Vnodes简短历史
Vnodes又叫Virtual Nodes。是Cassandra在1.2版本里引入的功能,已经在生产环境中使用了近8年了。从2.0版本开始,因为默认配置里num_tokens一般会设成256,所以如果你没有修改过默认参数,那很有可能你一直都在使用这个功能。
当初引入vnodes主要是为了改善增加节点时的灵活性。在pre-1.2时代(也就是没有vnodes功能的时候),每次集群扩容都必须要让节点数翻倍,比如3个节点扩容到6个节点,下次需要扩容的时候再增加到12个节点。这是因为每个节点都只拥有一个token范围,增加新节点的时候就是把每个token范围一分为二,让每个新节点都负责一半的token范围。但是,如果要保证整个集群的token范围是均匀分布的,每次新增加的节点数需要跟已有的节点数一致。这样每次翻倍的扩容方式显然对运维和资源计划造成了很大的挑战。
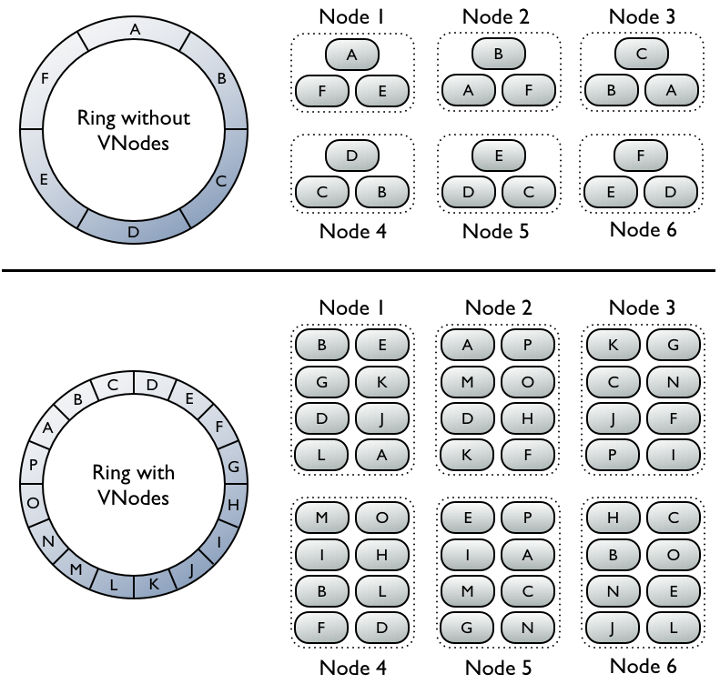
有了vnodes以后,默认情况下每个物理节点会负责256个token范围,增加一个新的节点只需要从每个已有节点的256个token范围中取出若干个,合起来凑成256个新token范围分配给新来的节点就好了。整个集群的token范围分布还是均匀的。
Vnodes功能在1.2版推出以后,受到了广大生产环境Cassandra运维人员的欢迎,所以在2.0版里,vnodes功能被默认启用,而且这个num_tokens参数默认的被配置成了256。
Vnodes带来的问题
可是,随着越来越多的Cassandra集群开始在生产环境里使用vnodes,它的一些不尽如人意的地方逐渐开始体现出来。
最大的一个问题,体现在运行nodetool repair的时候:因为repair是按照节点的token范围来安排一个个的小任务,以进行副本之间的比较和修复工作;一个节点拥有的token范围的数量越多,这样的小任务就越多;当一个节点拥有了256个token范围,并且存储了几百GB数据的时候,每个keyspace的repair小任务加起来所花的时间动辄就会达到几小时甚至数天;生产环境中一般会有几个keyspace,再加上nodetool repair -pr需要10天之内在所有的节点上都运行一轮,这会对运维带来比较大的困难。
另外,当一个节点拥有了256个token范围时,增加新节点的bootstrap过程也会带来多得多的SSTable数量,需要消耗大量的CPU才能把这些大量的小SSTable消化掉。
比较棘手的是,这些问题并不是简单的在配置中降低num_tokens取值就可以解决的。把num_tokens设置成一个更小的值比如16,当然会大大改善repair和bootstrap,但是这样面临着两个主要的挑战:
- Cassandra 1.2原有的vnodes算法设计一般假设每个节点会有数百个token范围,使用的是随机重新分配的算法,token范围数量多的时候没问题,但是token范围数量降低到十几个的时候,很容易出现数据不均匀分配的情况(如下图所示),而且节点增加的越多,这种不均匀的现象会越严重;
- 一个数据中心的vnodes数量在数据中心初始化的时候就确定了,将来想要改的话,只能启用新的数据中心迁移数据。
Datacenter: us-east-1 ===================== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 172.1*.3*.1* 1.55 TiB 16 4.1% f683ab0e-a687-400f-80fb-28f7b4471ffc b UN 172.1*.3*.1** 1.05 TiB 16 2.9% 2097cd01-4161-44a9-a944-d5445e8c5e02 c UN 172.1*.3*.2* 720.26 GiB 16 3.0% e6593e3a-bb1c-499c-a99b-73781cfcd076 c UN 172.1*.3*.2* 1.3 TiB 16 4.0% 99670a7c-a55f-4a43-8e4b-a3cccc71f08f a UN 172.1*.3*.1** 961.67 GiB 16 3.2% a4bb1648-3582-4f05-a1e6-3125e9c3c46c b UN 172.1*.3*.1** 1.29 TiB 16 4.4% 890e98d3-d88d-4d8c-89b4-7e9444bb69be a UN 172.1*.3*.2* 1.42 TiB 16 4.0% 3f2817da-9dc5-4122-8977-5d3d93669b4e c UN 172.1*.3*.1** 710.53 GiB 16 4.9% 72405162-f121-46d4-a220-a1fd2db868e8 b UN 172.1*.3*.3* 2.38 TiB 16 7.1% f15c768c-0175-4646-bc68-7b20a74d7f0d b UN 172.1*.3*.1** 2.68 TiB 16 7.3% 2f444803-7787-474a-9ed9-8555147023d3 c UN 172.1*.3*.1** 1.59 TiB 16 5.2% bd838966-23e2-44b2-986c-729ede679604 c UN 172.1*.3*.5* 808.48 GiB 16 4.3% 1fe83c82-1fb2-4570-9aae-7805370f24b0 b
新版本是怎样解决问题的
针对上面提到的第一个挑战,Cassandra 3.0里启用了新的token分配算法,并且增加了一个新的参数allocate_tokens_for_keyspace,这个贪心算法虽然不能完全避免token范围热点的情况出现,但是它的最大好处是,在集群中继续增加节点的话,token范围的热点会越来越少,数据分配会越来越均匀。
Cassandra 4.0在此基础之上又做了更多的改进,3.0里的参数allocate_tokens_for_keyspace将被allocate_tokens_for_local_replication_factor取代。这样配置的工作更加简单,因为不再需要在初始化一个数据中心的时候提供一个keyspace的名字。
有了这样算法的加持,社区也逐渐开始建议所有用户在新建数据库的时候,把num_tokens参数直接改成一个比256小得多的取值。最新的讨论可以看这个JIRA和这个邮件列表的讨论。社区现在达成的共识是在4.0版本中把默认的num_tokens设置成16,并且默认启用新的token分配算法。如果4.0 release测试过程不再发现新的问题,在4.0正式版发布以后,所有运行新版本的集群将会是每节点拥有16个token范围,以兼顾运维操作的高效,和数据分配的均匀。