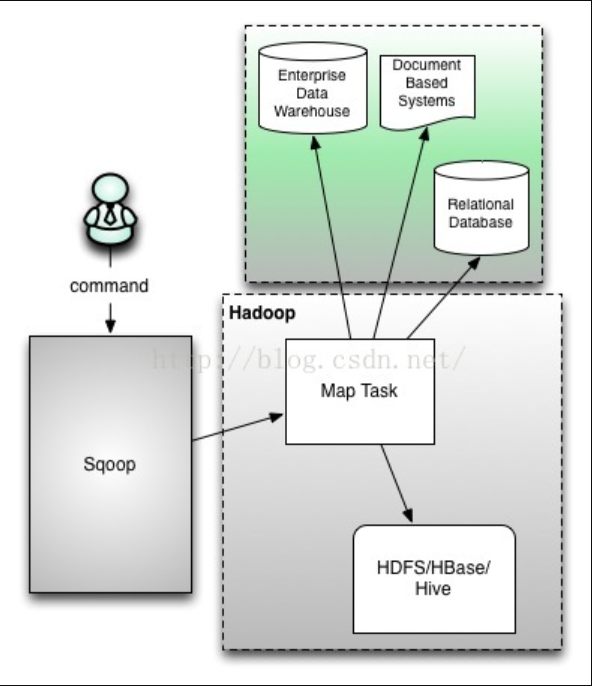
一. Sqoop介绍
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如:MySQL、Oracle、Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。对于某些NoSQL数据库它也提供了连接器。Sqoop,类似于其他ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时确保类型安全的数据处理。Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
本文版本说明
hadoop版本 :hadoop-2.7.2
hive版本:hive-2.1.0
sqoop版本:sqoop-1.4.6
二. Mysql 数据导入到 Hive
1). 将mysql的people_access_log表导入到hive表web.people_access_log,并且hive中的表不存在。
mysql中表people_access_log数据为:
1,15110101010,1577003281739,'112.168.1.2','https://www.baidu.com'
2,15110101011,1577003281749,'112.16.1.23','https://www.baidu.com'
3,15110101012,1577003281759,'193.168.1.2','https://www.taobao.com'
4,15110101013,1577003281769,'112.18.1.2','https://www.baidu.com'
5,15110101014,1577003281779,'112.168.10.2','https://www.baidu.com'
6,15110101015,1577003281789,'11.168.1.2','https://www.taobao.com'
将mysql数据导入hive的命令为:
sqoop import
--connect jdbc:mysql://master1.hadoop:3306/test
--username root
--password 123456
--table people_access_log
-m 1
--hive-import
--create-hive-table
--fields-terminated-by ' '
--hive-table web.people_access_log
该命令会启用一个mapreduce任务,将mysql数据导入到hive表,并且指定了hive表的分隔符为 ,如果不指定则为默认分隔符^A(ctrl+A)。
参数说明
| 参数 | 说明 |
|---|---|
--connect |
mysql的连接信息 |
--username |
mysql的用户名 |
--password |
mysql的密码 |
--table |
被导入的mysql源表名 |
-m |
并行导入启用的map任务数量,与--num-mapper含义一样 |
--hive-import |
插入数据到hive当中,使用hive默认的分隔符,可以使用--fields-terminated-by参数来指定分隔符。 |
-- hive-table |
hive当中的表名 |
2). 也可以通过--query条件查询Mysql数据,将查询结果导入到Hive
sqoop import
--connect jdbc:mysql://master1.hadoop:3306/test
--username root
--password 123456
--query 'select * from people_access_log where $CONDITIONS and url = "https://www.baidu.com"'
--target-dir /user/hive/warehouse/web/people_access_log
--delete-target-dir
--fields-terminated-by ' '
-m 1
| 参数 | 说明 |
|---|---|
--query |
后接查询语句,条件查询需要$CONDITIONS and连接查询条件,这里的$表示转义$,必须有. |
--delete-target-dir |
如果目标hive表目录存在,则删除,相当于overwrite. |
三. Hive数据导入到Mysql
还是使用上面的hive表web.people_access_log,将其导入到mysql中的people_access_log_out表中.
sqoop export
--connect jdbc:mysql://master1.hadoop:3306/test
--username root
--password 123456
--table people_access_log_out
--input-fields-terminated-by ' '
--export-dir /user/hive/warehouse/web.db/people_access_log
--num-mappers 1
注意:mysql表people_access_log_out需要提前建好,否则报错:ErrorException: Table 'test.people_access_log_out' doesn't exist。如果有id自增列,hive表也需要有,hive表与mysql表字段必须完全相同。
create table people_access_log_out like people_access_log;
执行完一个mr任务后,成功导入到mysql表people_access_log_out中.
四. mysql数据增量导入hive
实际中mysql数据会不断增加,这时候需要用sqoop将数据增量导入hive,然后进行海量数据分析统计。增量数据导入分两种,一是基于递增列的增量数据导入(Append方式)。二是基于时间列的增量数据导入(LastModified方式)。有几个核心参数:
–check-column:用来指定一些列,这些列在增量导入时用来检查这些数据是否作为增量数据进行导入,和关系型数据库中的自增字段及时间戳类似.注意:这些被指定的列的类型不能使任意字符类型,如char、varchar等类型都是不可以的,同时–check-column可以去指定多个列–incremental:用来指定增量导入的模式,两种模式分别为Append和Lastmodified–last-value:指定上一次导入中检查列指定字段最大值
1. 基于递增列Append导入
接着前面的日志表,里面每行有一个唯一标识自增列ID,在关系型数据库中以主键形式存在。之前已经将id在0~6之间的编号的订单导入到Hadoop中了(这里为HDFS),现在一段时间后我们需要将近期产生的新的订 单数据导入Hadoop中(这里为HDFS),以供后续数仓进行分析。此时我们只需要指定–incremental 参数为append,–last-value参数为6即可。表示只从id大于6后即7开始导入。
1). 创建hive表
首先我们需要创建一张与mysql结构相同的hive表,假设指定字段分隔符为 ,后面导入数据时候分隔符也需要保持一致。
2). 创建job
增量导入肯定是多次进行的,可能每隔一个小时、一天等,所以需要创建计划任务,然后定时执行即可。我们都知道hive的数据是存在hdfs上面的,我们创建sqoop job的时候需要指定hive的数据表对应的hdfs目录,然后定时执行这个job即可。
当前mysql中数据,hive中数据与mysql一样也有6条:
id |
user_id |
access_time |
ip |
url |
|---|---|---|---|---|
| 1 | 15110101010 | 1577003281739 | 112.168.1.2 | https://www.baidu.com |
| 2 | 15110101011 | 1577003281749 | 112.16.1.23 | https://www.baidu.com |
| 3 | 15110101012 | 1577003281759 | 193.168.1.2 | https://www.taobao.com |
| 4 | 15110101013 | 1577003281769 | 112.18.1.2 | https://www.baidu.com |
| 5 | 15110101014 | 1577003281779 | 112.168.10.2 | https://www.baidu.com |
| 6 | 15110101015 | 1577003281789 | 11.168.1.2 | https://www.taobao.com |
增量导入有几个参数,保证下次同步的时候可以接着上次继续同步.
sqoop job --create mysql2hive_job -- import
--connect jdbc:mysql://master1.hadoop:3306/test
--username root
--password 123456
--table people_access_log
--target-dir /user/hive/warehouse/web.db/people_access_log
--check-column id
--incremental append
--fields-terminated-by ' '
--last-value 6
-m 1
这里通过sqoop job --create job_name命令创建了一个名为mysql2hive_job的sqoop job。
3). 执行job
创建好了job,后面只需要定时周期执行这个提前定义好的job即可。我们先往mysql里面插入2条数据。
INSERT INTO `people_access_log` (`id`,`user_id`,`access_time`,`ip`,`url`) VALUES
(7,15110101016,1577003281790,'112.168.1.3','https://www.qq.com'),
(8,15110101017,1577003281791,'112.1.1.3','https://www.microsoft.com');
这样mysql里面就会多了2条数据。此时hive里面只有id为1 ~ 6的数据,执行同步job使用以下命令。
sqoop job -exec mysql2hive_job
执行完成后,发现刚才mysql新加入的id为7 ~ 8的两条数据已经同步到hive。
hive> select * from web.people_access_log;
OK
1 15110101010 1577003281739 112.168.1.2 https://www.baidu.com
2 15110101011 1577003281749 112.16.1.23 https://www.baidu.com
3 15110101012 1577003281759 193.168.1.2 https://www.taobao.com
4 15110101013 1577003281769 112.18.1.2 https://www.baidu.com
5 15110101014 1577003281779 112.168.10.2 https://www.baidu.com
6 15110101015 1577003281789 11.168.1.2 https://www.taobao.com
7 15110101016 1577003281790 112.168.1.3 https://www.qq.com
8 15110101017 1577003281791 112.1.1.3 https://www.microsoft.com
由于实际场景中,mysql表中的数据,比如订单表等,通常是一致有数据进入的,这时候只需要将sqoop job -exec mysql2hive_job这个命令定时(比如说10分钟频率)执行一次,就能将数据10分钟同步一次到hive数据仓库。
2. Lastmodified 导入实战
append适合业务系统库,一般业务系统表会通过自增ID作为主键标识唯一性。Lastmodified适合ETL的数据根据时间戳字段导入,表示只导入比这个时间戳大,即比这个时间晚的数据。
1). 新建一张表
在mysql中新建一张表people_access_log2,并且初始化几条数据:
CREATE TABLE `people_access_log2` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`user_id` bigint(20) unsigned NOT NULL COMMENT '用户id',
`access_time` timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`ip` varchar(15) NOT NULL COMMENT '访客ip',
`url` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
插入数据:
insert into people_access_log2(id,user_id, ip, url) values(1,15110101010,'112.168.1.200','https://www.baidu.com');
insert into people_access_log2(id,user_id, ip, url) values(2,15110101011,'112.16.1.2','https://www.baidu.com');
insert into people_access_log2(id,user_id, ip, url) values(3,15110101012,'112.168.1.2','https://www.taobao.com');
insert into people_access_log2(id,user_id, ip, url) values(4,15110101013,'112.168.10.2','https://www.baidu.com');
insert into people_access_log2(id,user_id, ip, url) values(5,15110101014,'112.168.1.2','https://www.jd.com');
insert into people_access_log2(id,user_id, ip, url) values(6,15110101015,'112.168.12.4','https://www.qq.com');
mysql里面的数据就是这样:
| id | user_id | access_time | ip | url |
|---|---|---|---|---|
1 |
15110101010 |
2019-12-28 16:23:10 |
112.168.1.200 |
https://www.baidu.com |
2 |
15110101011 |
2019-12-28 16:23:33 |
112.16.1.2 |
https://www.baidu.com |
3 |
15110101012 |
2019-12-28 16:23:41 |
112.168.1.2 |
https://www.taobao.com |
4 |
15110101013 |
2019-12-28 16:23:46 |
112.168.10.2 |
https://www.baidu.com |
5 |
15110101014 |
2019-12-28 16:23:52 |
112.168.1.2 |
https://www.jd.com |
6 |
15110101015 |
2019-12-28 16:23:56 |
112.168.12.4 |
https://www.qq. |
2). 初始化hive表:
初始化hive数据,将mysql里面的6条数据导入hive中,并且可以自动帮助我们创建对应hive表,何乐而不为,否则我们需要自己手动创建,完成初始化工作。
sqoop import
--connect jdbc:mysql://master1.hadoop:3306/test
--username root
--password 123456
--table people_access_log2
--hive-import
--create-hive-table
--fields-terminated-by ','
--hive-table web.people_access_log2
可以看到执行该命令后,启动了二一个mapreduce任务,这样6条数据就进入hive表web.people_access_log2了:
hive> select * from web.people_access_log2;
OK
1 15110101010 2019-12-28 16:23:10.0 112.168.1.200 https://www.baidu.com
2 15110101011 2019-12-28 16:23:33.0 112.16.1.2 https://www.baidu.com
3 15110101012 2019-12-28 16:23:41.0 112.168.1.2 https://www.taobao.com
4 15110101013 2019-12-28 16:23:46.0 112.168.10.2 https://www.baidu.com
5 15110101014 2019-12-28 16:23:52.0 112.168.1.2 https://www.jd.com
6 15110101015 2019-12-28 16:23:56.0 112.168.12.4 https://www.qq.com
Time taken: 0.326 seconds, Fetched: 6 row(s)
3). 增量导入数据:
我们再次插入一条数据进入mysql的people_access_log2表:
insert into people_access_log2(id,user_id, ip, url) values(7,15110101016,'112.168.12.45','https://www.qq.com');
此时,mysql表里面已经有7条数据了,我们使用incremental的方式进行增量的导入到hive:
sqoop import
--connect jdbc:mysql://master1.hadoop:3306/test
--username root
--password 123456
--table people_access_log2
--hive-import
--hive-table people_access_log2
-m 1
--check-column access_time
--incremental lastmodified
--last-value "2019-12-28 16:23:56"
2019-12-28 16:23:56就是第6条数据的时间,这里需要指定。报错了:
19/12/28 16:17:25 ERROR tool.ImportTool: Error during import: --merge-key or --append is required when using --incremental lastmodified and the output directory exists.
注意:可以看到--merge-key or --append is required when using --incremental lastmodified意思是,这种基于时间导入模式,需要指定--merge-key或者--append参数,表示根据时间戳导入,数据是直接在末尾追加(append)还是合并(merge),这里使用merge方式,根据id合并:
sqoop import
--connect jdbc:mysql://master1.hadoop:3306/test
--username root
--password 123456
--table people_access_log2
--hive-import
--hive-table web.people_access_log2
--check-column access_time
--incremental lastmodified
--last-value "2019-12-28 16:23:56"
--fields-terminated-by ','
--merge-key id
执行该命令后,与直接导入不同,该命令启动了2个mapreduce任务,这样就把数据增量merge导入hive表了.
hive> select * from web.people_access_log2 order by id;
OK
1 15110101010 2019-12-28 16:23:10.0 112.168.1.200 https://www.baidu.com
2 15110101011 2019-12-28 16:23:33.0 112.16.1.2 https://www.baidu.com
3 15110101012 2019-12-28 16:23:41.0 112.168.1.2 https://www.taobao.com
4 15110101013 2019-12-28 16:23:46.0 112.168.10.2 https://www.baidu.com
5 15110101014 2019-12-28 16:23:52.0 112.168.1.2 https://www.jd.com
6 15110101015 2019-12-28 16:23:56.0 112.168.12.4 https://www.qq.com
6 15110101015 2019-12-28 16:23:56.0 112.168.12.4 https://www.qq.com
7 15110101016 2019-12-28 16:28:24.0 112.168.12.45 https://www.qq.com
Time taken: 0.241 seconds, Fetched: 8 row(s)
可以看到id=6的数据,有2条,它的时间刚好是--last-value指定的时间,则会导入大于等于--last-value指定时间的数据,这点需要注意。