项目问题:有一张日志表,插入和查询为主,每天记录数据为200多万,大小为2G-4G之间。一开始开发人员使用delete语句手动删除,保留7天数据,经常造成阻塞和性能瓶颈。但是如果不删除数据随着表越来越大,查询效率很低,由于应用有超时设置,经常出现timeout。
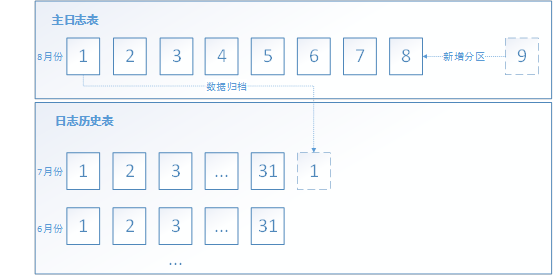
优化思路:采用分区表来实现日志表的自动随时间窗口滚动,即每天新增明天分区,并将7天前数据归档至日志表。以8月份为例子,当日日期为8号,流程如下图:
具体步骤:
1.建立32个文件组,32个数据库文件,对应于每月31天,每月对31个文件进行复用
-- 创建文件组 USE [master] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY00] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY01] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY02] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY03] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY04] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY05] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY06] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY07] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY08] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY09] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY10] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY11] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY12] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY13] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY14] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY15] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY16] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY17] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY18] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY19] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY20] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY21] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY22] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY23] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY24] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY25] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY26] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY27] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY28] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY29] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY30] GO ALTER DATABASE TClientLog ADD FILEGROUP [FGDAY31] GO -- 创建和文件组相对应的文件,由于只有3个盘 USE [master] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY01', FILENAME = N'E:partfileFDAY01.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY01] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY02', FILENAME = N'E:partfileFDAY02.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY02] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY03', FILENAME = N'E:partfileFDAY03.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY03] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY04', FILENAME = N'E:partfileFDAY04.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY04] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY05', FILENAME = N'E:partfileFDAY05.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY05] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY06', FILENAME = N'E:partfileFDAY06.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY06] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY07', FILENAME = N'E:partfileFDAY07.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY07] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY08', FILENAME = N'E:partfileFDAY08.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY08] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY09', FILENAME = N'E:partfileFDAY09.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY09] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY10', FILENAME = N'E:partfileFDAY10.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY10] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY11', FILENAME = N'E:partfileFDAY11.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY11] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY12', FILENAME = N'E:partfileFDAY12.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY12] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY13', FILENAME = N'E:partfileFDAY13.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY13] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY14', FILENAME = N'E:partfileFDAY14.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY14] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY15', FILENAME = N'E:partfileFDAY15.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY15] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY16', FILENAME = N'E:partfileFDAY16.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY16] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY17', FILENAME = N'E:partfileFDAY17.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY17] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY18', FILENAME = N'E:partfileFDAY18.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY18] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY19', FILENAME = N'E:partfileFDAY19.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY19] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY20', FILENAME = N'E:partfileFDAY20.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY20] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY21', FILENAME = N'E:partfileFDAY21.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY21] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY22', FILENAME = N'E:partfileFDAY22.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY22] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY23', FILENAME = N'E:partfileFDAY23.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY23] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY24', FILENAME = N'E:partfileFDAY24.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY24] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY25', FILENAME = N'E:partfileFDAY25.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY25] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY26', FILENAME = N'E:partfileFDAY26.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY26] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY27', FILENAME = N'E:partfileFDAY27.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY27] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY28', FILENAME = N'E:partfileFDAY28.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY28] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY29', FILENAME = N'E:partfileFDAY29.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY29] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY30', FILENAME = N'E:partfileFDAY30.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY30] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY31', FILENAME = N'E:partfileFDAY31.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY31] GO ALTER DATABASE TClientLog ADD FILE ( NAME = N'FDAY00', FILENAME = N'E:partfileFDAY00.ndf' , SIZE = 100MB , FILEGROWTH = 500MB ) TO FILEGROUP [FGDAY00] GO
注意:为什么是32个文件组,32个数据库文件。这和分区函数和分区方案有关系,比如分区函数以DATETIME为分区类型,建立20150801和20150802两个边界,那么就会产生如下3个分区。那相应的分区方案中就要有3个文件组和其对应。
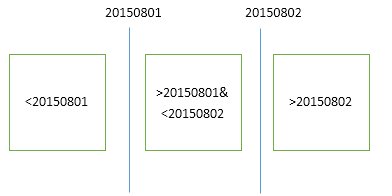
在建立分区函数时,边界的归属。请看上图,以20150801为例,如果是right,边界归属于右边,所分的两个区间:数据<20150801和20150801<=数据<20150802;如果是left,边界归属左边,所分区间为:数据<=20150801和20150801<数据<=20150802;总结一句话,关键字是那边,那么边界值就归属于所分区域的那边。
对于是否有必要将每个文件建立到不同的磁盘上,我这里没有建立,因为应用中的查询一般不会跨分区,都查近几个小时的,所以没有必要将文件建立到不同的磁盘文件中。
如果对于分区表的基础概念还不清楚,请看SQL Server表分区。
2.建立相应的分区函数和分区方案
USE TClientLog; CREATE PARTITION FUNCTION part_day_rang_func(DATETIME) AS RANGE right FOR VALUES ( '2015-08-01 00:00:00', '2015-08-02 00:00:00', '2015-08-03 00:00:00', '2015-08-04 00:00:00', '2015-08-05 00:00:00', '2015-08-06 00:00:00', '2015-08-07 00:00:00', '2015-08-08 00:00:00', '2015-08-09 00:00:00', '2015-08-10 00:00:00', '2015-08-11 00:00:00', '2015-08-12 00:00:00', '2015-08-13 00:00:00', '2015-08-14 00:00:00', '2015-08-15 00:00:00', '2015-08-16 00:00:00', '2015-08-17 00:00:00', '2015-08-18 00:00:00', '2015-08-19 00:00:00', '2015-08-20 00:00:00', '2015-08-21 00:00:00', '2015-08-22 00:00:00', '2015-08-23 00:00:00', '2015-08-24 00:00:00', '2015-08-25 00:00:00', '2015-08-26 00:00:00', '2015-08-27 00:00:00', '2015-08-28 00:00:00', '2015-08-29 00:00:00', '2015-08-30 00:00:00', '2015-08-31 00:00:00'); CREATE PARTITION SCHEME part_day_rang_scheme AS PARTITION part_day_rang_func TO ( FGDAY00, FGDAY01, FGDAY02, FGDAY03, FGDAY04, FGDAY05, FGDAY06, FGDAY07, FGDAY08, FGDAY09, FGDAY10, FGDAY11, FGDAY12, FGDAY13, FGDAY14, FGDAY15, FGDAY16, FGDAY17, FGDAY18, FGDAY19, FGDAY20, FGDAY21, FGDAY22, FGDAY23, FGDAY24, FGDAY25, FGDAY26, FGDAY27, FGDAY28, FGDAY29, FGDAY30, FGDAY31 );
注意:分区方案指定的是文件组不是文件,FGDAY00文件组对应的分区是'分区数据<20150801',FGDAY31对应的分区是'分区数据>=20150831'。
3.建立主日志分区表和历史日志分区表,以表内的时间字段为分区键,索引采用与表分区对齐方式,分区自动化管理脚本如下:
CREATE TABLE [dbo].[ClientLog]( [SynID] [nchar](38) NOT NULL, [ParkingId] [int] NOT NULL, [ParkingBoxId] [int] NOT NULL, [Message] [varchar](max) NULL, [OccurTime] [datetime] NOT NULL, [UpdateTime] [datetime] NOT NULL, [ErrorLevel] [int] NOT NULL, [State] [int] NULL, [IsSend] [int] NULL, CONSTRAINT [PK_ClientLog] PRIMARY KEY NONCLUSTERED ( [SynID] ASC, [OccurTime] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [part_day_rang_scheme]([OccurTime]) ) ON [part_day_rang_scheme]([OccurTime]) GO CREATE NONCLUSTERED INDEX [idx_clientlog_otime] ON [dbo].[ClientLog] ( [ParkingId] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [part_day_rang_scheme]([OccurTime]) GO
注意:主键中必须包含分区键;分区索引必须使用和表一致的分区方案,即索引必须与表对齐,才能进行分区切换;
4.主日志分区表保留7天,每天增加后数第7天的分区,前数第7天的数据进行归档,与日志历史表进行分区交换,流程图参考优化思路的图。
-- ============================================= -- Author: zhangkun -- Create date: <2015.08.07> -- Description: <根据日志的滑动窗口业务,进行自动化分区管理> -- ============================================= -- 1.修改分区方案和分区函数 -- 2.进行分区交换,将归档数据放入历史表 alter PROCEDURE [dbo].[sp_PartitionManage] @td DATETIME AS BEGIN DECLARE @flag CHAR(1) --标志位 IF @td IS NULL --如果@td为null,则默认当天 SET @td = GETDATE() -- 1.修改分区方案和分区函数,当天新增后数第七天的日期 BEGIN DECLARE @td_next7 DATETIME DECLARE @day_next7 VARCHAR(2) DECLARE @sql NVARCHAR(MAX) --动态sql字符串 SET @td_next7 = DATEADD(DAY, 7, @td) --7天后日期 SET @day_next7 = CASE WHEN LEN(DATENAME(DAY, @td_next7)) = 1 THEN '0' + DATENAME(DAY, @td_next7) ELSE DATENAME(DAY, @td_next7) END; --7天后是当月第几天SELECT @flag = COUNT(1) FROM sys.partition_functions a , sys.partition_range_values b WHERE a.name = 'part_day_rang_func' AND a.function_id = b.function_id AND CONVERT(DATETIME, b.value) = CONVERT(VARCHAR(10), @td_next7, 120) + ' 00:00:00.000'; PRINT @flag; IF ( @flag != '1' ) BEGIN SET @sql = 'alter partition scheme part_day_rang_scheme next used FGDAY' + @day_next7 + '; alter partition function part_day_rang_func() split range(''' + CONVERT(VARCHAR(10), @td_next7, 120) + ''')' EXEC sp_executesql @sql; END END -- 2.进行分区交换,将归档数据放入历史表 DECLARE @td_before7 DATETIME DECLARE @day_before7 VARCHAR(2) SET @td_before7 = DATEADD(DAY, -7, @td) --7天前日期 SET @day_before7 = CASE WHEN LEN(DATENAME(DAY, @td_before7)) = 1 THEN '0' + DATENAME(DAY, @td_before7) ELSE DATENAME(DAY, @td_before7) END; --7天前是当月第几天DECLARE @partition_num INT SELECT @partition_num = boundary_id + 1 FROM sys.partition_functions a , sys.partition_range_values b WHERE a.name = 'part_day_rang_func' AND a.function_id = b.function_id AND CONVERT(DATETIME, b.value) = CONVERT(VARCHAR(10), @td_before7, 120) + ' 00:00:00.000'; PRINT @partition_num; ALTER TABLE [dbo].[ClientLog_new] SWITCH PARTITION @partition_num TO [dbo].[ClientLog_newhis] PARTITION @partition_num ALTER TABLE [dbo].[ClientLog] SWITCH PARTITION @partition_num TO [dbo].[ClientLoghis] PARTITION @partition_num END;
配置job:
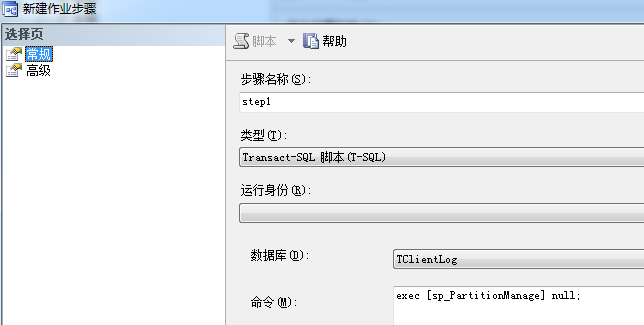


注意:我这里会增加后7天的分区,如果只建立明天的分区,我怕有一天报错的话,就会报找不到分区插入的错误。此外对该作业进行监控,每天发生错误的话,就手工重跑。
对于通知的配置,需要先配置邮箱服务器。
采用分区表和分区表的交换是因为如果采用普通表的话限制有很多:普通表和分区必须在同一个文件组内;普通表和分区表表结构(字段、索引等)必须一致;普通表必须在分区键所在字段上加和要交换分区限制条件一样的约束。采用分区表的好处是可以屏蔽这些限制,直接用分区表对应的分区直接交换就行。而且对于历史表想清空数据的话,可以新增一个空的临时表,直接进行分区交换,相当方便。
5、对历史表设置保留天数,进行数据清理
历史表的数据清理,准备运行观察一下决定保留的天数,确定后可以配置到自动化管理脚本中。思路就是之前说的建立一个临时的空分区表,每天与历史表要删除的分区进行交换。
之所以要建立临时空表,是因为交换分区的目标表必须是空表。目前还没发现一个可以直接drop分区的方案。
总结:1、利用这种方式处理分区表的好处就是全程都是DDL操作,避免了产生阻塞和日志,且速度很快,几秒内就能完成切换。
2、对于大数据量,且存在时间滑动的问题,都可以采用此方案,根据业务进行具体实施,比如订单表,拆分成最近3个月和1年内的业务。
3、对于分区键的选取很重要,查询的时候一定要能用到该字段,并指定具体时间段,这样才会产生分区裁剪;对于全表扫描,分区可能还会降低性能
4、其实sqlserver的分区表对于插入的性能是受影响的,没有普通表速度快,这点需要考虑在内
关于sqlserver分区表,请参考如下链接: