转自https://www.cnblogs.com/duanxz/p/3511695.html
serialVersionUID适用于Java的序列化机制。简单来说,Java的序列化机制是通过判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是InvalidCastException。
具体的序列化过程是这样的:序列化操作的时候系统会把当前类的serialVersionUID写入到序列化文件中,当反序列化时系统会去检测文件中的serialVersionUID,判断它是否与当前类的serialVersionUID一致,如果一致就说明序列化类的版本与当前类版本是一样的,可以反序列化成功,否则失败。
serialVersionUID有两种显示的生成方式:
一是默认的1L,比如:private static final long serialVersionUID = 1L;
二是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段,比如:
private static final long serialVersionUID = xxxxL;
当一个类实现了Serializable接口,如果没有显示的定义serialVersionUID,Eclipse会提供相应的提醒。面对这种情况,我们只需要在Eclipse中点击类中warning图标一下,Eclipse就会 自动给定两种生成的方式。如果不想定义,在Eclipse的设置中也可以把它关掉的,设置如下:
Window ==> Preferences ==> Java ==> Compiler ==> Error/Warnings ==> Potential programming problems
将Serializable class without serialVersionUID的warning改成ignore即可。
当实现java.io.Serializable接口的类没有显式地定义一个serialVersionUID变量时候,Java序列化机制会根据编译的Class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,如果Class文件(类名,方法明等)没有发生变化(增加空格,换行,增加注释等等),就算再编译多次,serialVersionUID也不会变化的。
如果我们不希望通过编译来强制划分软件版本,即实现序列化接口的实体能够兼容先前版本,就需要显式地定义一个名为serialVersionUID,类型为long的变量,不修改这个变量值的序列化实体都可以相互进行串行化和反串行化。
下面用代码说明一下serialVersionUID在应用中常见的几种情况。
(1)序列化实体类
package com.sf.code.serial;
import java.io.Serializable;
public class Person implements Serializable {
private static final long serialVersionUID = 123456789L;
public int id;
public String name;
public Person(int id, String name) {
this.id = id;
this.name = name;
}
public String toString() {
return "Person: " + id + " " + name;
}
}
2)序列化功能:
package com.sf.code.serial;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class SerialTest {
public static void main(String[] args) throws IOException {
Person person = new Person(1234, "wang");
System.out.println("Person Serial" + person);
FileOutputStream fos = new FileOutputStream("Person.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(person);
oos.flush();
oos.close();
}
}
3)反序列化功能:
package com.sf.code.serial;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class DeserialTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Person person;
FileInputStream fis = new FileInputStream("Person.txt");
ObjectInputStream ois = new ObjectInputStream(fis);
person = (Person) ois.readObject();
ois.close();
System.out.println("Person Deserial" + person);
}
}
情况一:假设Person类序列化之后,从A端传输到B端,然后在B端进行反序列化。在序列化Person和反序列化Person的时候,A端和B端都需要存在一个相同的类。如果两处的serialVersionUID不一致,会产生什么错误呢?
【答案】可以利用上面的代码做个试验来验证:
先执行测试类SerialTest,生成序列化文件,代表A端序列化后的文件,然后修改serialVersion值,再执行测试类DeserialTest,代表B端使用不同serialVersion的类去反序列化,结果报错:
Exception in thread "main" java.io.InvalidClassException: com.sf.code.serial.Person; local class incompatible: stream classdesc serialVersionUID = 1234567890, local class serialVersionUID = 123456789
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:621)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1623)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1518)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1774)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1351)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:371)
at com.sf.code.serial.DeserialTest.main(DeserialTest.java:13)
情况二:假设两处serialVersionUID一致,如果A端增加一个字段,然后序列化,而B端不变,然后反序列化,会是什么情况呢?
package com.sf.code.serial;
import java.io.Serializable;
public class Person implements Serializable {
private static final long serialVersionUID = 1234567890L;
public int id;
public String name;
public int age;
public Person(int id, String name) {
this.id = id;
this.name = name;
}
public Person(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public String toString() {
return "Person: " + id
+ ",name:" + name
+ ",age:" + age;
}
}
public class SerialTest {
public static void main(String[] args) throws IOException {
Person person = new Person(1234, "wang", 100);
System.out.println("Person Serial" + person);
FileOutputStream fos = new FileOutputStream("Person.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(person);
oos.flush();
oos.close();
}
}
Person DeserialPerson: 1234,name:wang
【答案】新增 public int age; 执行SerialTest,生成序列化文件,代表A端。删除 public int age,反序列化,代表B端,最后的结果为:执行序列化,反序列化正常,但是A端增加的字段丢失(被B端忽略)。
情况三:假设两处serialVersionUID一致,如果B端减少一个字段,A端不变,会是什么情况呢?
package com.sf.code.serial;
import java.io.Serializable;
public class Person implements Serializable {
private static final long serialVersionUID = 1234567890L;
public int id;
//public String name;
public int age;
public Person(int id, String name) {
this.id = id;
//this.name = name;
}
public String toString() {
return "Person: " + id
//+ ",name:" + name
+ ",age:" + age;
}
}
Person DeserialPerson: 1234,age:0
【答案】序列化,反序列化正常,B端字段少于A端,A端多的字段值丢失(被B端忽略)。
情况四:假设两处serialVersionUID一致,如果B端增加一个字段,A端不变,会是什么情况呢?
验证过程如下:
先执行SerialTest,然后在实体类Person增加一个字段age,如下所示,再执行测试类DeserialTest.
package com.sf.code.serial;
import java.io.Serializable;
public class Person implements Serializable {
private static final long serialVersionUID = 1234567890L;
public int id;
public String name;
public int age;
public Person(int id, String name) {
this.id = id;
this.name = name;
}
/*public Person(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}*/
public String toString() {
return "Person: " + id
+ ",name:" + name
+ ",age:" + age;
}
}
结果:Person DeserialPerson: 1234,name:wang,age:0
说明序列化,反序列化正常,B端新增加的int字段被赋予了默认值0。
最后通过下面的图片,总结一下上面的几种情况。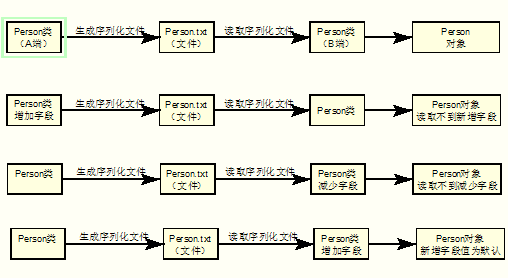
静态变量序列化
情境:查看清单 2 的代码。
清单 2. 静态变量序列化问题代码
public class Test implements Serializable {
private static final long serialVersionUID = 1L;
public static int staticVar = 5;
public static void main(String[] args) {
try {
//初始时staticVar为5
ObjectOutputStream out = new ObjectOutputStream(
new FileOutputStream("result.obj"));
out.writeObject(new Test());
out.close();
//序列化后修改为10
Test.staticVar = 10;
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"result.obj"));
Test t = (Test) oin.readObject();
oin.close();
//再读取,通过t.staticVar打印新的值
System.out.println(t.staticVar);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
清单 2 中的 main 方法,将对象序列化后,修改静态变量的数值,再将序列化对象读取出来,然后通过读取出来的对象获得静态变量的数值并打印出来。依照清单 2,这个 System.out.println(t.staticVar) 语句输出的是 10 还是 5 呢?
最后的输出是 10,对于无法理解的读者认为,打印的 staticVar 是从读取的对象里获得的,应该是保存时的状态才对。之所以打印 10 的原因在于序列化时,并不保存静态变量,这其实比较容易理解,序列化保存的是对象的状态,静态变量属于类的状态,因此 序列化并不保存静态变量。
父类的序列化与 Transient 关键字
情境:一个子类实现了 Serializable 接口,它的父类都没有实现 Serializable 接口,序列化该子类对象,然后反序列化后输出父类定义的某变量的数值,该变量数值与序列化时的数值不同。
解决:要想将父类对象也序列化,就需要让父类也实现Serializable 接口。如果父类不实现的话的,就 需要有默认的无参的构造函数。在父类没有实现 Serializable 接口时,虚拟机是不会序列化父对象的,而一个 Java 对象的构造必须先有父对象,才有子对象,反序列化也不例外。所以反序列化时,为了构造父对象,只能调用父类的无参构造函数作为默认的父对象。因此当我们取父对象的变量值时,它的值是调用父类无参构造函数后的值。如果你考虑到这种序列化的情况,在父类无参构造函数中对变量进行初始化,否则的话,父类变量值都是默认声明的值,如 int 型的默认是 0,string 型的默认是 null。
Transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
特性使用案例
我们熟悉使用 Transient 关键字可以使得字段不被序列化,那么还有别的方法吗?根据父类对象序列化的规则,我们可以将不需要被序列化的字段抽取出来放到父类中,子类实现 Serializable 接口,父类不实现,根据父类序列化规则,父类的字段数据将不被序列化,形成类图如图 2 所示。
图 2. 案例程序类图

上图中可以看出,attr1、attr2、attr3、attr5 都不会被序列化,放在父类中的好处在于当有另外一个 Child 类时,attr1、attr2、attr3 依然不会被序列化,不用重复抒写 transient,代码简洁。
static final 修饰的serialVersionUID如何被写入到序列化文件中的,看下面的源码:
序列化写入时的ObjectStreamClass.java中,
void writeNonProxy(ObjectOutputStream out) throws IOException {
out.writeUTF(name);
out.writeLong(getSerialVersionUID());
byte flags = 0;
...
public long getSerialVersionUID() {
// REMIND: synchronize instead of relying on volatile?
if (suid == null) {
suid = AccessController.doPrivileged(
new PrivilegedAction<Long>() {
public Long run() {
return computeDefaultSUID(cl);
}
}
);
}
return suid.longValue();
}


