我们常常把String类型的字符串作为HashMap的key,为什么要这样做呢?
因为String是不可变的,一旦初始化就不再改变了,如果被修改将会是一个新对象。
@Test
public void testString() {
String s = "Java";
logger.info(s);
System.out.println(s.hashCode());
s = "code";
logger.info(s);
System.out.println(s.hashCode());
}
//输出结果:
/* 15:12:22.453[main] INFO base.AnalString -Java
2301506
15:12:42.794[main] INFO base.AnalString -code
3059181*/
从输出结果来看是s的值已经被改变了,但是在debug的过程中我们可以发现,s的引用指向一个新的String这个String就是“code”.

这时我们从源码中一探究竟。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
- String被final修饰,说明String类绝不可能被继承,也就说任何对String的操作方法,都不会被继承重写。
- String中保存的数据是一个被final修饰的字符数组value。也就是说value一旦被赋值成功后,内存地址是无法改变的。并且这个字符数组的访问权限是private,外部绝对访问不到,String也没有开放出对value进行赋值的方法,所以说value一旦产生,内存地址根本无法修改。
因为String具有不可变性,所以String的大多数操作方法,都会返回新的String。
编码问题
来写一个demo
@Test
public void testEncoding() throws UnsupportedEncodingException {
String str = "你好,大涛";
byte[] bytes = str.getBytes("ISO-8859-1");
//bytes 数组转换成字符串
String s2 = new String(bytes);
logger.info(s2);
//结果:?????
//再纠正一下
String s3 = new String(bytes,"ISO-8859-1");
logger.info(s3);
//?????
//咋还不对,全部改为UTF-8编码
byte[] strBytes = str.getBytes("UTF-8");
String s4 = new String(strBytes,"UTF-8");
System.out.println(s4);
//结果:你好,大涛
//唉,舒服了
}
这里说一下为啥ISO-8859-1编码方式不行呢?主要是因为他不支持中文编码,导致中文会显示乱码。唯一的解决方法是换成UTF-8编码。
常用的字符串操作方法
substring()字符串截取
substring有两个方法。
String substring(int beginIndex)String substring(int beginIndex,int endIndex)
这两内部实现基本一样,只有一个参数的那个,直接从开始的下标截取到字符串长度-1.
public String substring(int beginIndex, int endIndex) {
//逻辑判断截取字符串有没有下标越界
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
//如果开始下标是0并且结束下标是长度-1,直接返回原先字符串;否则再new一个字符串,value是字符数组
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
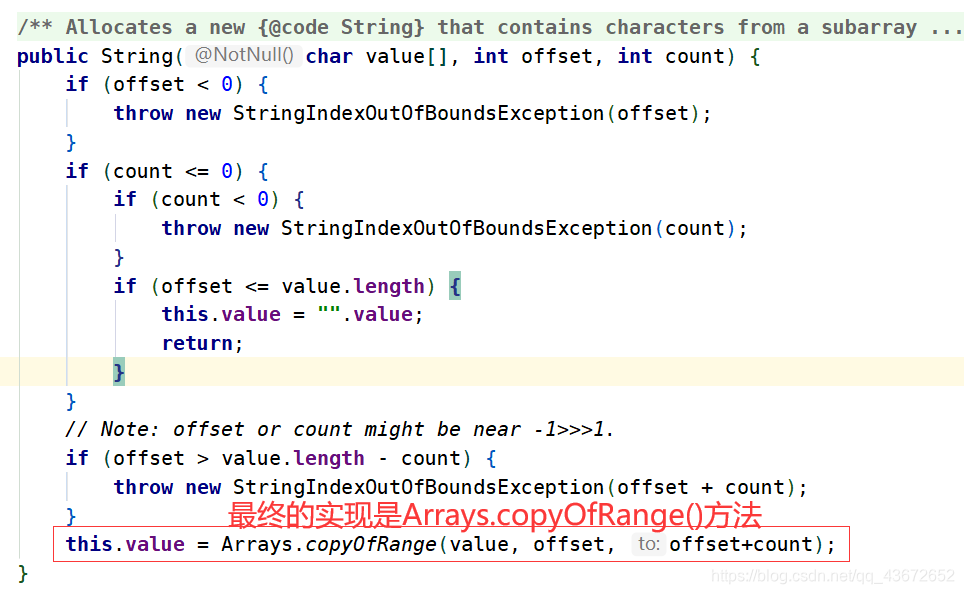
new String(value, beginIndex, subLen); 来看看这个构造方法是如何实现的。
字符串的相等判断
判断方式有两种,一种是equals方法,另一种是忽略大小写判断相等,equalsIgnoreCase。
来看一下equals的源代码。
public boolean equals(Object anObject) {
//如果对象的内存地址相等直接返回true
if (this == anObject) {
return true;
}
//再判断她得是String类型,不是的话,返回false
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
//如果字符串长度不等,返回false
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
//循环依次判断每个字符是否相等,如果有字符不等,返回false
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
//循环结束,长度相等,类型相等,每个字符页相等,返回true
return true;
}
}
return false;
}
字符串替换
replace(char oldChar, char newChar)方法,是较为常用的字符串替换方法,传入一个旧的字符,再传入一个新的字符,接下来看看源码中是怎样实现的?
public String replace(char oldChar, char newChar) {
//开始先判断新的字符和旧的字符是不是一样的,如果一样的话就不用替换,直接返回原先的字符串
if (oldChar != newChar) {
//字符串长度
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
//val字符数组
//找到第一个将要替换的字符,break,跳出循环
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
if (i < len) {
//这里又创建了一个字符数组用来装替换后的新字符串
char buf[] = new char[len];
//先将原先不用替换的字符,直接赋值给新数组
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
//接下来从第一个将要替换的字符位置开始往后遍历
while (i < len) {
char c = val[i];
//如果是我们想要替换的字符就赋值成新的值,否则还是原先的值
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
//最终返回新的字符串
return new String(buf, true);
}
}
return this;
}
以上是博主对String源码的一些理解,如果以上有理解有误的地方还请大家多多指出,共同学习!