1.大量小文件影响
NameNode存储着文件系统的元数据,每个文件、目录、块大概有150字节的元数据,因此文件数量的限制也由NameNode内存大小决定,如果小文件过多则会造成NameNode的压力过大,且hdfs能存储的数据量也会变小
2.HAR文件方案
本质启动mr程序,需要启动yarn

用法:archive -archiveName <NAME>.har -p <parent path> [-r <replication factor>]<src>* <dest>
1)创建归档文件 tip:归档文件一定要保证yarn集群启动
cd /kkb/install/hadoop-2.6.0-cdh5.14.2 bin/hadoop archive -archiveName myhar.har -p /user/hadoop /user
2)查看归档文件内容
hdfs dfs -lsr /user/myhar.har hdfs dfs -lsr har:///user/myhar.har
3)解压归档文件
hdfs dfs -mkdir -p /user/har hdfs dfs -cp har:///user/myhar.har/* /user/har/
3.Sequence Files方案
SequenceFile文件主要由一条条record记录组成,每个record是键值对形式;
SequenceFile文件可以作为小文件的存储容器;
a)每条record保存一个小文件的内容
b)小文件名为当前record的键
c)小文件的内容作为当前record的值
d)如10000个100kb的小文件,可以编写程序将这些文件放到一个SequenceFile文件
SequenceFile是可分割的,所以MapReduce可将一个文件切分成块,每一块独立操作;
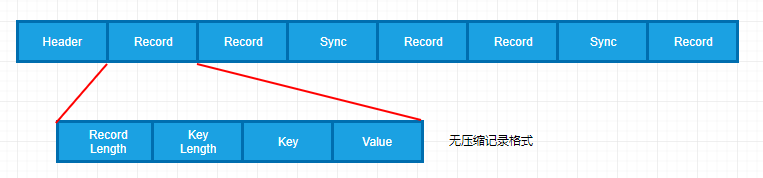
SequenceFile文件结构;
一个SequenceFile首先有一个4字节的header(文件版本号)
接着是若干record记录
记录间会随机的插入一些同步点sync marker,用于方便定位到记录边界

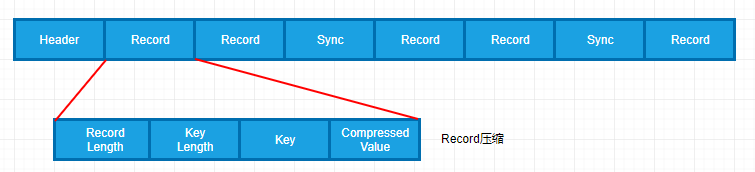
SequenceFile支持压缩,有两种压缩方式,记录的结构取决于是否启动压缩
无压缩:
record压缩:
block压缩:
一次压缩多条记录,每个新块block(SequenceFile中的block)开始处都需要插入同步点

在大多数的情况下,以block为单位进行压缩是最好的选择,因为一个block包含多条记录,利用record间的相似性进行压缩,压缩效率高
把已有的数据转存为SequenceFile比较慢。比起先写小文件,在将小文件写入SequenceFile,一个更好的选择是直接将数据写入一个SequenceFile文件,省去小文件作为中间媒介;
SequenceFile写入数据


package com.kaikeba.hadoop.sequencefile; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.SequenceFile; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.compress.BZip2Codec; import java.io.IOException; import java.net.URI; public class SequenceFileWriteNewVersion { //模拟数据源 private static final String[] DATA = { "The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.", "It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.", "Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer", "o delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.", "Hadoop Common: The common utilities that support the other Hadoop modules." }; public static void main(String[] args) throws IOException { //输出路径:要生成的SequenceFile文件名 String uri = "hdfs://node01:8020/writeSequenceFile"; Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create(uri), conf); //向HDFS上的此SequenceFile文件写数据 Path path = new Path(uri); //因为SequenceFile每个record是键值对的 //指定key类型 IntWritable key = new IntWritable(); //指定value类型 Text value = new Text(); // // FileContext fileContext = FileContext.getFileContext(URI.create(uri)); // Class<?> codecClass = Class.forName("org.apache.hadoop.io.compress.SnappyCodec"); // CompressionCodec SnappyCodec = (CompressionCodec)ReflectionUtils.newInstance(codecClass, conf); // SequenceFile.Metadata metadata = new SequenceFile.Metadata(); // //writer = SequenceFile.createWriter(fs, conf, path, key.getClass(), value.getClass()); // writer = SequenceFile.createWriter(conf, SequenceFile.Writer.file(path), SequenceFile.Writer.keyClass(IntWritable.class), // SequenceFile.Writer.valueClass(Text.class)); //创建向SequenceFile文件写入数据时的一些选项 //要写入的SequenceFile的路径 SequenceFile.Writer.Option pathOption = SequenceFile.Writer.file(path); //record的key类型选项 SequenceFile.Writer.Option keyOption = SequenceFile.Writer.keyClass(IntWritable.class); //record的value类型选项 SequenceFile.Writer.Option valueOption = SequenceFile.Writer.valueClass(Text.class); //SequenceFile压缩方式:NONE | RECORD | BLOCK三选一 //方案一:RECORD、不指定压缩算法 SequenceFile.Writer.Option compressOption = SequenceFile.Writer.compression(SequenceFile.CompressionType.RECORD); SequenceFile.Writer writer = SequenceFile.createWriter(conf, pathOption, keyOption, valueOption, compressOption); //方案二:BLOCK、不指定压缩算法 // SequenceFile.Writer.Option compressOption = SequenceFile.Writer.compression(SequenceFile.CompressionType.BLOCK); // SequenceFile.Writer writer = SequenceFile.createWriter(conf, pathOption, keyOption, valueOption, compressOption); //方案三:使用BLOCK、压缩算法BZip2Codec;压缩耗时间 //再加压缩算法 // BZip2Codec codec = new BZip2Codec(); // codec.setConf(conf); // SequenceFile.Writer.Option compressAlgorithm = SequenceFile.Writer.compression(SequenceFile.CompressionType.RECORD, codec); // //创建写数据的Writer实例 // SequenceFile.Writer writer = SequenceFile.createWriter(conf, pathOption, keyOption, valueOption, compressAlgorithm); for (int i = 0; i < 10000; i++) { //分别设置key、value值 key.set(100 - i); value.set(DATA[i % DATA.length]); System.out.printf("[%s] %s %s ", writer.getLength(), key, value); //在SequenceFile末尾追加内容 writer.append(key, value); } //关闭流 IOUtils.closeStream(writer); } }
命令查看SequenceFile内容
hadoop fs -text /writeSequenceFile
读取SequenceFile
package com.kaikeba.hadoop.sequencefile; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.SequenceFile; import org.apache.hadoop.io.Writable; import org.apache.hadoop.util.ReflectionUtils; import java.io.IOException; public class SequenceFileReadNewVersion { public static void main(String[] args) throws IOException { //要读的SequenceFile String uri = "hdfs://node01:8020/writeSequenceFile"; Configuration conf = new Configuration(); Path path = new Path(uri); //Reader对象 SequenceFile.Reader reader = null; try { //读取SequenceFile的Reader的路径选项 SequenceFile.Reader.Option pathOption = SequenceFile.Reader.file(path); //实例化Reader对象 reader = new SequenceFile.Reader(conf, pathOption); //根据反射,求出key类型 Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(), conf); //根据反射,求出value类型 Writable value = (Writable) ReflectionUtils.newInstance(reader.getValueClass(), conf); long position = reader.getPosition(); System.out.println(position); while (reader.next(key, value)) { String syncSeen = reader.syncSeen() ? "*" : ""; System.out.printf("[%s%s] %s %s ", position, syncSeen, key, value); position = reader.getPosition(); // beginning of next record } } finally { IOUtils.closeStream(reader); } } }