Centos7 version
- 7.9
- kernel 5.4.138-1.el7.elrepo.x86_64
kubernetes version
- v1.21.3
- 1.k8s下载coredns镜像失败->aliyun 无coredns:v1.8.0
- 2.k8s初始化失败->无aliyun coredns镜像
- 3.k8s 从节点加入集群失败
- 4.kubectl 执行命令报“The connection to the server localhost:8080 was refused”
- 5.主节点初始化后,coredns的状态是pending
- 6.主节点初始化后,kubectl get cs status为unhealthy
- 7.安装网络插件flannel - k8s version v1.21.x
- 8.主节点初始化后,flannel状态为Init:ImagePullBackOff
- 9.从节点 NotReady 状态
- 更多问题
1.k8s下载coredns镜像失败->aliyun 无coredns:v1.8.0
在安装kubeadm/kubectl/kubelet后,通过kubeadm config images list --kubernets-version=v1.21.3可查看对应镜像版本:
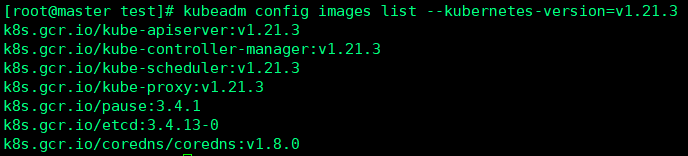
通过docker pull registry.aliyuncs.com/google_containers/${kube_image}:v1.21.3下载镜像都很顺利(除coredns外),通过在docker hub查找一番,竟然看到coredns/coredns:1.8.0版本的镜像,用docker pull coredns/coredns:1.8.0拉取镜像后,再通过docker tag命令 打成k8s.gcr.io/coredns/coredns:v1.8.0镜像。
问题-解决
在阿里云的google仓库中,没有coredns/coredns:v1.8.0的镜像,这是比较坑的,因为新版本的coredns竟然改名了,脚本运行多遍发现失败,最终在docker hub中找到对应版本的coredns。
2.k8s初始化失败->无aliyun coredns镜像
在k8s init时一直失败,提示找不到对应的aliyun的coredns镜像,以下是初始化命令:
version=v1.21.3
master_ip=192.168.181.xxx
POD_NETWORK=10.244.0.0
kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version ${version} --apiserver-advertise-address ${master_ip} --pod-network-cidr=${POD_NETWORK}/16 --token-ttl 0
失败提示:

注意到此处:registry.aliyuncs.com/google_containers/coredns:v1.8.0
在pull镜像时,是没有打aliyun的coredns的镜像的,没有就用现成的镜像再打个aliyun的:
docker tag k8s.gcr.io/coredns/coredns:v1.8.0 registry.aliyuncs.com/google_containers/coredns:v1.8.0
再次执行初始化命令,看到:
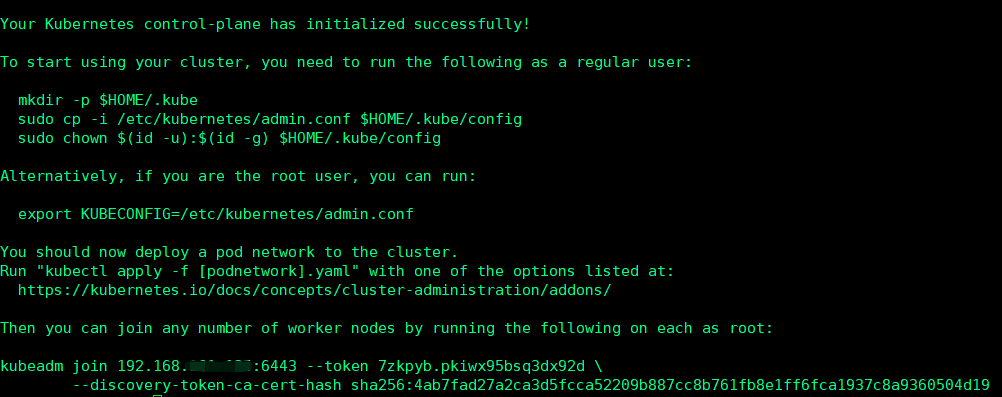
初始化成功,可以进入下一步操作。
3.k8s 从节点加入集群失败
从节点加入集群命令,主节点执行:
kubeadm token create --print-join-command
> kubeadm join 192.168.181.135:6443 --token 2ihfvx.pzoqbw5fwf7ioxwb --discovery-token-ca-cert-hash sha256:4ab7fad27a2ca3d5fcca52209b887cc8b761fb8e1ff6fca1937c8a9360504d19
当从节点机器装完docker、配置好k8s的环境(Firewall、selinux、swap、内核参数)、装好kubeadm/kubectl/kubelet、docker load k8s_images后,在主节点添加136的从节点如下(实际应该在从节点加入):
kubeadm join 192.168.181.136:6443 --token 2ihfvx.pzoqbw5fwf7ioxwb --discovery-token-ca-cert-hash sha256:4ab7fad27a2ca3d5fcca52209b887cc8b761fb8e1ff6fca1937c8a9360504d19
# 以下是报错问题
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR DirAvailable--etc-kubernetes-manifests]: /etc/kubernetes/manifests is not empty
[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
在从节点使用kubeadm join命令加入集群环境问题如下:

原因1:集群时间未同步造成
date # 各节点都验证后,发现确实有这个问题,各节点执行下面命令,同步时间,最好加个cron定时任务,定期获取时间同步
yun install -y ntpdate
ntpdate cn.pool.ntp.org
crontab -e
---
*/20 * * * * /usr/bin/ntpdate -u cn.pool.ntp.org
原因2:token失效
# 主节点上,查看token list
kubeadm token list
# 主节点上,新建token
kubeadm token create
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //' # 同一集群,结果相同
# 从节点上,再次加入集群 192.168.181.135:6443 一定是主节点6443集群
kubeadm join 192.168.181.135:6443 --token mct6a0.vzwbybzryu70tb17 --discovery-token-ca-cert-hash sha256:4ab7fad27a2ca3d5fcca52209b887cc8b761fb8e1ff6fca1937c8a9360504d19

原因3:防火墙没关闭
# 这种情况一般不会,因为之前在设置k8s环境时,我们通常一同关闭防火墙
# 从节点,检查主机端口开放情况
nv -vz 192.168.181.135 6443
# 主节点从节点,如果连接拒绝,检查防火墙
firewall-cmd --state
# 主节点从节点,关闭防火墙
systemctl stop firewalld.service
# 主节点从节点,关闭开机启动
systemctl disable firewalld.service
# 从节点,再次加入集群
kubeadm join xxx
4.kubectl 执行命令报“The connection to the server localhost:8080 was refused”
kubectl get pods

主节点admin.conf -> 从节点
主节点:
#复制admin.conf,请在主节点服务器上执行此命令
scp /etc/kubernetes/admin.conf node1:/etc/kubernetes/admin.conf
scp /etc/kubernetes/admin.conf node2:/etc/kubernetes/admin.conf
从节点:
#设置kubeconfig文件
export KUBECONFIG=/etc/kubernetes/admin.conf
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile

5.主节点初始化后,coredns的状态是pending
kubectl get pods --all-namespaces
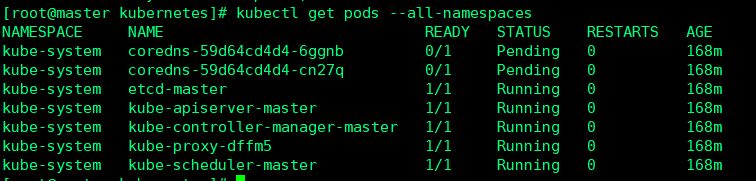
根据图中结果可知,coredns一直处于pendding状态,
原因1:master上的flannel镜像拉取失败,导致获取不到解析的IP
解决方法:
参考解决flannel镜像拉取部分
原因2:没有本地解析,所以coredns才是pending
解决方法:编辑/etc/hosts文件,加入集群各个节点ip hostname
6.主节点初始化后,kubectl get cs status为unhealthy
[root@master kubernetes]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"}
编辑/etc/kubernetes/manifests下的kube-controller-manager.yaml & kube-scheduler.yaml,找到port=0那行,注释即可,随后再次查看自动变为healthy状态:
[root@master manifests]# vi kube-controller-manager.yaml
[root@master manifests]# vi kube-scheduler.yaml
[root@master manifests]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
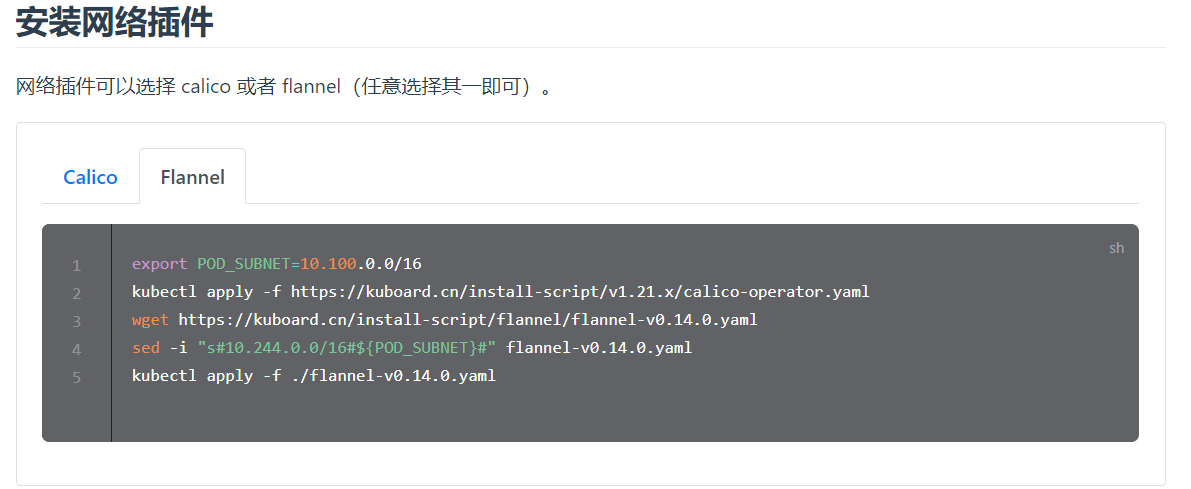
7.安装网络插件flannel - k8s version v1.21.x
export POD_SUBNET=10.100.0.0/16
kubectl apply -f https://kuboard.cn/install-script/v1.21.x/calico-operator.yaml
wget https://kuboard.cn/install-script/flannel/flannel-v0.14.0.yaml
sed -i "s#10.244.0.0/16#${POD_SUBNET}#" flannel-v0.14.0.yaml
kubectl apply -f ./flannel-v0.14.0.yaml
8.主节点初始化后,flannel状态为Init:ImagePullBackOff
- https://blog.csdn.net/qq_43442524/article/details/105298366
- https://hub.docker.com/u/xwjh ---> k8s v1.21.3全套镜像
使用上一问题flannel后,
[root@master ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-59d64cd4d4-6ggnb 0/1 Pending 0 3h49m
coredns-59d64cd4d4-cn27q 0/1 Pending 0 3h49m
etcd-master 1/1 Running 0 3h49m
kube-apiserver-master 1/1 Running 0 3h49m
kube-controller-manager-master 1/1 Running 0 40m
kube-flannel-ds-68xtw 0/1 Init:ImagePullBackOff 0 21m
kube-proxy-dffm5 1/1 Running 0 3h49m
kube-scheduler-master 1/1 Running 0 39m
flannel状态为Init:ImagePullBackOff
原因
查看flannel-v0.14.0.yaml文件时发现quay.io/coreos/flannel:v0.14.0 line169/183
quay.io网站目前国内无法访问
下载flannel:v0.14.0导入到docker中
主节点操作
docker pull xwjh/flannel:v0.14.0 # 感谢这位docker hub 的兄弟,解决国内无法下载flannel镜像问题, https://hub.docker.com/u/xwjh
docker tag xwjh/flannel:v0.14.0 quay.io/coreos/flannel:v0.14.0
docker rmi xwjh/flannel:v0.14.0
kubectl get pod -n kube-system
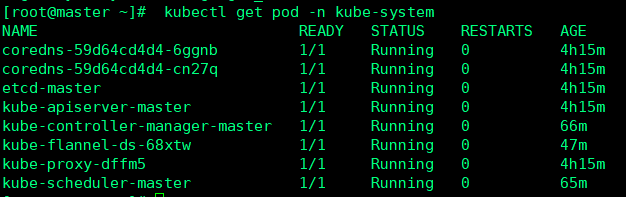
9.从节点 NotReady 状态
参考:
当从节点全部加入集群后,查看集群状态:
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 4h46m v1.21.3
node1 Ready <none> 26m v1.21.3
node2 NotReady <none> 14s v1.21.3
# node2节点为 notready状态,查看pod信息
[root@master ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-59d64cd4d4-6ggnb 1/1 Running 0 4h26m
coredns-59d64cd4d4-cn27q 1/1 Running 0 4h26m
etcd-master 1/1 Running 0 4h27m
kube-apiserver-master 1/1 Running 0 4h27m
kube-controller-manager-master 1/1 Running 0 77m
kube-flannel-ds-68xtw 1/1 Running 0 59m
kube-flannel-ds-mlbg5 1/1 Running 0 6m52s
kube-flannel-ds-pd2tr 0/1 Init:0/1 0 5m9s
kube-proxy-52lwk 1/1 Running 0 6m52s
kube-proxy-dffm5 1/1 Running 0 4h26m
kube-proxy-f29m9 1/1 Running 0 5m9s
kube-scheduler-master 1/1 Running 0 77m
# 由上可知,某个节点的flannel一直是init状态,
解决策略
- 重启node2部分kubelet/docker,
- 删除运行容器,
- 重新加入集群,
具体参考给出的链接,可由从节点处开始操作,对主节点不必重启docker,验证可行。

更多问题
参考: