ZAB 协议算法
ZooKeeper 最核心的作用就是保证分布式系统的数据一致性,而无论是处理来自客户端的会话请求时,还是集群 Leader 节点发生重新选举时,都会产生数据不一致的情况。为了解决这个问题,ZooKeeper 采用了 ZAB 协议算法。
ZAB 协议算法(Zookeeper Atomic Broadcast ,Zookeeper 原子广播协议)是 ZooKeeper 专门设计用来解决集群最终一致性问题的算法,它的两个核心功能点是崩溃恢复和原子广播协议。
崩溃恢复
崩溃恢复机制是保证 ZooKeeper 集群服务高可用的关键。触发 ZooKeeper 集群执行崩溃恢复的事件是集群中的 Leader 节点服务器发生了异常而无法工作,于是 Follow 服务器会通过投票来决定是否选出新的 Leader 节点服务器。
投票过程如下:当崩溃恢复机制开始的时候,整个 ZooKeeper 集群的每台 Follow 服务器会发起投票,并同步给集群中的其他 Follow 服务器。在接收到来自集群中的其他 Follow 服务器的投票信息后,集群中的每个 Follow 服务器都会与自身的投票信息进行对比,如果判断新的投票信息更合适,则采用新的投票信息作为自己的投票信息。在集群中的投票信息还没有达到超过半数原则的情况下,再进行新一轮的投票,最终当整个 ZooKeeper 集群中的 Follow 服务器超过半数投出的结果相同的时候,就会产生新的 Leader 服务器。
消息广播
在 Leader 节点服务器处理请求后,需要通知集群中的其他角色服务器进行数据同步。ZooKeeper 集群采用消息广播的方式发送通知。
ZooKeeper 集群使用原子广播协议进行消息发送,如下图所示
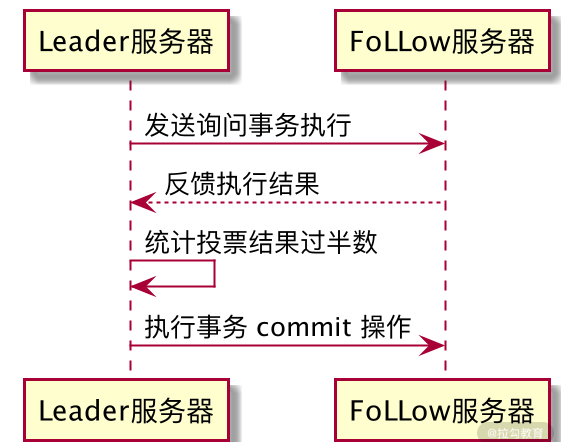
当要在集群中的其他角色服务器进行数据同步的时候,Leader 服务器将该操作过程封装成一个 Proposal 提交事务,并将其发送给集群中其他需要进行数据同步的服务器。当这些服务器接收到 Leader 服务器的数据同步事务后,会将该条事务能否在本地正常执行的结果反馈给 Leader 服务器,Leader 服务器在接收到其他 Follow 服务器的反馈信息后进行统计,判断是否在集群中执行本次事务操作。