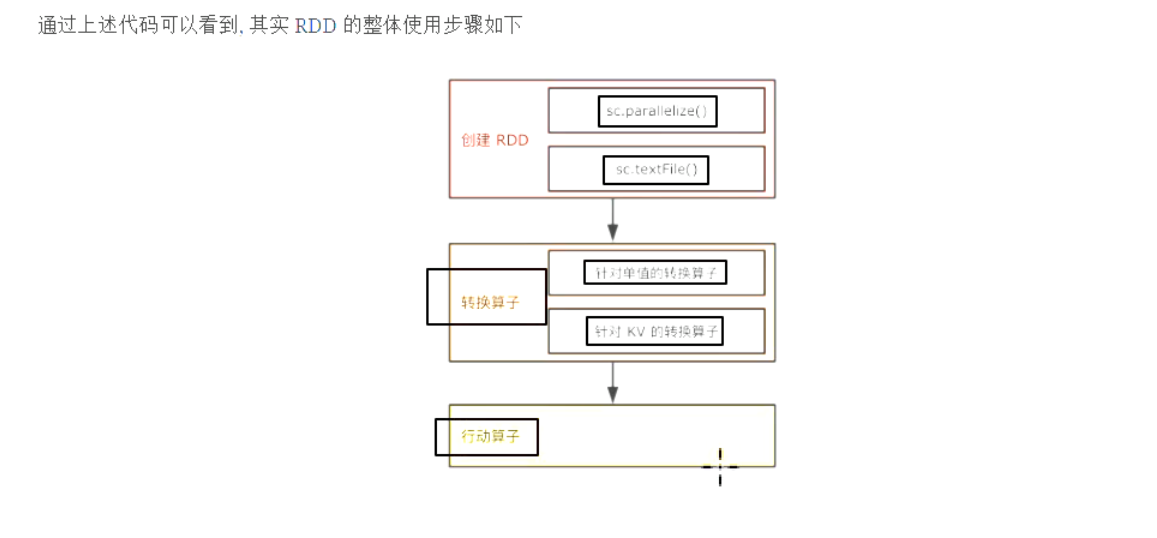
阶段练习
一、看看数据集格式
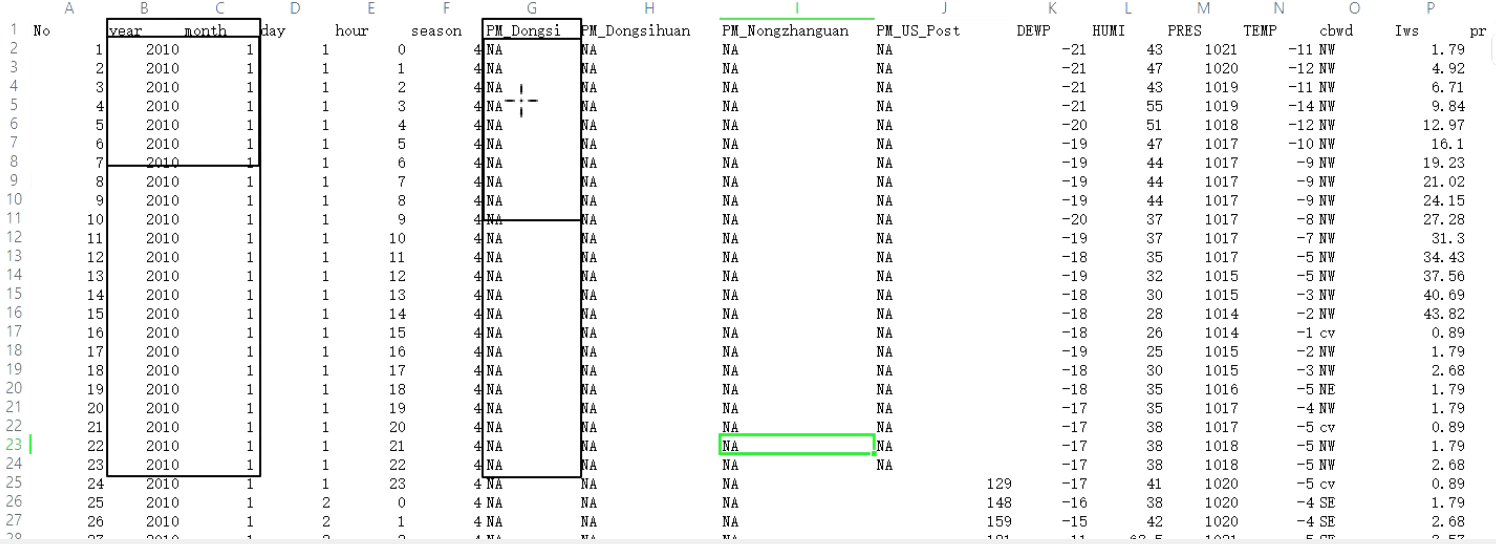
二、明确需求
三、明确步骤
1、读取文件
2、抽取需要的列
3、以年月为基础,进行reduceByKey统计东四地区的PM
4、排序
5、获取结果
四、编码
1、拷贝数据集
2、创建类
3、编写代码
4、运行测试
@Test def reduce():Unit={ //创建sc对象 val conf=new SparkConf().setMaster("local[6]").setAppName("stage_practice") val sc=new SparkContext(conf) //读取文件 val source=sc.textFile("dataset/BeijingPM20100101_20151231_noheader.csv") //通过算子处理数据 //1、抽取数据,年、月、PM(年月放一起)((年,月),Pm) source.map(item=>((item.split(",")(1),item.split(",")(2)),item.split(",")(6))) //2、清洗,过滤掉空的和NA .filter(item=>StringUtils.isNoneEmpty(item._2) && !item._2.equalsIgnoreCase("NA")) //3、聚合 .map(item=>(item._1,item._2.toInt)) .reduceByKey((curr,agg)=>curr+agg) //4、排序 .sortBy(item=>item._2,ascending = false)//为false之后就是降序显示了 //获取结果 .take(10) .foreach(item=>println(item)) //关闭测试 sc.stop() }
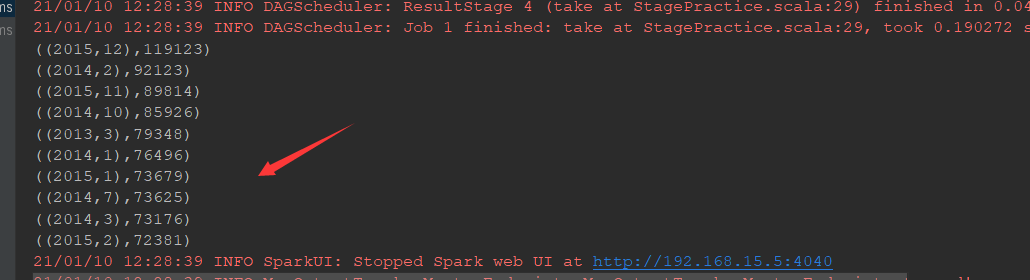
总结: