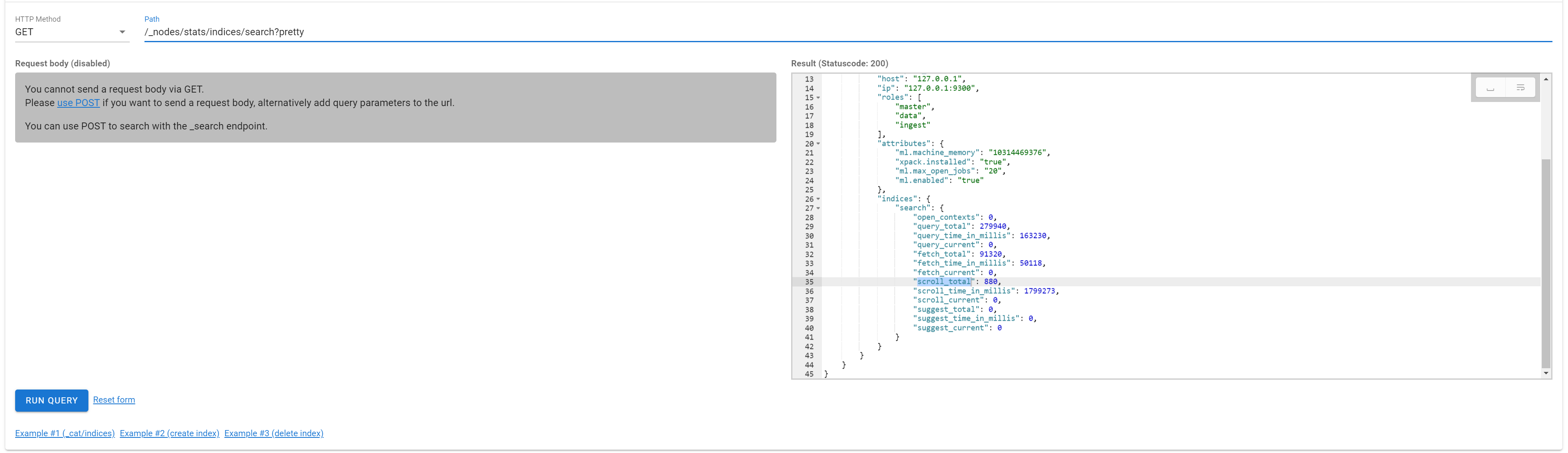
ElasticSearch的深度分页
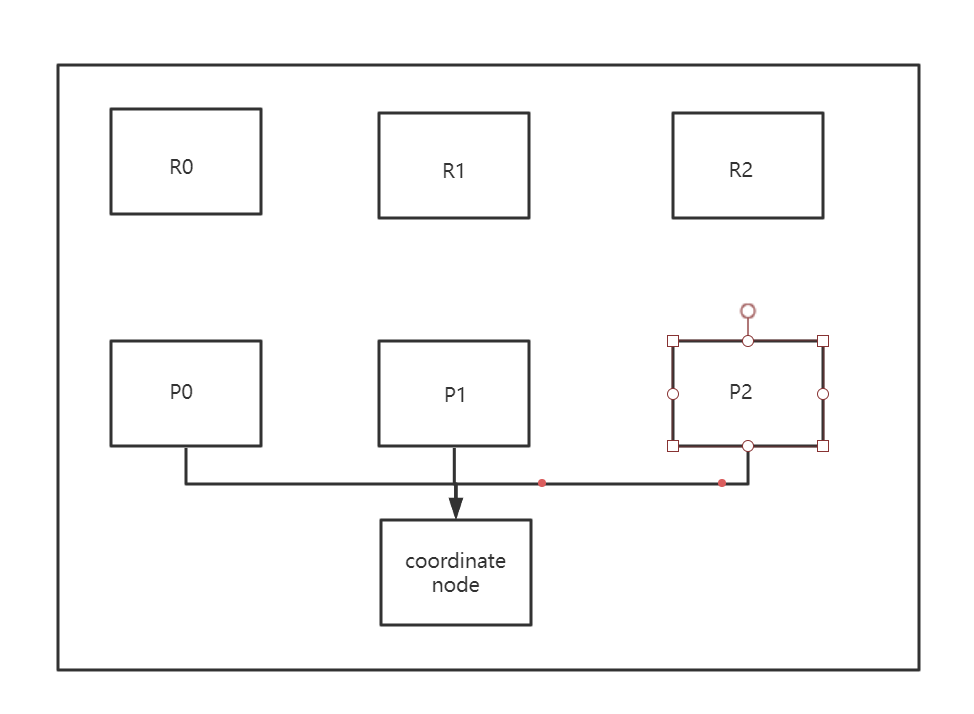
coordinate node节点
搜索和bulk等请求可能会涉及到多个节点上的不同shard里的数据,比如一个search请求,就需要两个阶段执行,首先第一个阶段就是一个coordinating node接收到这个客户端的search request。接着,coordinating node会将这个请求转发给存储相关数据的node,每个data node都会在自己本地执行这个请求操作,同时返回结果给coordinating node,接着coordinating node会将返回过来的所有的请求结果进行缩减和合并,合并为一个global结果。
每个node都是一个coordinating node。这就意味着如果一个node,将node.master,node.data,node.ingest全部设置为false,那么它就是一个纯粹的coordinating node,仅仅用于接收客户端的请求,同时进行请求的转发和合并。
分页查询的流程
以前项目中主要用的solr,当分页到几十万页的时候,就会要等2秒左右,有一定的延迟,ElasticSearch也有这样的问题。
常见深度分页方式 from+size
es 默认采用的分页方式是 from+ size 的形式,在深度分页的情况下,这种使用方式效率是非常低的,比如from = 10000, size=10,首先请求可能会请求到不包含这个index的shard的node上去,这个node就是一个coordinate node,那么这个coordinate node就会将搜索请求转发到index的三个shard所在node上。 es 需要在各个分片上匹配排序并得到10010条有效数据,如果是3个shard的话,那么协调节点就会拿到30030节点,然后对这些数据进行排序,相关度分数 ,在结果集中取最后10条数据返回,这种方式类似于mongo的 skip + size。
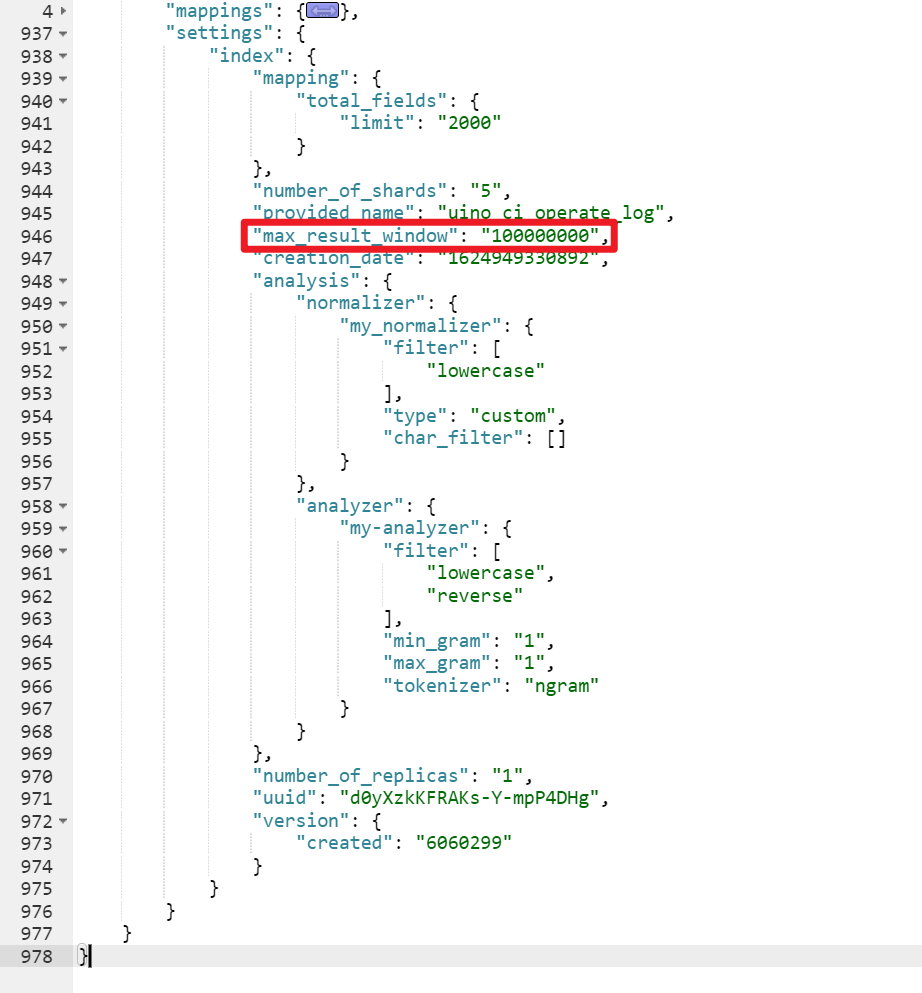
除了效率上的问题,还有一个无法解决的问题是,es 目前支持最大的 skip 值是 max_result_window ,默认为 10000 。也就是当 from + size > max_result_window 时,es 将返回错误,我们项目中是将它设置10000000。
 但是这种数据量大的话,还是治标不治本,其实还可以通过scroll来实现
但是这种数据量大的话,还是治标不治本,其实还可以通过scroll来实现
分页方式 scroll
如果一次性要查出来比如10万条数据,那么性能会很差,此时一般会采取用scoll滚动查询,一批一批的查,直到所有数据都查询完处理完。
使用scoll滚动搜索,可以先搜索一批数据,然后下次再搜索一批数据,以此类推,直到搜索出全部的数据来scoll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的。
采用基于_doc进行排序的方式,性能较高每次发送scroll请求,我们还需要指定一个scoll参数,指定一个时间窗口,每次搜索请求只要在这个时间窗口内能完成就可以了。
原理上是对某次查询生成一个游标 scroll_id , 后续的查询只需要根据这个游标去取数据,直到结果集中返回的 hits 字段为空,就表示遍历结束。scroll_id 的生成可以理解为建立了一个临时的历史快照,在此之后的增删改查等操作不会影响到这个快照的结果。
使用 curl 进行分页读取过程如下:
先获取第一个 scroll_id,url 参数包括 /index/_type/ 和 scroll,scroll 字段指定了scroll_id 的有效生存期,以分钟为单位,过期之后会被es 自动清理。如果文档不需要特定排序,可以指定按照文档创建的时间返回会使迭代更高效。
{
"query": {
"match_all": {}
},
"sort": [ "_doc" ],
"size": 3
}
返回的结果如下:
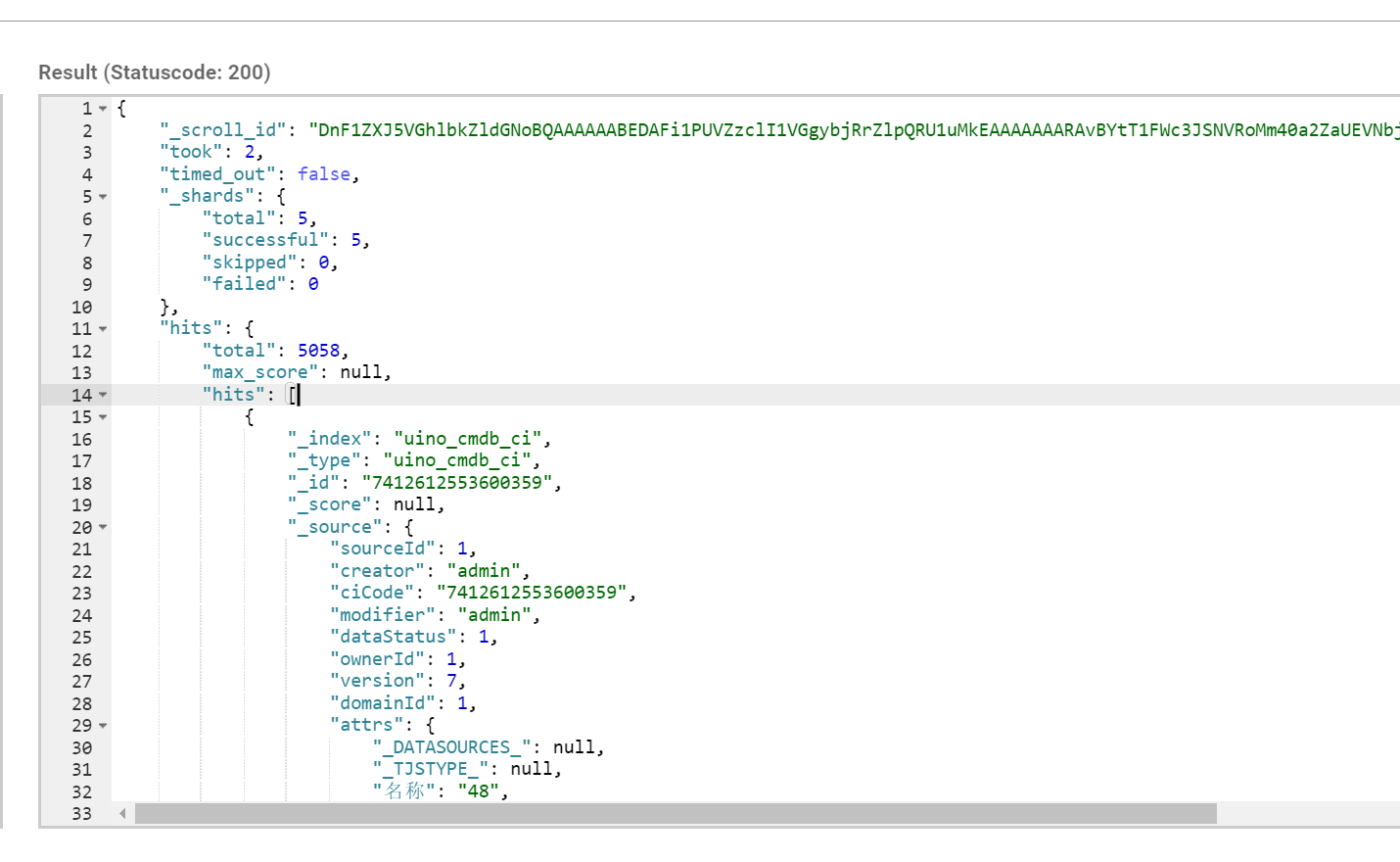
后续的文档读取上一次查询返回的scroll_id 来不断的取下一页,如果srcoll_id 的生存期很长,那么每次返回的 scroll_id 都是一样的,直到该 scroll_id 过期,才会返回一个新的 scroll_id。请求指定的 scroll_id 时就不需要 /index/_type 等信息了。每读取一页都会重新设置 scroll_id 的生存时间,所以这个时间只需要满足读取当前页就可以,不需要满足读取所有的数据的时间,1 分钟足以。
{
"scroll": "1m",
"scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAABEDCFi1PUVZzclI1VGgybjRrZlpQRU1uMkEAAAAAAARAxBYtT1FWc3JSNVRoMm40a2ZaUEVNbjJBAAAAAAAEQMEWLU9RVnNyUjVUaDJuNGtmWlBFTW4yQQAAAAAABEDFFi1PUVZzclI1VGgybjRrZlpQRU1uMkEAAAAAAARAwxYtT1FWc3JSNVRoMm40a2ZaUEVNbjJB"
}
public List<T> getListByScroll(String scrollId) {
Scroll scroll = new Scroll(TimeValue.timeValueMinutes(3L));
SearchResponse searchResponse = null;
JSONArray rs = new JSONArray();
try {
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
scrollRequest.scroll(scroll);
searchResponse = getClient().scroll(scrollRequest, RequestOptions.DEFAULT);
SearchHit[] searchHits = searchResponse.getHits().getHits();
for (SearchHit hit : searchHits) {
String res = hit.getSourceAsString();
JSONObject result = JSON.parseObject(res);
rs.add(result);
}
} catch (IOException e) {
log.error(e.getMessage(), e);
}
return rs.toJavaList(clazz);
}
返回结果
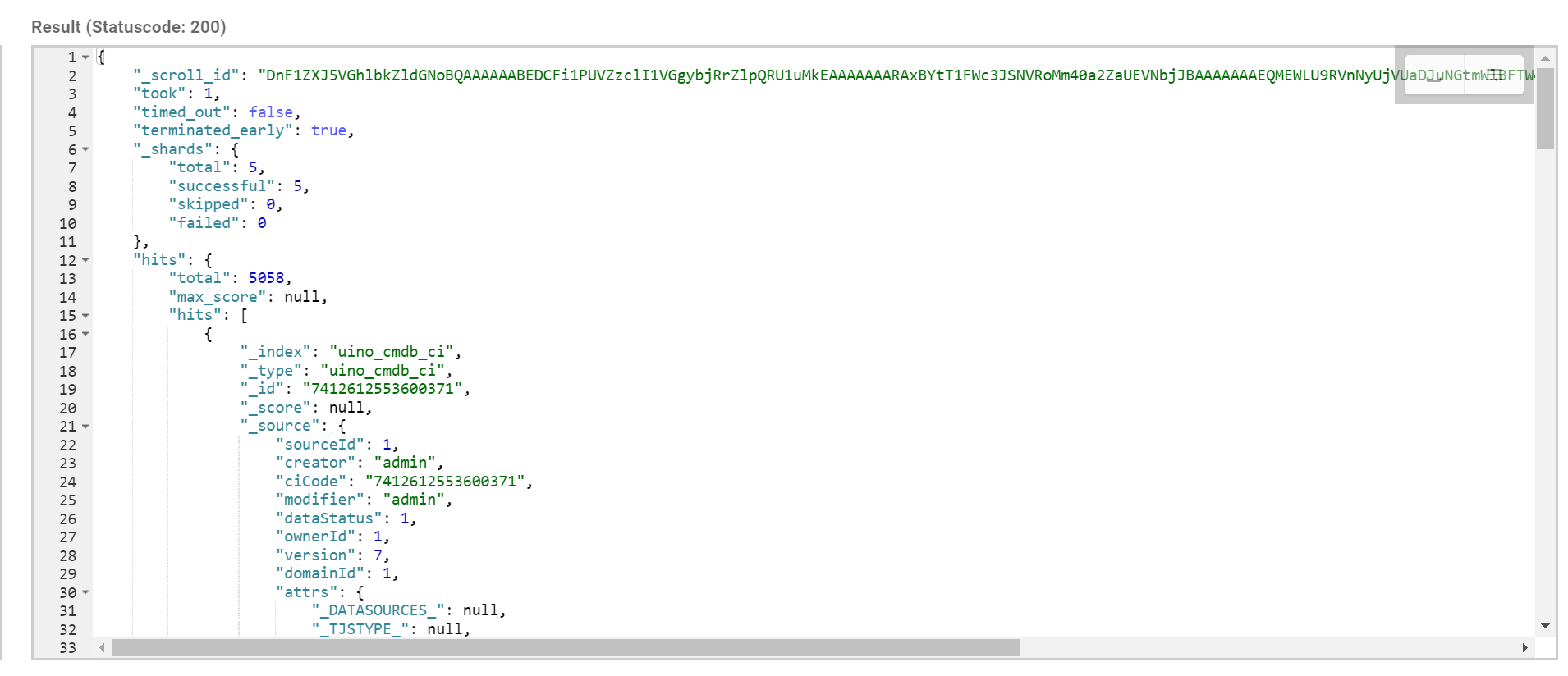
所有文档获取完毕之后,需要手动清理掉 scroll_id 。虽然es 会有自动清理机制,但是 srcoll_id 的存在会耗费大量的资源来保存一份当前查询结果集映像,并且会占用文件描述符。所以用完之后要及时清理。使用 es 提供的 CLEAR_API 来删除指定的 scroll_id
删掉指定的srcoll_id
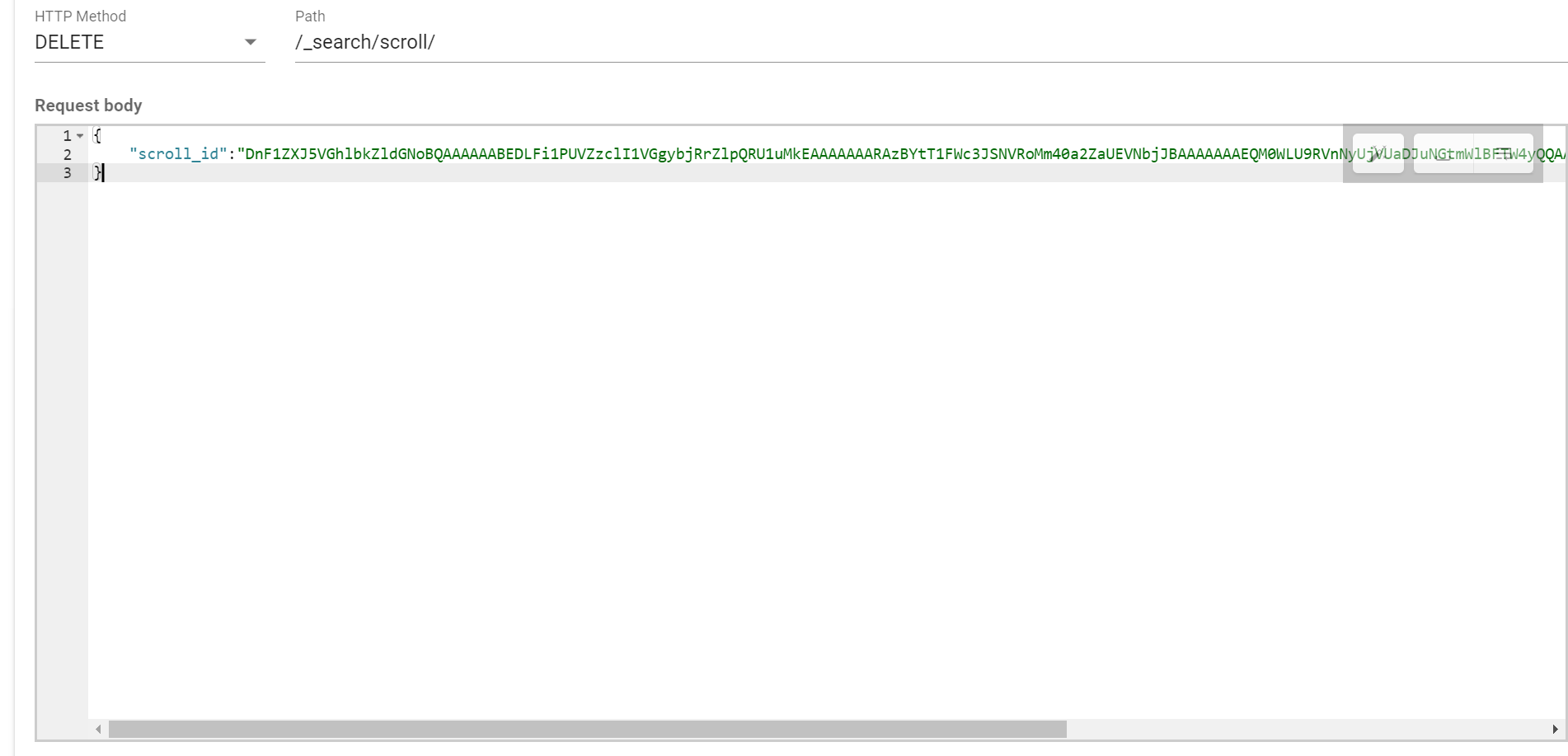
删除掉所有索引上的 scroll_id

public Integer clearScroll(String scrollId) {
Integer flag = 1;
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
try {
getClient().clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
flag = 0;
}
return flag;
}
查询当前所有的scroll 状态