一简介:参考了几位师兄,尤其是M哥大神的博客,让我恍然大悟,赶紧记录下
二 原理:
mysql的三种算法
1 Simple Nested-Loop Join

将驱动表/外部表的结果集作为循环基础数据,然后循环从该结果集每次一条获取数据作为下一个表的过滤条件查询数据,然后合并结果。如果有多表join,则将前面的表的结果集作为循环数据,取到每行再到联接的下一个表中循环匹配,获取结果集返回给客户端。
注意点:单条记录一条一条进行 比如C 表有N条记录去匹配D表 M 条记录那么要执行 NXM次,如果多表join,那么次数会更多
关键字 笛卡尔积
2 Block Nested-Loop Join
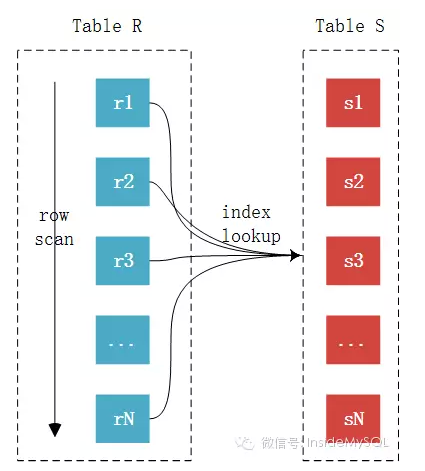
BNL优化,在join字段无索引的情况下
Block Nested-Loop Join对比Simple Nested-Loop Join多了一个中间处理的过程,也就是join buffer,使用join buffer将驱动表的查询JOIN相关列都给缓冲到了JOIN BUFFER当中,然后批量与非驱动表进行比较,这也来实现的话,可以将多次比较合并到一次,降低了非驱 动表的访问频率。也就是只需要访问一次S表。这样来说的话,就不会出现多次访问非驱动表的情况了,也只有这种情况下才会访问join buffer。
注意点:
1 此算法并非单条记录匹配,而是多条记录合并一起匹配,减少了匹配次数,提高了效率
2 此优化手段是在mysql5.5+版本开始出现,默认是打开状态
3 出现标识
explain生成解析树后出现 Using join buffer (Block Nested Loop) 连接字段无索引,但是利用了BNL优化了语句
4 能够被buffer的每一个join都会分配一个buffer, 也就是说一个query最终可能会使用多个join buffer
5 join buffer中只会保存参与join的列, 并非整个数据行。
6 只有在join类型为all, index, range的时候才可以使用join buffer。
3 Index Nested-Loop Join
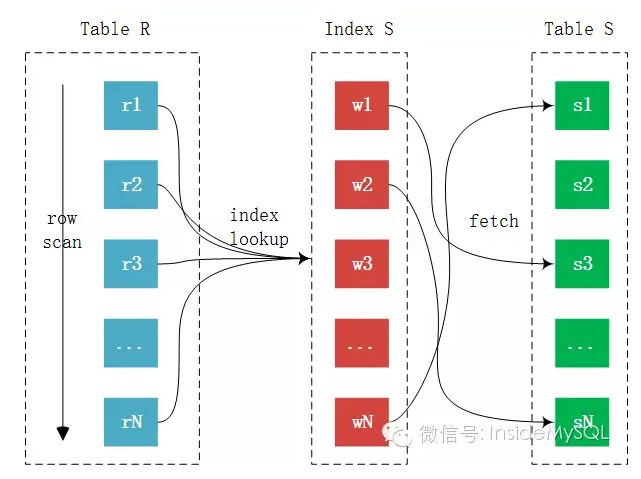
这种算法在链接查询的时候,驱动表会根据关联字段的索引进行查找,当在索引上找到了符合的值,再回表进行查询,也就是只有当匹配到索引以后才会进行回表。至于驱动表的选择,MySQL优化器一般情况下是会选择记录数少的作为驱动表,但是当SQL特别复杂的时候不排除会出现错误选择。
注意点:
mysql多表join速度之所以慢的原因之一 就是连接字段和查询条件都并非主键,访问辅助索引或者无索引列 一旦要获取列值,必然要回表,辅助索引的index lookup是比较随机I/O访问操作。其次,根据index lookup再进行回表又是一个随机的I/O操作。所以说,INLJ最大的弊端是其可能需要大量的离散操作,这在SSD出现之前是最大的瓶颈。而即使SSD的出现大幅提升了随机的访问性能,但是对比顺序I/O,其还是慢了很多,依然不在一个数量级上。属于随机IO的操作
三 相关总结:
1 多表join查询要保证小结果集驱动大结果集作为优化选择
2 减少回表操作和匹配次数是算法的核心思想
3 多表join查询要保证连接join的字段都有索引
4 varchar作为主键进行连接查询是无法走索引的,会出现BNL优化(要特别注意)
5 对于无法走索引的join查询建议拆分或者更改条件
6 对于order by所选择的字段要尽量选用驱动表带索引字段
四 核心的东西来源于M哥的博客