一、案例:
1、明确需求:
在访问日志中,统计独立ip数量TOP10
2、查看数据结构:
ip:是时间戳Http Method Url.....
3、明确编码步骤:
3.1 取出ip,生成一个只有ip的数据集
3.2简单清晰
3.3统计ip出现的次数
3.4排序按照ip出现的次数
3.5取出前十
4、编写代码
4.1拷贝数据集
4.2创建代码文件
package cn.itcast.spark.rdd import org.junit.Test import org.apache.commons.lang3.StringUtils import org.apache.spark.{SparkConf, SparkContext} import scala.tools.scalap.scalax.util.StringUtil /** * @Author 带上我快跑 * @Data 2021/1/8 20:49 * @菩-萨-说-我-写-的-都-对@ */ class AccessLogAgg { @Test def ipAgg():Unit={ //1、创建sparkcontext val conf=new SparkConf().setMaster("local[6]").setAppName("ip_agg") val sc=new SparkContext(conf) //2、读入文件生成数据集 val sourceRDD=sc.textFile("dataset/access_log_sample.txt") //3、取出ip,赋予抽象次数为一 val ipRDD=sourceRDD.map(item=>(item.split(" ")(0),1)) //4、简单的清洗(去掉空数据,去掉非法的数据,根据业务在规整一下数据) val cleanRDD=ipRDD.filter(item => StringUtils.isNotEmpty(item._1)) //5、根据ip出现的次数进行聚合 val ipAggRDD=cleanRDD.reduceByKey((curr,agg)=>curr+agg) //6、根据ip出现的次数进行排序 val sortedRDD=ipAggRDD.sortBy(item=>item._2,ascending = false) //7、取出结果,打印结果 sortedRDD.take(10).foreach(item=>println(item)) //8、关闭sc sc.stop() } }
二、提出问题:
1、文件特别大的时候怎样去处理

2、如何放在集群中运行、
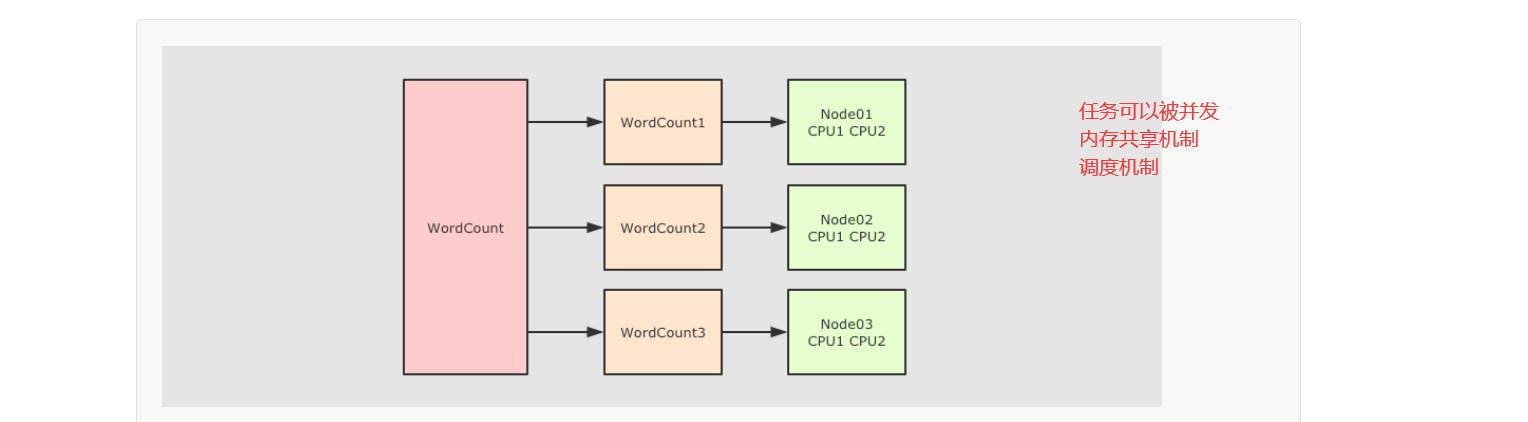
简单来讲, 并行计算就是同时使用多个计算资源解决一个问题, 有如下四个要点
-
要解决的问题必须可以分解为多个可以并发计算的部分
-
每个部分要可以在不同处理器上被同时执行
-
需要一个共享内存的机制
-
需要一个总体上的协作机制来进行调度
3、任务如何拆解
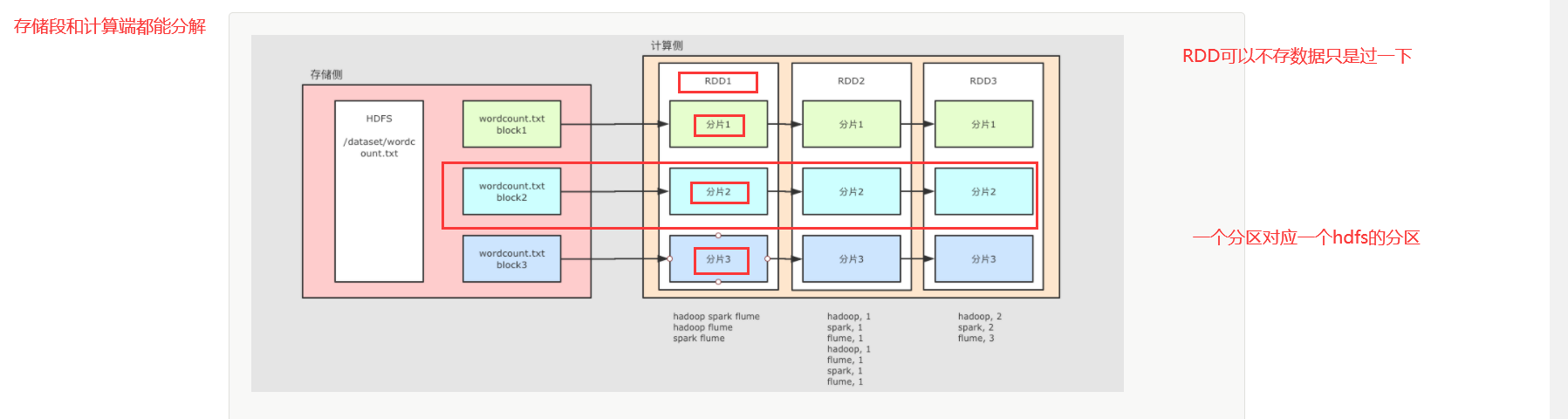
概述
-
对于 HDFS 中的文件, 是分为不同的 Block 的
-
在进行计算的时候, 就可以按照 Block 来划分, 每一个 Block 对应一个不同的计算单元
扩展
-
RDD并没有真实的存放数据, 数据是从 HDFS 中读取的, 在计算的过程中读取即可 -
RDD至少是需要可以 分片 的, 因为HDFS中的文件就是分片的,RDD分片的意义在于表示对源数据集每个分片的计算,RDD可以分片也意味着 可以并行计算
4、怎样移动计算
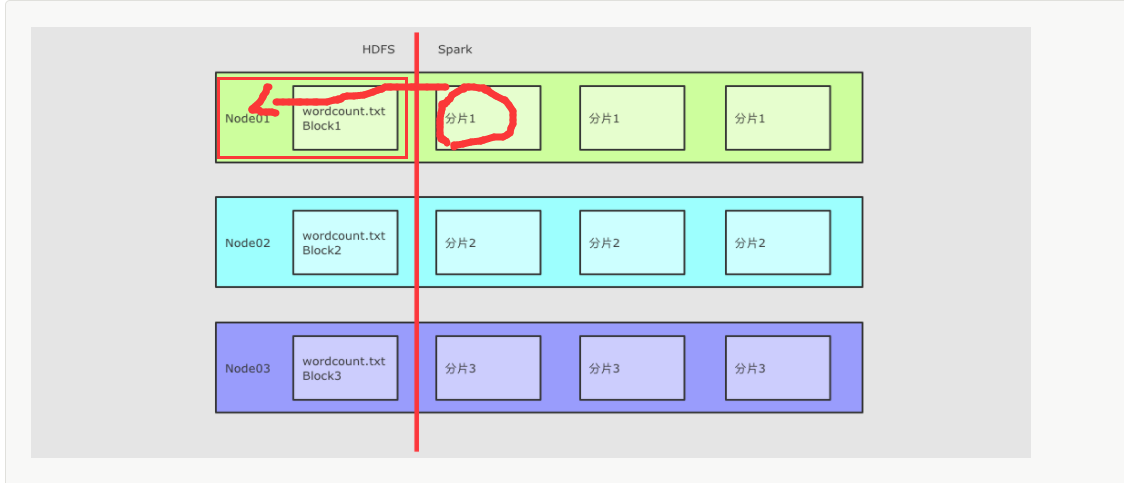
每一个计算单元需要记录其存储单元的位置, 尽量调度过去
5、如何容错

RDD1 → RDD2 → RDD3 这个过程中, RDD2 出错了, 有两种办法可以解决
-
缓存 RDD2 的数据, 直接恢复 RDD2, 类似 HDFS 的备份机制
-
记录 RDD2 的依赖关系, 通过其父级的 RDD 来恢复 RDD2, 这种方式会少很多数据的交互和保存
如何通过父级 RDD 来恢复?
-
记录 RDD2 的父亲是 RDD1
-
记录 RDD2 的计算函数, 例如记录
RDD2 = RDD1.map(…),map(…)就是计算函数 -
当 RDD2 计算出错的时候, 可以通过父级 RDD 和计算函数来恢复 RDD2
6、如果RDD之间的依赖链过长的时候怎样拆解
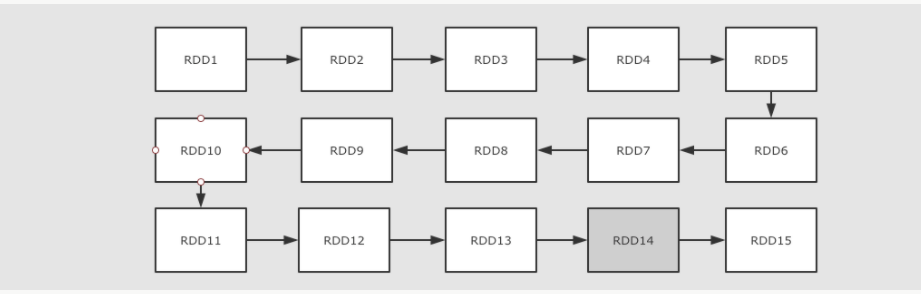
上面提到了可以使用依赖关系来进行容错, 但是如果依赖关系特别长的时候, 这种方式其实也比较低效, 这个时候就应该使用另外一种方式, 也就是记录数据集的状态
- 在 Spark 中有两个手段可以做到
-
-
缓存
-
Checkpoint
-
三、深入定义RDD
1、为神魔RDD会出现
在 RDD 出现之前, 当时 MapReduce 是比较主流的, 而 MapReduce 如何执行迭代计算的任务呢?

多个 MapReduce 任务之间没有基于内存的数据共享方式, 只能通过磁盘来进行共享
这种方式明显比较低效

在 Spark 中, 其实最终 Job3 从逻辑上的计算过程是: Job3 = (Job1.map).filter, 整个过程是共享内存的, 而不需要将中间结果存放在可靠的分布式文件系统中
这种方式可以在保证容错的前提下, 提供更多的灵活, 更快的执行速度, RDD 在执行迭代型任务时候的表现可以通过下面代码体现
2、RDD的特点


RDD 不仅是数据集, 也是编程模型
RDD 即是一种数据结构, 同时也提供了上层 API, 同时 RDD 的 API 和 Scala 中对集合运算的 API 非常类似, 同样也都是各种算子
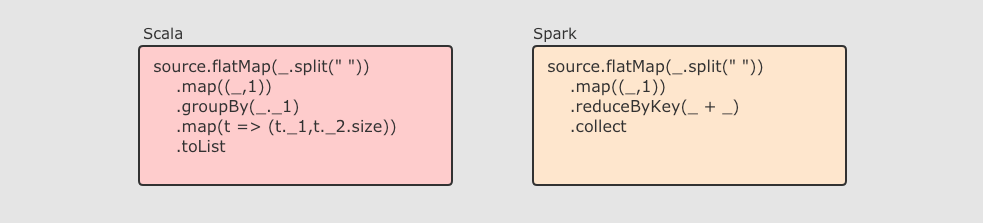
RDD 的算子大致分为两类:
-
Transformation 转换操作, 例如
mapflatMapfilter等 -
Action 动作操作, 例如
reducecollectshow等
执行 RDD 的时候, 在执行到转换操作的时候, 并不会立刻执行, 直到遇见了 Action 操作, 才会触发真正的执行, 这个特点叫做 惰性求值
RDD 可以分区
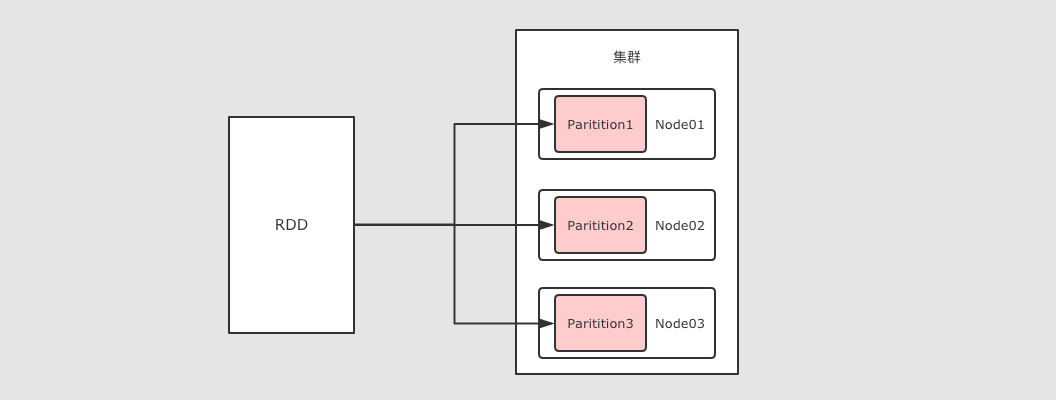
RDD 是一个分布式计算框架, 所以, 一定是要能够进行分区计算的, 只有分区了, 才能利用集群的并行计算能力
同时, RDD 不需要始终被具体化, 也就是说: RDD 中可以没有数据, 只要有足够的信息知道自己是从谁计算得来的就可以, 这是一种非常高效的容错方式
RDD 是只读的
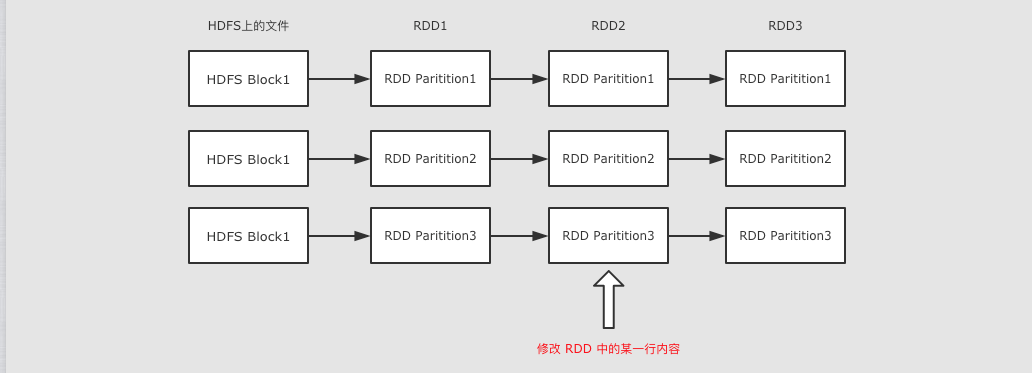
RDD 是只读的, 不允许任何形式的修改. 虽说不能因为 RDD 和 HDFS 是只读的, 就认为分布式存储系统必须设计为只读的. 但是设计为只读的, 会显著降低问题的复杂度, 因为 RDD 需要可以容错, 可以惰性求值, 可以移动计算, 所以很难支持修改.
-
RDD2 中可能没有数据, 只是保留了依赖关系和计算函数, 那修改啥?
-
如果因为支持修改, 而必须保存数据的话, 怎么容错?
-
如果允许修改, 如何定位要修改的那一行? RDD 的转换是粗粒度的, 也就是说, RDD 并不感知具体每一行在哪.
RDD 是可以容错的

- RDD 的容错有两种方式
-
-
保存 RDD 之间的依赖关系, 以及计算函数, 出现错误重新计算
-
直接将 RDD 的数据存放在外部存储系统, 出现错误直接读取, Checkpoint
-
3、神魔是弹性分布式数据集
分布式
RDD 支持分区, 可以运行在集群中
弹性
-
RDD 支持高效的容错
-
RDD 中的数据即可以缓存在内存中, 也可以缓存在磁盘中, 也可以缓存在外部存储中
数据集
-
RDD 可以不保存具体数据, 只保留创建自己的必备信息, 例如依赖和计算函数
-
RDD 也可以缓存起来, 相当于存储具体数据
四、总结RDD五大属性
首先整理一下上面所提到的 RDD 所要实现的功能:
-
RDD 有分区
-
RDD 要可以通过依赖关系和计算函数进行容错
-
RDD 要针对数据本地性进行优化
-
RDD 支持 MapReduce 形式的计算, 所以要能够对数据进行 Shuffled
对于 RDD 来说, 其中应该有什么内容呢? 如果站在 RDD 设计者的角度上, 这个类中, 至少需要什么属性?
-
Partition List分片列表, 记录 RDD 的分片, 可以在创建 RDD 的时候指定分区数目, 也可以通过算子来生成新的 RDD 从而改变分区数目 -
Compute Function为了实现容错, 需要记录 RDD 之间转换所执行的计算函数 -
RDD DependenciesRDD 之间的依赖关系, 要在 RDD 中记录其上级 RDD 是谁, 从而实现容错和计算 -
Partitioner为了执行 Shuffled 操作, 必须要有一个函数用来计算数据应该发往哪个分区 -
Preferred Location优先位置, 为了实现数据本地性操作, 从而移动计算而不是移动存储, 需要记录每个 RDD 分区最好应该放置在什么位置