image Matters: Jointly Train Advertising CTR Model with Image Representation of Ad and User Behavior
阿里 2017 发表在 arxiv 的文章,与前面文章的区别在于,图像不单可以表征广告,用户点过的图像集合也可以用来表征用户,比如当前图片与用户点过的某张图片很相似,用户的点击概率就会比较高。文章利用广告相关id特征、用户相关id特征、广告图像特征、用户点击过的图像特征共同建模,end-to-end训练,预测最终的ctr。这篇文章对标 youtube 那篇做推荐的文章Deep Neural Networks for YouTube Recommendations里面的 rank model部分。
点击率模型经常用到的 parameter server logistic regression(PSLR) 更擅长于记忆,而不是泛化,所以即使在rank模型中,遇到新的 id 时,还是存在冷启动问题。图像特征重要,相同的广告id用不同的图片,点击率可能完全不一样,所以图像特征其实有比较好的泛化能力,不同的广告用同一张图像,在用户无法分辨的情况下,点击率相同。
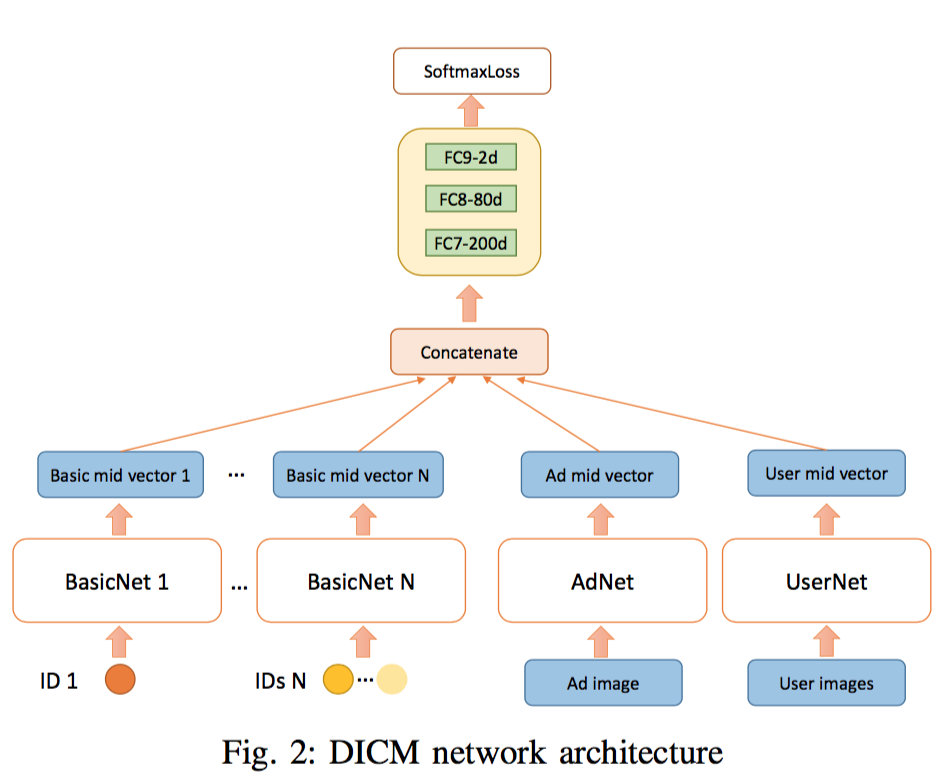
basicNet 和阿里那篇 Deep CTR Prediction in Display Advertising 一脉相承,通过全连接做 id 特征的向量化。AdNet采用VGG16的前14层,从图像提取 4096 维特征。可能是由于网络结果过于复杂,这里的卷积层是固定的,在rank部分不会调整,这样做也有一个好处,可以先把所有图片的 4096 维特征预先计算出来,CNN不用多次重复计算,也不需要更新权重,训练效率会高很多。固定CNN实际上也有不得已的地方,本文的创新点在于利用了UserNet,但是UseNet带来的一个弊端是,无法像之前两篇文章里将相同图片的样本聚合起来减少CNN部分的计算,因为UserNet的输入平均是37张图片的排列组合。在4096 维特征后面,又加入可训练的三个全连接层,把一张图像的特征降低到 12 维。

UserNet 的结构与 AdNet一致,区别在于,用户点击包含多张图片(平均37张),如何把多张图片的12维特征整合成单独的12维,其中有一些简单的做法如 sum、avg、max,也有一些复杂的 attentive方法。

根据后面训练的attentive权重来看,用户对相似图片的权重明显大。
实验对比
-
39亿样本,2亿图片,20台GPU集群训练,17个小时
-
实验结果可以看到图像特征有一些提升,但是在添加用户点击行为中的图像特征,边际效益不是那么高。

附:公众号
