一、基本操作demo
# -*- coding: utf-8 -*
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#第一个是放在df里面的随机数据,第二个是索引,也叫行,第三个叫列
df1=pd.DataFrame(
np.random.randn(4,4),
index=list('abcd'),
columns=list('ABCD')
)
print(df1)
#也可以自己定义数据穷举
df2=pd.DataFrame(
[[1,2,3,4],[2,3,4,5],[3,4,5,6],[4,5,6,7]],
index=list('abcd'),
columns=list('ABCD')
)
print(df2)
#使用字典创建
dict1={
'name':['daysn','daysnss','min'],
'age':[1,2,3],
'sex':['boy','boy','girl']
}
df3=pd.DataFrame(dict1)
print(df3)

在上面的demo加上这个
print("-------------------df4---------------------") df4=pd.DataFrame(np.random.randn(3*2)) print("查看数据类型") print(df4.dtypes) print('head查看前n(不写参数默认为head()5)tail查看后面几列') #print(df4) #print(df4.head()) #print(df4.head(2)) #print(df4.tail()) print(df4.tail(1)) print('查看index和columns,注意不是column') print(df1.index) print(df3.columns)

二、基本行列操作
在上面的demo后面加上这个
print("-------------------df4---------------------") df4=pd.DataFrame(np.random.randn(3*2)) print("查看数据类型") print(df4.dtypes) print('head查看前n(不写参数默认为head()5)tail查看后面几列') #print(df4) #print(df4.head()) #print(df4.head(2)) #print(df4.tail()) print(df4.tail(1)) print('查看index和columns,注意不是column') print(df1.index) print(df3.columns) print('查看数据值') print(df3.values) print(df1.loc['a']) #根据索引查看 #print('或者这样') #print(df1.iloc[0]) print(df3['name']) #根据行查看 #使用shape查看行列数,参数为0表示查看行数,参数为1表示查看列数。 print('行数 ',df3.shape[0]) print('列数 ',df3.shape[1])

三、基本操作
在二中的demo续上
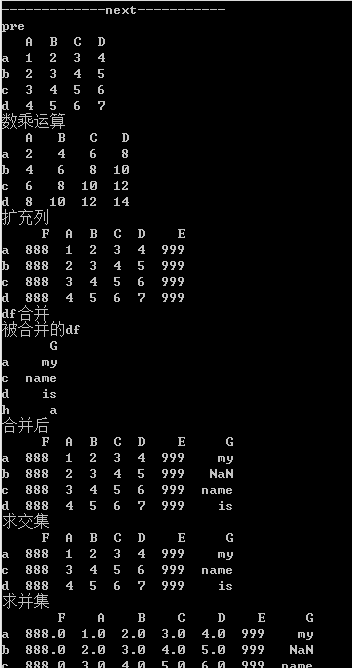
print('--------------基本操作--------------------------') print('pre----') print(df1) print('转置 --') print(df1.T) print('列描述性统计') print(df1.describe()) print('行描述性统计,其实就是做了个转置') print(df1.T.describe()) print('计算') print("列求和:",df1.sum()," 行求和: ",df1.sum(1))

四、集合操作
继续补
print('-------------next-----------')
print('pre')
print(df2)
print('数乘运算')#如果元素是字符串,则会把字符串再重复一遍
print(df2.apply(lambda x:x*2))
print('扩充列')
df2['E']=['999','999','999','999'] #不指定位置
df2.insert(0,'F',[888,888,888,888]) #指定位置,insert
print(df2)
print('df合并')
'''
使用join可以将两个DataFrame合并,但只根据行列名合并,
并且以作用的那个DataFrame的为基准。
如下所示,新的df7是以df2的行号index为基准的。
'''
df6=pd.DataFrame(
['my','name','is','a'],
index=list('acdh'),
columns=list('G')
)
print('被合并的df')
print(df6)
df7=df2.join(df6)
print('合并后')
print(df7)
#df8=df6.join(df2)
#print('合并后')
#print(df8)
print('求交集')
df9=df2.join(df6,how='inner')
print(df9)
print('求并集')
df10=df2.join(df6,how='outer')
print(df10)
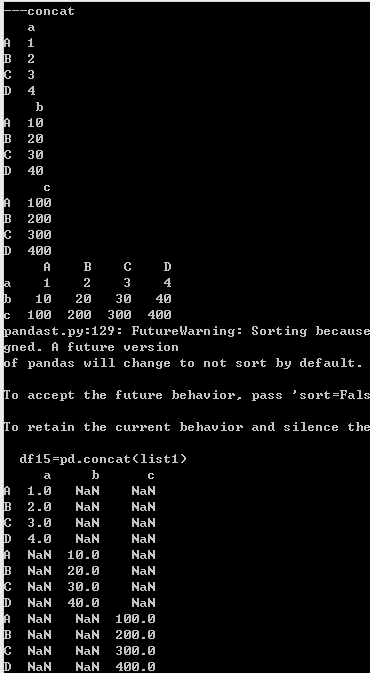
''' 如果要合并多个Dataframe,可以用list把几个Dataframe装起来, 然后使用concat转化为一个新的Dataframe。 ''' print('---concat') df11=pd.DataFrame([1,2,3,4],index=list('ABCD'),columns=['a']) print(df11) df12=pd.DataFrame([10,20,30,40],index=list('ABCD'),columns=['b']) print(df12) df13=pd.DataFrame([100,200,300,400],index=list('ABCD'),columns=['c']) print(df13) list1=[df11.T, df12.T, df13.T] df14=pd.concat(list1) print(df14)
#错误示范 list1=[df11, df12, df13] df15=pd.concat(list1) print(df15)
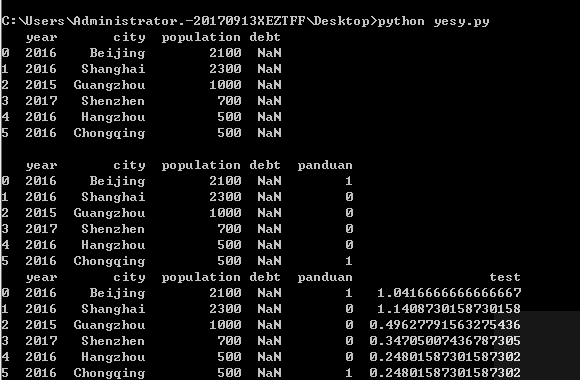
四、根据两列或者以上列生成其他列
import numpy as np import pandas as pd data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen', 'Hangzhou', 'Chongqing'], 'year': [2016,2016,2015,2017,2016, 2016], 'population': [2100, 2300, 1000, 700, 500, 500]} frame = pd.DataFrame(data, columns = ['year', 'city', 'population', 'debt']) print(frame, ' ') frame['panduan'] = frame.city.apply(lambda x: 1 if 'ing' in x else 0) print(frame) def function(a, b): #return str(int(b)) #return str(int(a)+int(b)) #return str(int(a)-int(b)) #return str(int(a)*int(b)) return str(int(a)/int(b)) frame['test'] = frame.apply(lambda x: function(x.population, x.year), axis = 1) print(frame) ''' def function(a, b): if 'ing' in a and b == 2016: return 1 else: return 0 print(frame, ' ') frame['test'] = frame.apply(lambda x: function(x.city, x.year), axis = 1) print(frame) '''
不想用lambda表达式的情况下可以这样
import numpy as np
import pandas as pd
df2=pd.DataFrame(
[[1,2,3,4],[2,3,4,5],[3,4,5,6],[4,5,6,7]],
index=list('abcd'),
columns=list('ABCD')
)
print(df2)
#1.直接来
#df2.eval('aa = A + B + C' , inplace = True)
#2.抽出str
#str = 'aa = A + B + C'
#df2.eval(str , inplace = True)
#3.抽出函数
'''
def sum(df , col_list , new_col):
string = new_col + " = "
i = 0
for col in col_list:
i += 1
string += col
if i != len(col_list):
string += "+"
df.eval(string , inplace = True)
sum(df2 , ['A','B'], 'aa')
print(df2)
'''
def avg(df , col_list , new_col):
string = new_col + " = ("
i = 0
for col in col_list:
i += 1
string += col
if i != len(col_list):
string += "+"
string += ") /" + str(len(col_list))
a = len(col_list)
print(str(a))
print(string)
df.eval(string , inplace = True)
avg(df2 , ['A','B'], 'aa')
print(df2)
附:基本操作完整demo
# -*- coding: utf-8 -* import numpy as np import pandas as pd from pandas import Series,DataFrame #第一个是放在df里面的随机数据,第二个是索引,也叫行,第三个叫列 df1=pd.DataFrame( np.random.randn(4,4), index=list('abcd'), columns=list('ABCD') ) print(df1) #也可以自己定义数据穷举 df2=pd.DataFrame( [[1,2,3,4],[2,3,4,5],[3,4,5,6],[4,5,6,7]], index=list('abcd'), columns=list('ABCD') ) print(df2) #使用字典创建 dict1={ 'name':['daysn','daysnss','min'], 'age':[1,2,3], 'sex':['boy','boy','girl'] } df3=pd.DataFrame(dict1) print(df3) print("-------------------df4---------------------") df4=pd.DataFrame(np.random.randn(3*2)) print("查看数据类型") print(df4.dtypes) print('head查看前n(不写参数默认为head()5)tail查看后面几列') #print(df4) #print(df4.head()) #print(df4.head(2)) #print(df4.tail()) print(df4.tail(1)) print('查看index和columns,注意不是column') print(df1.index) print(df3.columns) print('查看数据值') print(df3.values) print(df1.loc['a']) #根据索引查看 #print('或者这样') #print(df1.iloc[0]) print(df3['name']) #根据行查看 #使用shape查看行列数,参数为0表示查看行数,参数为1表示查看列数。 print('行数 ',df3.shape[0]) print('列数 ',df3.shape[1]) ''' DataFrame有些方法可以直接进行数据统计,矩阵计算之类的基本操作。 转置 直接字母T,线性代数上线。 比如说把之前的df2转置一下。 ''' print('--------------基本操作--------------------------') print('pre----') print(df1) print('转置 --') print(df1.T) print('列描述性统计') print(df1.describe()) print('行描述性统计,其实就是做了个转置') print(df1.T.describe()) print('计算') print("列求和:",df1.sum()," 行求和: ",df1.sum(1)) print('-------------next-----------') print('pre') print(df2) print('数乘运算')#如果元素是字符串,则会把字符串再重复一遍 print(df2.apply(lambda x:x*2)) print('扩充列') df2['E']=['999','999','999','999'] #不指定位置 df2.insert(0,'F',[888,888,888,888]) #指定位置,insert print(df2) print('df合并') ''' 使用join可以将两个DataFrame合并,但只根据行列名合并, 并且以作用的那个DataFrame的为基准。 如下所示,新的df7是以df2的行号index为基准的。 ''' df6=pd.DataFrame( ['my','name','is','a'], index=list('acdh'), columns=list('G') ) print('被合并的df') print(df6) df7=df2.join(df6) print('合并后') print(df7) #df8=df6.join(df2) #print('合并后') #print(df8) print('求交集') df9=df2.join(df6,how='inner') print(df9) print('求并集') df10=df2.join(df6,how='outer') print(df10) ''' 如果要合并多个Dataframe,可以用list把几个Dataframe装起来, 然后使用concat转化为一个新的Dataframe。 ''' print('---concat') df11=pd.DataFrame([1,2,3,4],index=list('ABCD'),columns=['a']) print(df11) df12=pd.DataFrame([10,20,30,40],index=list('ABCD'),columns=['b']) print(df12) df13=pd.DataFrame([100,200,300,400],index=list('ABCD'),columns=['c']) print(df13) list1=[df11.T, df12.T, df13.T] df14=pd.concat(list1) print(df14) list1=[df11, df12, df13] df15=pd.concat(list1) print(df15)
group by操作
# -*- coding: utf-8 -* import numpy as np import pandas as pd from pandas import Series,DataFrame import numpy as np import pandas as pd data=pd.DataFrame({'level':['a','b','c','b','a'], 'num':[3,5,6,8,9]}) print(data) ''' 原本的dataframe level num 0 a 3 1 b 5 2 c 6 3 b 8 4 a 9 ''' combine=data['num'].groupby(data['level']) #group by是先聚合,然后之后你想用什么就将combine.func()就可以了 #,比方说combine.mean() print(combine.sum())
print(combine.mean()) ''' group by以后的对象用 count mean std min 25% 50% 75% max level a 2.0 6.0 4.242641 3.0 4.50 6.0 7.50 9.0 b 2.0 6.5 2.121320 5.0 5.75 6.5 7.25 8.0 c 1.0 6.0 NaN 6.0 6.00 6.0 6.00 6.0 '''