1. hashcode
1.1 hashcode来源
1.2 hashcode的形式
1.3 hashcode目的
1.4 hashcode规则
1.5 hashcode作用体现
1.6 重写hashcode方法
2. equals方法
2.1 equals来源
2.2 equals目的
2.3 equals性质
2.4 重写equals与hashcode方法
2.5 equals与hashcode的联合使用
3 包装类的hashCode()实现
4.包装类的equals()的实现
1. hashcode
1.1 hashcode来源
hashcode源于java.lang.Object类:
/**
* Returns a hash code value for the object. This method is
* supported for the benefit of hash tables such as those provided by
* {@link java.util.HashMap}.
* <p>
* The general contract of {@code hashCode} is:
* <ul>
* <li>Whenever it is invoked on the same object more than once during
* an execution of a Java application, the {@code hashCode} method
* must consistently return the same integer, provided no information
* used in {@code equals} comparisons on the object is modified.
* This integer need not remain consistent from one execution of an
* application to another execution of the same application.
* <li>If two objects are equal according to the {@code equals(Object)}
* method, then calling the {@code hashCode} method on each of
* the two objects must produce the same integer result.
* <li>It is <em>not</em> required that if two objects are unequal
* according to the {@link java.lang.Object#equals(java.lang.Object)}
* method, then calling the {@code hashCode} method on each of the
* two objects must produce distinct integer results. However, the
* programmer should be aware that producing distinct integer results
* for unequal objects may improve the performance of hash tables.
* </ul>
* <p>
* As much as is reasonably practical, the hashCode method defined by
* class {@code Object} does return distinct integers for distinct
* objects. (This is typically implemented by converting the internal
* address of the object into an integer, but this implementation
* technique is not required by the
* Java™ programming language.)
*
* @return a hash code value for this object.
* @see java.lang.Object#equals(java.lang.Object)
* @see java.lang.System#identityHashCode
*/
public native int hashCode();
本地实现,其与地址的关系讨论见:https://www.cnblogs.com/datamining-bio/p/10089331.htm
1.2 hashcode的形式
从以上源码可以看出hashcode为int类型,为什么不是long类型(范围大,重复率低)https://stackoverflow.com/questions/4166195/why-objecthashcode-returns-int-instead-of-long
stackoverflow上的解释为:

数组的最大长度为Integer.MAX_VALUE,使用hashcode()的目的是往数组中插入数据时快速得到一个位置。如果该位置大于数组长度,就插不进去。
我们看HashMap的源码:
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
HashMap设置的最大容量是int类型,即使使用范围更大的数表示hashcode,再插入时做模运算,插入位置的重复率是不变的,所以使用long或者int效果是一样的。
另外,因为是int类型,所以hashcode是会出现负值的。(例如,https://blog.csdn.net/chanllenge/article/details/8567325)
1.3 hashcode目的
Object中对hashCode()函数的说明表示hashcode是为了hash tables(HashMap)等容器设计的。当添加和查找某元素时,直接根据该元素的hashcode值计算一个存储位置(散列值,将对象离散开),这样就可以在查找数据的时候根据这个值缩小查找范围,将其复杂度下降接近O(1)(因为有碰撞,所以达不到O(1))。为了避免多个不同的对象都定位到相同的存储位置,使用的hashcode就要大一些,尽可能让hashcode不同,此时不同对象就可以直接存储在不同的位置,当hashcode相同时,在定位的存储位置增加链表存放后续对象。这样做大大减少了插入和查找时长,但是需要大量的空间。
为什么定义在Object类中?因为放在容器(table、map)中的都为对象,所有类都继承Object类,对象在放进容器时使用hashcode,定义在Object类中避免了额外继承其他类或者实现hashcode所在接口,减轻编程负担,减少不必要的错误。其次,使用容器时,将元素直接使用Object表示,方便编程和理解。
1.4 hashcode规则
① 在执行java程序时,equals()中使用的信息不变,则同一个对象多次调用hashCode()函数,返回的Integer必须一致。
② 同一java应用程序的一次运行和另一次运行中,不需要保持hashCode()返回值相同。即同一对象在一次运行中hashcode不变,多次运行时可以不同。
③ 两个对象调用equals()方法相等时,调用hashcode()方法也必须返回相同的integer。
④ 两个对象调用equals()方法不相等时,不要求它们的hashcode也必须不同。然而,两个对象equals()不相等时,让它们的hashcode也不等可以提高hash table的性能。
⑤ 在Object类中,hashCode()方法对不同对象返回不同的integer值。(典型实现是将对象存储地址转为integer)
⑥ 当equals()方法重写时,hashcode()方法也要重写,保证相等的对象hashcode必须相等。
1.5 hashcode作用体现
我们分析HashMap的put(key, value)方法:涉及红黑树,稍后
见https://www.cnblogs.com/aoguren/p/5559067.html
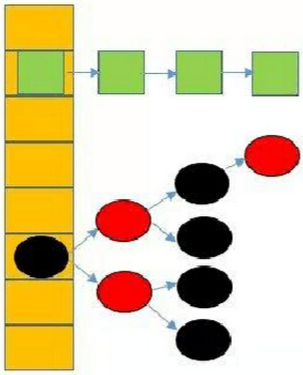
在JDK1.8之前,HashMap采用桶+链表实现,本质就是采用数组+单向链表组合型的数据结构。它之所以有相当快的查询速度主要是因为它是通过计算散列码来决定存储的位置。HashMap通过key的hashCode来计算hash值,不同的hash值就存在数组中不同的位置,当多个元素的hash值相同时(所谓hash冲突),就采用链表将它们串联起来(链表解决冲突),放置在该hash值所对应的数组位置上。

在JDK1.8中,HashMap的存储结构已经发生变化,它采用数组+链表+红黑树这种组合型数据结构。当hash值发生冲突时,会采用链表或者红黑树解决冲突。当同一hash值的结点数小于8时,则采用链表,否则,采用红黑树。这个重大改变,主要是提高查询速度。
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
如果HashMap之前已经存在键为key的<key, value>对,则将之前的value替换为新的vale。
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
返回key原来关联的value,如果返回null,表示原来map里没有关联key的value,或者理解为key关联的是null
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
1.6 重写hashcode方法
见2.4 重写hashcode与equals方法。
2. equals方法
2.1 equals来源
同样的,equals()方法也是在java.lang.Object类中定义的,源码如下:
/**
* Indicates whether some other object is "equal to" this one.
* <p>
* The {@code equals} method implements an equivalence relation
* on non-null object references:
* <ul>
* <li>It is <i>reflexive</i>: for any non-null reference value
* {@code x}, {@code x.equals(x)} should return
* {@code true}.
* <li>It is <i>symmetric</i>: for any non-null reference values
* {@code x} and {@code y}, {@code x.equals(y)}
* should return {@code true} if and only if
* {@code y.equals(x)} returns {@code true}.
* <li>It is <i>transitive</i>: for any non-null reference values
* {@code x}, {@code y}, and {@code z}, if
* {@code x.equals(y)} returns {@code true} and
* {@code y.equals(z)} returns {@code true}, then
* {@code x.equals(z)} should return {@code true}.
* <li>It is <i>consistent</i>: for any non-null reference values
* {@code x} and {@code y}, multiple invocations of
* {@code x.equals(y)} consistently return {@code true}
* or consistently return {@code false}, provided no
* information used in {@code equals} comparisons on the
* objects is modified.
* <li>For any non-null reference value {@code x},
* {@code x.equals(null)} should return {@code false}.
* </ul>
* <p>
* The {@code equals} method for class {@code Object} implements
* the most discriminating possible equivalence relation on objects;
* that is, for any non-null reference values {@code x} and
* {@code y}, this method returns {@code true} if and only
* if {@code x} and {@code y} refer to the same object
* ({@code x == y} has the value {@code true}).
* <p>
* Note that it is generally necessary to override the {@code hashCode}
* method whenever this method is overridden, so as to maintain the
* general contract for the {@code hashCode} method, which states
* that equal objects must have equal hash codes.
*
* @param obj the reference object with which to compare.
* @return {@code true} if this object is the same as the obj
* argument; {@code false} otherwise.
* @see #hashCode()
* @see java.util.HashMap
*/
public boolean equals(Object obj) {
return (this == obj);
}
2.2 equals目的
Indicates whether some other object is "equal to" this one.用于比较其他对象是否与此对象相等。
2.3 equals性质
① 自反性:对于任何非空对象x,有x.equals(x)返回true;
② 对称性:非空对象x,y,当x.equals(y)=true时,y.equals(x)=true;
③ 传递性:任何非空对象x,y,z,如果x.equals(y)=true且y.equals(z)=true,则x.equals(z)=true;
④ 一致性:任何非空对象x,y,若没有修改equals方法中使用的信息,则多次调用x.equals(y)返回值不变;
⑤ 对于任何非空对象x,x.equals(null)返回false。
对于Object类实现的equals()方法,实现了对象上最具辨别力的等价关系,即,对于任何非空引用值x,y,此方法当且仅当x和y引用同一对象时返回true,即x==y时值为true。
2.4 重写equals与hashcode方法
(1)为什么要重写equals()方法?
|
https://java-min.iteye.com/blog/1416727 覆盖equals时需要遵守的通用约定:
|
在某些实际应用中,需要根据需求决定是否重写equals()。若不重写equals(),则为Object类中的实现方式,即this == obj;对于基本类型而言,值相等即“==”,而使用equals方法的是对象,objA.equals(objB)为true时objA==objB,两个对象地址相同。这样的话,直接使用“==”判断不就OK了?
使用最多的是只要两个对象的属性值相等,则认为是这两个对象是相等的。
另外,重写equals()时,需要遵守equals()的五个性质(2.3)。
(2)为什么重写equals()也要重写hashCode()?
Object类声明:重写equals()时也要重写hashCode(),是为了保证相等的两个对象的hashcode值一样。即,hashcode不等,则equals一定不等;hashcode相等,equals不一定相等。
(3)重写equals()
通常而言,正确地重写equals方法应该满足以下条件:
|
①自反性:对任意x, x.equals(x)一定返回true; ②对称性:对任意x和y,如果y.equals(x)返回true,则x.equals(y)返回true; ③传递性:对任意x,y,z,如果有x.equals(y)返回true,y.equals(z)返回true,则x.equals(z)一定返回true; ④一致性:对任意x和y,如果对象中用于等价比较的信息没有改变,那么无论调用x.equals(y)多少次,返回的结果应该保持一致,要么一直为true,要么一直为false; ⑤对任何不是null的x, x.equals(null)一定返回false。 |
|
注意:由于instanceof运算符的特殊性,当前面对象是后面类的实例或其子类的实例都将返回true,所以判断两个对象是否为同一个类的实例,用instanceof是有问题的。改为:if(obj != null && bj.getClass() == Person.class),用到了反射基础 |
|
equals(obj){ if(obj == this) return true; if(obj != null && obj.getClass() == Person.class){ // 按要求判断 } } |
(4)重写hashCode()
重写hashCode()方法的基本规则:
|
①当两个对象通过equals--true,这两个对象的hashCode--true ②对象中用作equals比较标准的属性,都应该用来计算hashCode值 |
重写hashCode()的方式:
|
①对象内每个有意义的属性f(即每个用作equals()比较标准的属性)计算出一个int类型的hashCode值。(参考JDK包装类的源码) ②用上一步计算出来多个hashCode组合计算出一个hashCode值返回。为避免直接相加产生相等的情况,可以通过为每个属性乘以任意一个质数后再相加:return f1.hashCode() * 17 + (int)f2 * 13; |
2.5 equals与hashcode的联合使用
hashcode相等只能保证两个对象在一个HASH表里的同一条HASH链上,继而通过equals方法才能确定是不是同一对象,如果结果为true, 则认为是同一对象在插入,否则认为是不同对象继续插入。(https://blog.csdn.net/pozmckaoddb/article/details/47447429)
3 包装类的hashCode()实现
https://blog.csdn.net/u012448083/article/details/67092017
| Boolean |
value ? 1231 : 1237; |
使用质数可以利用质数的性质:其和其他数的公约数只有1,则可以很好的避免多个对象散列到相同的桶里。 Why large primes. Wouldn't 2 and 3 do? Do collisions matter? Booleans just have two different values anyway? |
|
Byte |
(int)value; |
1字节 |
|
Short |
(int)value; |
2字节 |
|
Character |
(int)value; |
2字节 |
|
Integer |
value; |
4字节 |
|
Long |
(int)(value ^ (value >>> 32)); |
由于最后的hashCode的类型是int, 而int只有32位,所以64位的Long值,要砍掉一半。为了不失去一半的信息,这个expression的意思是,会值的高32位和低32位的值进行exclusive OR的结果,这样就保证结果均会受前后32位的影响,不会丢失信息。如果直接把Long转成int, 那就会丢掉高32位的信息,这就不是好的implementation |
|
Float |
floatToIntBits(value); |
把float 转成bits, 大概是把32位的float 直接当成int输出来,不管那些位置信息,例如本来第31位是符号位,第23到30位代表的是指数,但转成int值后,这些值代表的意义都不存在了,仅仅作为普通的int数位。 |
|
Double |
long bits = doubleToLongBits(value); return (int)(bits ^ (bits >>> 32)); |
第一段code与 floatToIntBits(value) 一样; 第二段code是与Long.hashCode()一样 |
|
String |
for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h;
|
选择数字31是因为它是一个奇质数,如果选择一个偶数会在乘法运算中产生溢出,导致数值信息丢失,因为乘二相当于移位运算。选择质数的优势并不是特别的明显,但这是一个传统。同时,数字31有一个很好的特性,即乘法运算可以被移位和减法运算取代,来获取更好的性能:31 * i == (i << 5) - i,现代的 Java 虚拟机可以自动的完成这个优化。
正如 Goodrich 和 Tamassia 指出的那样,如果你对超过 50,000 个英文单词(由两个不同版本的 Unix 字典合并而成)进行 hash code 运算,并使用常数 31, 33, 37, 39 和 41 作为乘子,每个常数算出的哈希值冲突数都小于7个,所以在上面几个常数中,常数 31 被 Java 实现所选用也就不足为奇了。 |

4.包装类的equals()的实现
|
Float |
return (obj instanceof Float) && (floatToIntBits(((Float)obj).value) == floatToIntBits(value)); 比较的是转为int型的二进制(32bits) |
|
Double |
return (obj instanceof Double) && (doubleToLongBits(((Double)obj).value) == doubleToLongBits(value)); 转化为long对应的二进制表示(64bits) |
|
String |
while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } 比较字符数组的每一位 |