1. 基本类型
2. 基本类型之间的类型转换
(1)自动类型转换
(2)强制类型转换
(3)运算时类型提升
(4)类型转换中的符号扩展及“多重转型”
3. 基本类型到对应包装类
(1)包装类
(2)自动装箱与拆箱
(3)缓存
4.基本类型和String之间的转换
(1)基本类型 -> String
(2)String -> 基本类型
5.instanceof
1. 基本类型

|
类型 |
占用存储空间 |
表示数的范围 |
|
byte |
1字节 |
-128~127 |
|
short |
2字节 |
-215~215-1(-32768~32767) |
|
int (integer) |
4字节 |
-231~231-1(-2147483648~2147483647)约21亿 |
|
long |
8字节 |
-263~263-1 |
|
float |
4字节 |
-3.403E38~3.403E38 |
|
double |
8字节 |
-1.798E308~1.798E308 |
逻辑型:boolean(1位,默认初始值为false)【虽然用1位就可以表示,但是Java中至少使用1个字节保存,原因见下文】
Note:与其他高级语言不同,java中的布尔值和数字之间不能来回转换,即false和true不对应于任何零或非零的整数值。
byte类型:
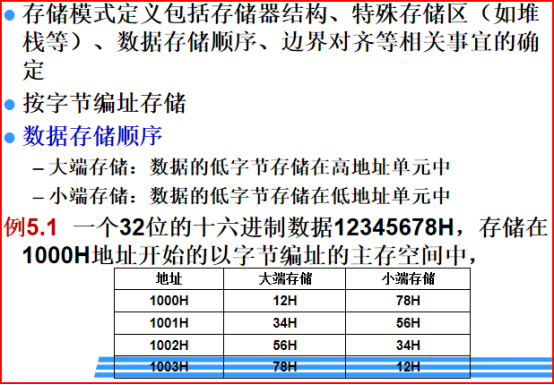
由于不同的机器对于多字节数据的存储方式不同,可能是从低字节向高字节存储,也可能是从高字节向低字节存储,这样,在分析网络协议或文件格式时,为了解决不同机器上的字节存储顺序问题,用byte类型来表示数据是比较合适的。而通常情况下,由于其表示的数据范围很小,容易造成溢出,因此要尽量少使用。
浮点型:double 和 float
不要使用浮点数判断相等,可用于大小判断。
Float:小数点后7位,double:16位
浮点数默认类型为double,默认初始值为0.0。浮点数在运算过程中不会因溢出而导致异常处理。如若出现下溢,则结果为0.0,如果上溢,则结果为正或负无穷大。非法数表示为NaN。
正无穷大(infinity):正数除以0(整数除以0会报错:15/0)
负无穷大(-infinity):负数除以0
NaN:0.0除以0.0 或 对一个负数开方
所有正无穷大数值都相等,所有负无穷大数值都相等,NaN不与任何数值相等,甚至和NaN都不相等。
2. 基本类型之间的类型转换
(1)自动类型转换:A->B,当B的表示范围大于等于A时(原值保留)

int, char, shout, byte也可互转,只要表示的数值没有超过数值范围。
为什么int转float会有精度丢失,而转double不会?
|
java 的浮点类型都依据 IEEE 754 标准。IEEE 754 定义了32 位和 64 位双精度两种浮点二进制小数标准。 对于32 位浮点数float用 第1 位表示数字的符号,用第2至9位来表示指数,用 最后23 位来表示尾数,即小数部分。 对于64 位双精度浮点数,用 第1 位表示数字的符号,用 11 位表示指数,52 位表示尾数。 即如果int的值在23位内表示,则float可以精确表示,超过23位则float的23位不够表示,但是double拥有52位可以精确表示整数,完全包含了32位的int。 |
(2)强制类型转换:B->A,A的表示范围比B小(会丢失信息)

(3)运算时类型提升,避免计算中值溢出(类型转换放第一个)

为什么两个short类型相加会自动提升为int?
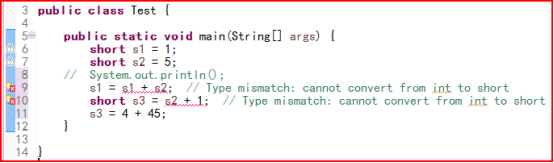
s1 + s2系统会自动将它们提升为int再运算,结果为int类型,赋给short类型,编译报错;s3 = s2 + 1也是同样的原因;s3 = 4 + 45,系统选计算4+45=50,也就是变为s3 = 50,50在short表示的范围内,自动转型为short。但是为什么java在两个short型运算时自动提升为int,即使它们没有超过表示范围?
Stack Overflow:

使用较小类型运算没有性能优势,消除较小的类型使得字节码更简单,并且使得具有未来扩展空间的完整指令集仍然适合单个字节中的操作码。因此,较小的类型通常被视为Java设计中的二等公民,在各个步骤转换为int,因为这简化了一些事情。
Why does the Java API use int instead of short or byte?
https://stackoverflow.com/questions/27122610/why-does-the-java-api-use-int-instead-of-short-or-byte

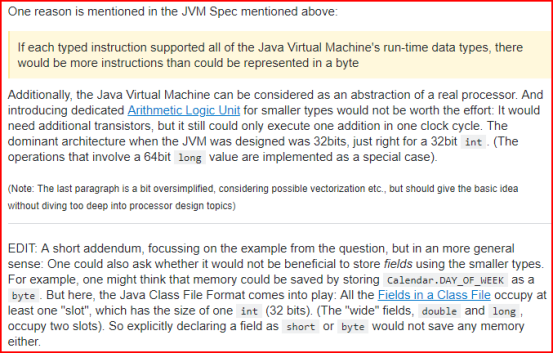
答案可能只与Java虚拟机指令集有关。较小的类型(byte,short)基本上只用于数组。
If each typed instruction supported all of the Java Virtual Machine's run-time data types, there would be more instructions than could be represented in a byte。
为较小的类型引入专用的算术逻辑单元不值得付出努力:它需要额外的晶体管,但它仍然只能在一个时钟周期内执行一次加法。 JVM设计时的主流架构是32位,适合32位int。
(4)类型转换中的符号扩展及“多重转型”
https://blog.csdn.net/qq_38962004/article/details/80025619
3. 基本类型到对应包装类
(1)包装类
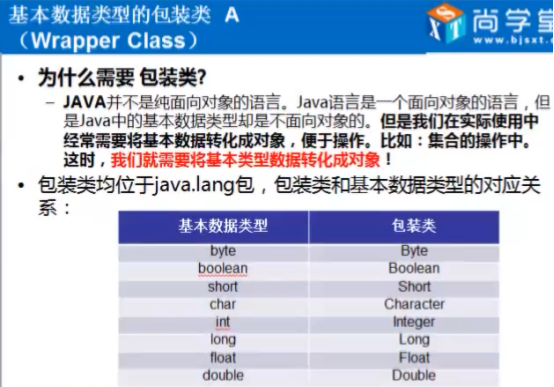
java保留基本类型:开发运行效率高

(2)自动装箱与拆箱

基本数据类型有一些约束:所有引用类型变量都继承了Object类,都可当成Object类型变量使用。但基本数据类型变量就不可以,如果有个方法需要Object类型的参数,但实际需要的值却是2、3等数值,这可能就比较难以处理,为了解决8个基本数据类型的变量不能当做Object类型变量使用的问题,java提供了包装类的概念。
JDK1.5之前:
基本类型 ---new Integer(125)----> 包装类
包装类 ---对象.xxxValue()方法------> 基本类型
自动装箱(JDK5.0之后):
把基本数据类型变量包装成包装类实例是通过对应包装类的构造器来实现的。除Character之外,其他均可通过传入一个字符串参数来构建包装类对象。
包装类还可实现将基本类型和字符串之间的转换:int = Integer.parseInt(intStr),String类里也提供了多个重载valueOf()方法,将基本类型转为字符串。
(3)缓存
-128~127之间的数,当做基本数据类型处理,提高效率
public static void main(String[] args) { Integer i1 = 59; Integer i2 = 59; System.out.println(i1 == i2); // true System.out.println(i1.equals(i2)); // true System.out.println("=================="); Integer i3 = -129; Integer i4 = -129; System.out.println(i3 == i4); // false System.out.println(i3.equals(i4)); // true }
public class TestNuke {
public static void main(String[] args) {
Integer i01 = 59;
int i02 = 59;
Integer i03 = Integer.valueOf(59);
Integer i04 = new Integer(59);
System.out.println(i01 == i02); // true
System.out.println(i01 == i03); // true
System.out.println(i01 == i04); // false
System.out.println(i02 == i03); // true
System.out.println(i02 == i04); // true
System.out.println(i03 == i04); // false
System.out.println(i01.hashCode()); // 59
System.out.println(i03.hashCode()); // 59
System.out.println(i04.hashCode()); // 59
}
}
|
JVM中一个字节以下的整型数据会在JVM启动的时候加载进内存,除非用new Integer()显式的创建对象,否则都是同一个对象 Integer i01 = 59;会调用 Integer 的 valueOf 方法:
这个方法就是返回一个 Integer 对象,只是在返回之前,先作了一个判断,判断当前 i 的值是否在 [-128,127] 区别,且 IntegerCache 中是否存在此对象,如果存在,则直接返回引用,否则,创建一个新的对象。 在这里的话,因为程序初次运行,没有 59 ,所以,直接创建了一个新的对象。 int i02=59 ,这是一个基本类型,存储在栈中。 Integer i03 =Integer.valueOf(59); 因为 IntegerCache 中已经存在此对象,所以,直接返回引用 Integer i04 = new Integer(59) ;直接创建一个新的对象。 System. out .println(i01== i02); i01 是 Integer 对象, i02 是 int ,这里比较的不是地址,而是值。 Integer 会自动拆箱成 int ,然后进行值的比较。所以,为真。 System. out .println(i01== i03); 因为 i03 返回的是 i01 的引用,所以,为真。 System. out .println(i03==i04); 因为 i04 是重新创建的对象,所以 i03,i04 是指向不同的对象,因此比较结果为假。 System. out .println(i02== i04); 因为 i02 是基本类型,所以此时 i04 会自动拆箱,进行值比较,所以,结果为真。 IntegerCache.cache是在Integer类加载时就初始化好的,在[-128,127]范围内的valueOf(i),直接去数组中拿对象,而不是首次初始化时才创建。而new Integer(x),不管x的大小,都是新建对象,不去找cache。 |
|
基本数据类型和包装类的比较。 |
| 注意:
1. 因为Integer这个包装类比较特殊,内部有一个数组cache数组,保存了-128到127的值,也就是Integer i = n,只要n在-128到127之间,都是直接从cache数组中获取,不会再创建新的对象。 |

4.基本类型和String之间的转换
https://www.cnblogs.com/rrttp/p/7922202.html(char---String)
(1)基本类型 -> String
|
(2)String -> 基本类型
|
① 包装类的parseXxx():int a = Integer.parseInt(“45”); ② 包装类的valueOf():double d = Double.valueOf(“4.54”); ③ String-->char:String.charAt(index)(返回值为char) String.toCharArray()(返回值为char[]) |
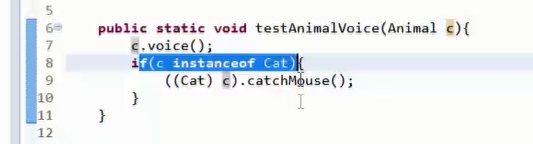
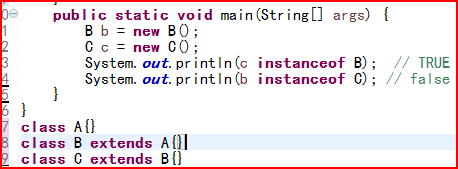
5.instanceof
Instanceof运算符前面操作数的编译时类型要么与后面的类相同,要么是后面类的父类,否则会引起编译错误。(true:同类或父类)