# 2018-12-06 15:39:10 重新整理一下这篇文章:
之前的代码主要参考这篇 kaggle - titanic 入门教程:https://www.kaggle.com/startupsci/titanic-data-science-solutions
教程其实写得非常好,基本的处理思路让人觉得简明易懂,但当时对机器学习的理解很浅(现在也依然很浅233),基本上只是依葫芦画瓢,整理了一下代码而已,有些地方都不是太明白。
下面再粗略谈谈。
观察并理解数据集是必要的,我们应该想办法将要训练的和测试的两份数据集中的杂物清理干净,并统一标签。
还要弄清楚目的,Survived是我们要对test sets预测的结果。
沿用教程部分思路(没有对Name标签做处理等):
import pandas as pd
from sklearn import metrics
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
train = pd.read_csv('datasets/train.csv')
test = pd.read_csv('datasets/test.csv')
resu = pd.read_csv('datasets/gender_submission.csv')
y_true = resu['Survived']
train_y = train['Survived']
train_x = train.drop(['PassengerId', 'Survived', 'Name', 'Ticket', 'Cabin'], axis=1)
test_x = test.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1)
combine = [train_x, test_x]
for dataset in combine:
freq_port = dataset.Embarked.dropna().mode()[0]
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
dataset['Embarked'] = dataset['Embarked'].map({'S': 0, 'C': 1, 'Q': 2}).astype(int)
dataset['Sex'] = dataset['Sex'].map({'female': 1, 'male': 0}).astype(int)
dataset['Age'].fillna(dataset['Age'].dropna().median(), inplace=True)
dataset.loc[dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[dataset['Age'] > 48, 'Age'] = 3
dataset['Age'] = dataset['Age'].astype(int)
dataset['Fare'].fillna(dataset['Fare'].dropna().median(), inplace=True)
dataset.loc[dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
model = DecisionTreeClassifier()
model.fit(train_x, train_y)
pred = model.predict(test_x)
print(metrics.accuracy_score(y_true=y_true, y_pred=pred))
# submission = pd.DataFrame({
# "PassengerId": test["PassengerId"],
# "Survived": pred
# })
#
# submission.to_csv("datasets/submission.csv", index=False)
最后提交,线上评分是0.75......,记得好像是8000多名。
PS:数据集中有船舱号的乘客基本都是 Pclass = 1,Pclass >= 2 的非常少:
Pclass = 3:
cabins = train_df.Cabin[train_df.Pclass == 3].value_counts() print(cabins)
Output:

G6舱中有4个人(这意味着他们应该是一个家族的),还有就是貌似乘客等级越低船舱的甲板位置应该会不太好,所以字母 A,B,C,D,E,F,G,T 应该就是代表甲板位置:
Pclass = 1:
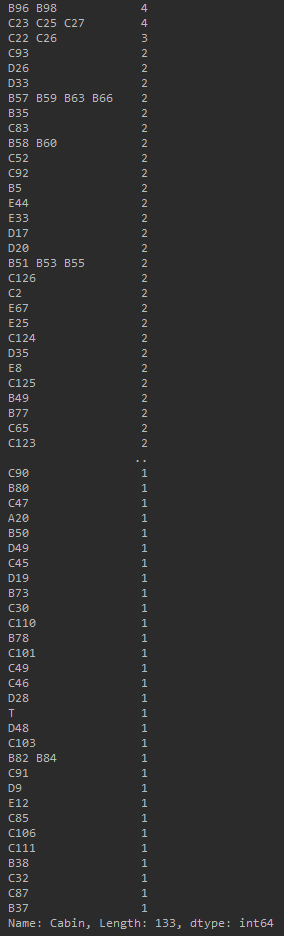
基本上都是在D以下,少数在E、T。
Pclass 2:
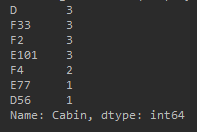
稍微有点不太直观,换个写法:
cabins = train_df.Cabin[train_df.Pclass == 3].count()
print('Pclass 3:', cabins)
Output:
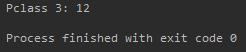
Pclass = 2:

Pclass >= 2:

Pclass = 1:

然后就是剩下的就是缺失值。
然而可以理解为整艘船上 Pclass = 3 的乘客最多(共 491 个),所以缺失的船舱信息也会相对较多(共丢失 479 条船舱信息数据)。
ps:Pclass = 2 的乘客中共丢失 168 条数据, Pclass = 1 的乘客中共丢失 40 条数据。
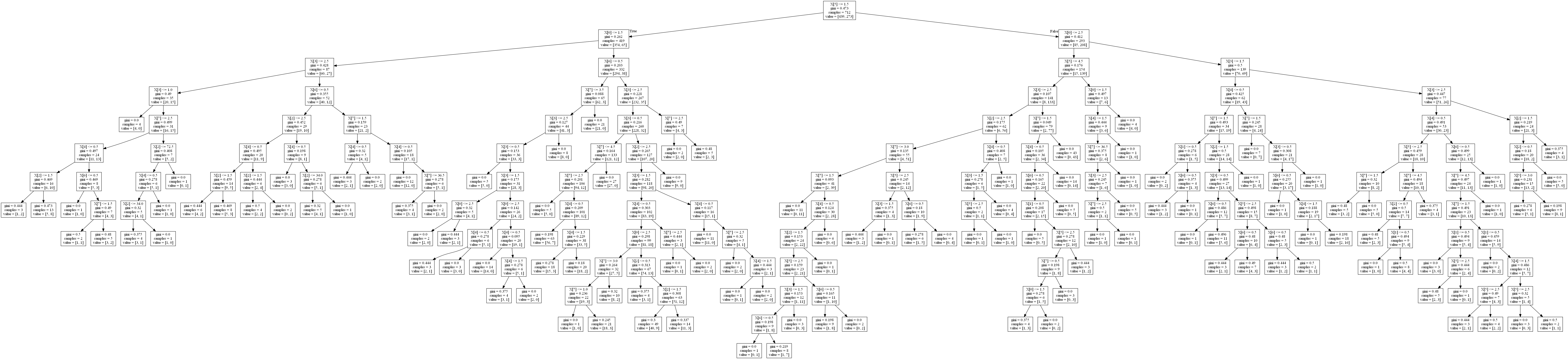
最近发现sklearn中还有个功能可以展示训练好的模型的决策树,下面就简单的说说如何使用。
以这篇泰坦尼克为例,首先在代码中引入这个方法:
from sklearn.tree import export_graphviz
在决策树训练好模型后,即fit过训练集后使用:
decision = DecisionTreeClassifier() x_train, x_test, y_train, y_test = train_test_split(X_train, Y_train, test_size=0.2, random_state=0) decision.fit(x_train, y_train) export_graphviz(decision, 'decision.gv')
然后,在上面代码中decision.gv生成的路径下打开cmd键入(需要配置好graphviz,才能使用dot命令):
dot decision.gv -T png -o tree.png
然后打开tree.png看看(这里生成的图有点大):