraseMap[phrase] = _weight; 改为 phraseMap.insert(make_pair(phrase, _weight));。
改进后性能分析图如下:

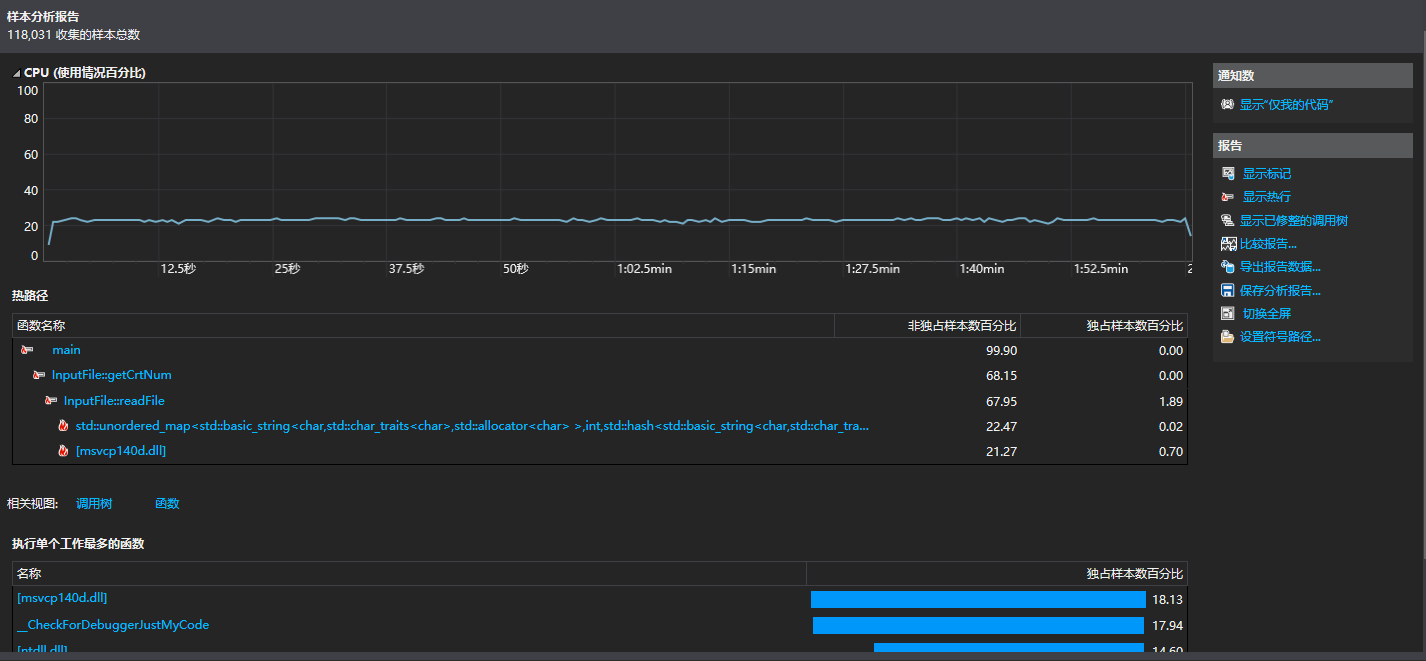
可以看到readFile()函数,占总用时从68.19%优化到了67.66。虽然优化幅度不大,但是多多少少还是略微提升了性能。
8. 单元测试
以下是我设置的十个单元测试的大致描述
| 单元测试名称 | 描述 | 期待输出 |
|---|---|---|
| WrongInputPath | 传入一个不存在的输入文件路径 | 返回正确的错误信息 |
| EmptyFile | 传入一个空的TXT文件 | 统计所得字符数、行数、单词、词组数,为0 |
| EmptyLine | 传入一个文件,文件中论文的有效行只包含空格、tab和换行符 | 统计所得行数、单词、词组数,为0;字符数为2(有两个换行符) |
| OnlyTitle | 传入一个文件,文件中Abstract行仅包含一个换行符 | 正确统计Title行的字符数、行数、单词、词组数(需注意字符数中包含一个Abstract行的换行符) |
| OnlyAbstract | 传入一个文件,文件中Title行仅包含一个换行符 | 正确统计Abstract行的字符数、行数、单词、词组数(需注意字符数中包含一个Title行的换行符) |
| WrongWord | 传入一个文件,文件中只存在非法单词 | 统计所得单词数,为0 |
| ValidWord | 传入一个文件,文件中每个有效行有且只有一个合法单词 | 正确统计单词数 |
| WrongPhrase | 传入一个文件,统计长度为2的词组,但文件中每个合法单词之间包含一个以上的非法单词 | 正确统计单词、词组数,词组数为0 |
| ValidPhrase | 传入一个文件,文件中每个有效行有且只有一个合法词组 | 正确统计词组数 |
| NoEmptyLine | 传入一个文件,文件中最后一篇论文以Title行结束且Title行不包含换行符(类似题目中的测试数据,论文最后不存在空行) | 正确统计字符数、行数、单词、词组数 |
单元测试运行结果如下图
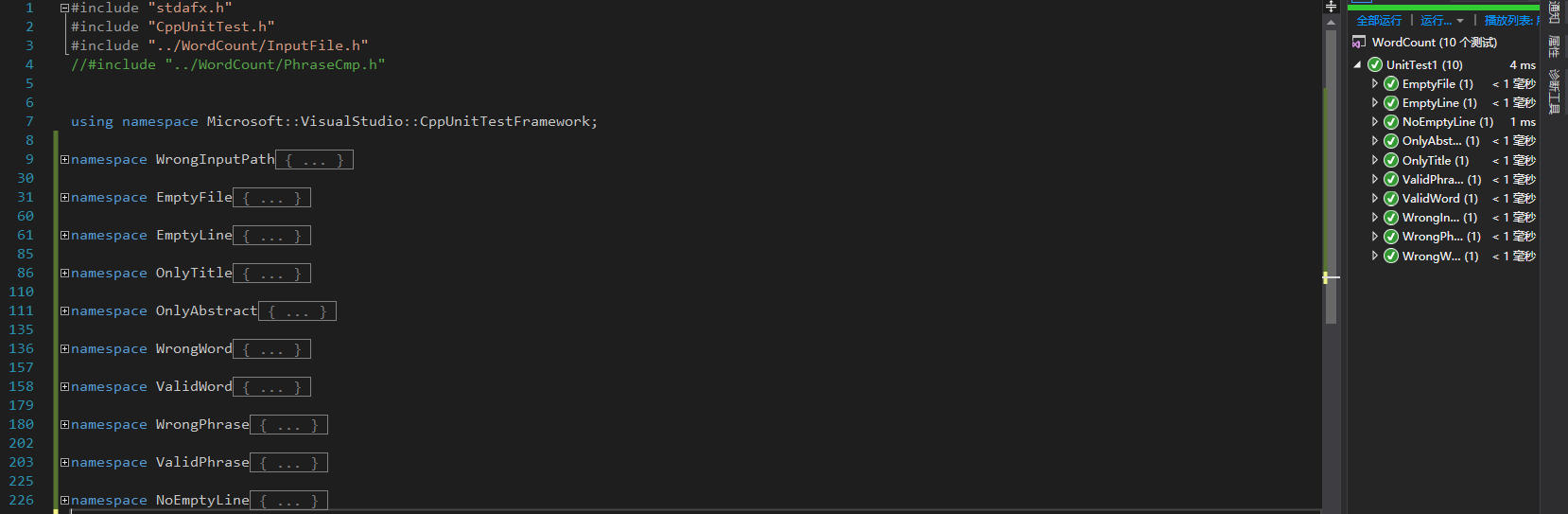
这里贴出EmptyFile WrongWord ValidWord的单元测试代码并以中文进行注释。
namespace EmptyFile
{
TEST_CLASS(UnitTest1)
{
public:
//文件为空即不存在字符,统计所得字符数、行数、单词、词组数,为0
TEST_METHOD(EmptyFile)
{
///*
string input = "D://project//vs//WordCount//UnitTest1//EmptyFile.txt";
int weight = 0;
int phraseLength = 1;
int sortNum = 10;
InputFile inputFile(input, phraseLength, weight, sortNum);
Assert::AreEqual(inputFile.getCrtNum(), 0);
Assert::AreEqual(inputFile.getLineNum(), 0);
Assert::AreEqual(inputFile.getWordNum(), 0);
Assert::AreEqual(inputFile.getPhraseNum(), 0);
}
};
}
namespace WrongWord
{
TEST_CLASS(UnitTest1)
{
public:
//文件中论文的Title行和Abstract行不存在有效单词,故统计所得单词数为0
TEST_METHOD(TestMethod1)
{
string input = "D://project//vs//WordCount//UnitTest1//WrongWord.txt";
int weight = 0;
int phraseLength = 1;
int sortNum = 10;
InputFile inputFile(input, phraseLength, weight, sortNum);
Assert::AreEqual(inputFile.getWordNum(), 0);
}
};
}
namespace ValidWord
{
TEST_CLASS(UnitTest1)
{
public:
//文件中论文的Title行和Abstract行各设置已出现一次且各存在一个有效单词,故统计所得单词数为2
TEST_METHOD(TestMethod1)
{
string input = "D://project//vs//WordCount//UnitTest1//ValidWord.txt";
int weight = 0;
int phraseLength = 1;
int sortNum = 10;
InputFile inputFile(input, phraseLength, weight, sortNum);
Assert::AreEqual(inputFile.getWordNum(), 2);
}
};
}
9. 贴出Github的代码签入记录

10. 遇到的代码模块异常或结对困难及解决方法
bug1:只会单词只会进入统计一次
修复方法:在char数组wordArray中多存一个单词,在达到(要求)个单词时存入phraseLength个单词, 每次读取词组后指针后移一个词缀的距离
bug2:在词组长度为1时词组判断时会产生异常
修复方法:仅在词组长度>1时进入词组判断(其余时候为单个单词的统计,和上次词频统计基本相同)
bug3:文件中第二篇论文开始,tempChar不能正常读取字符
修复方法:不知道为什么,莫名其妙就好了
11. 评价你的队友
值得学习的地方
学习能力强,个人能力强
需要改进的地方
审美(特别是上次模型设计)
12. 学习进度条
| 第N周 | 新增代码 | 累计代码 | 本周学习耗时 | 累计学习耗时 | 重要成长 |
|---|---|---|---|---|---|
| 3 | 512 | 972 | 12 | 22 | 安卓后台 |