本文首发于 2016-11-21 09:43:07
架构
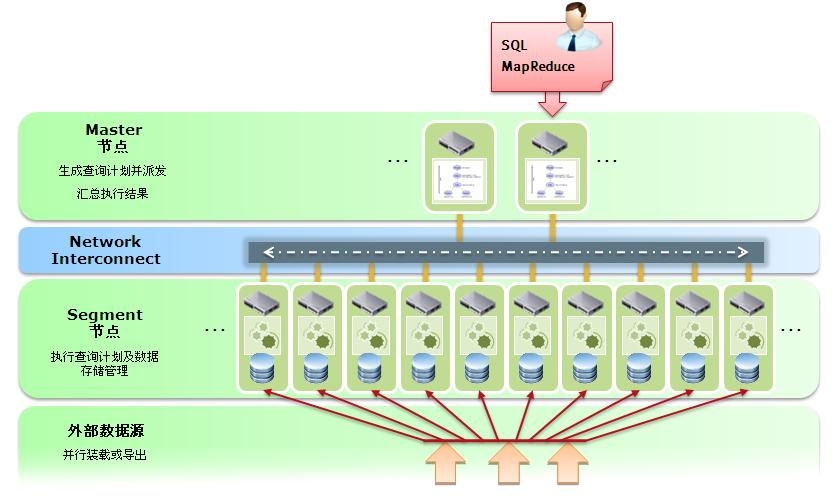
GreenPlum 采用 Share Nothing 的架构,良好的发挥了廉价PC的作用。自此I/O不在是 DW(data warehouse) 的瓶颈,相反网络的压力会大很多。但是 GreenPlum 的查询优化策略能够避免尽量少的网络交换。对于初次接触 GreenPlum 的人来说,肯定耳目一新。
查询优化器
GreenPlum 的 master 节点负责 SQL 解析和执行计划的生成,具体来说,查询优化器会将 SQL 解析成每个节点(segments)要执行的物理执行计划。
GreenPlum 采用的是基于成本的优化策略:如果有多条执行路径,会评估执行代价,找出代价最小、最有效率的一条。
不像传统的查询优化器,GreenPlum 的查询优化器必须全局的考虑整个集群,在每个候选的执行计划中考虑到节点间移动数据的开销。比如有 join,那么 join 是在各个节点分别进行的(每个节点只和自身数据做 join),所以它的查询很快。
查询计划包括了一些传统的操作,比如:扫描、Join、排序、聚合等等。
GreenPlum 中有三种数据的移动操作:
Broadcast Motion (N:N):广播数据。每个节点向其他节点广播需要发送的数据。Redistribute Motion (N:N):重新分布数据。利用 join 列数据的 hash 值不同,将筛选后的数据在其他 segment 重新分布。Gather Motion (N:1):聚合汇总数据。每个节点将 join 后的数据发到一个单节点上,通常是发到主节点 master 。
示例
示例1
explain select d.*,j.customer_id from data d join jd1 j on d.partner_id=j.partner_id where j.gmt_modified> current_date -80;
QUERY PLAN
----------------------------------------------------------------------------------------
Gather Motion 88:1 (slice2) (cost=3.01..939.49 rows=2717 width=59)
-> Hash Join (cost=3.01..939.49 rows=2717 width=59)
Hash Cond: d.partner_id::text = j.partner_id::text
-> Seq Scan on data d (cost=0.00..260.74 rows=20374 width=50)
-> Hash (cost=1.91..1.91 rows=88 width=26)
-> Broadcast Motion 88:88 (slice1) (cost=0.00..1.91 rows=88 width=26)
-> Seq Scan on jd1 j (cost=0.00..1.02 rows=1 width=26)
Filter: gmt_modified > ('now'::text::date - 80)
执行计划需要自下而上分析:
- 在各个节点扫描自己的
jd1表数据,按照条件过滤生成数据(记为rs)。 - 各节点将自己生成的
rs依次发送到其他节点。(Broadcast Motion (N:N)) - 每个节点上的
data表的数据,和各自节点上收到的rs进行 join,这样能保证本机数据只和本机数据做 join 。 - 各节点将 join 后的结果发送给 master(
Gather Motion (N:1)) 。
由上面的执行过程可以看出, GreenPlum 将 rs 给每个含有 data 表数据的节点都发了一份。
问:如果 rs 很大或者压根就没有过滤条件,会有什么问题?如何处理?
比如本例中的表 jd1 和表data的数据行数如下:
=> select count(*) from jd1;
count
-------
20
(1 row)
=> select count(*) from data;
count
--------
113367
如果 rs 很大的话,广播数据时网络就会成为瓶颈。GreenPlum 的优化器很聪明,它是将小表广播到各个 segment 上,极大的降低网络开销。从这个例子能看出统计信息对于生成好的查询计划是何等重要。
示例2
下面看一个复杂点的例子:
select
c_custkey, c_name,
sum(l_extendedprice * (1 - 1_discount)) as revenue,
c_acctbal, n_name, c_address, c_phone, c_comment
from
customer, orders, lineitem, nation
where
c_custkey = o_custkey
and 1_orderkey = o_orderkey
and o_orderdate >= date '1994-08-01'
and o_orderdate < date '1994-08-0l'
+ interval '3 month'
and l_returnflag = 'R'
and c_nationkey = n_nationkey
group by
c_custkey, c_name, c_acctbal,
c_phone, n_name, c_address, c_comment
order by
revenue desc
执行计划如下:

- 各个节点上同时扫描各自的 nation 表数据,将各 segment 上的 nation 数据向其他节点广播(
Broadcast Motion (N:N))。 - 各个节点上同时扫描各自 customer 数据,和收到的 nation 数据 join 生成
RS-CN。 - 各个 segment 同时扫描自己 orders 表数据,过滤数据生成
RS-O。 - 各个 segment 同时扫描自己 lineitem 表数据,过滤生成
RS-L。 - 各个 segment 同时将各自
RS-O和RS-L进行 join,生成RS-OL。注意此过程不需要Redistribute Motion (N:N)重新分布数据,因为 orders 和 lineitem 的 distribute column 都是orderkey,这就保证了各自需要 join 的对象都是在各自的机器上,所以 n 个节点就开始并行 join 了。 - 各个节点将自己在步骤5生成的
RS-OL按照 cust-key 在所有节点间重新分布数据(Redistribute Motion (N:N),可以按照 hash 和 range 在节点间来重新分布数据,默认是 hash),这样每个节点都会有自己的RS-OL。 - 各个节点将自己在步骤2生成的
RS-CN和自己节点上的RS-OL数据进行 join,又是本机只和本机的数据进行 join 。 - 聚合,排序,发往主节点 master 。
总结
Greenplum如何处理和优化一张大表和小表的join?
Greenplum是选择将小表广播数据,而不是将大表广播。
举例说明:
表 A 有10亿条数据(empno<pk>,deptno,ename),表 B 有500条数据(deptno<pk>,dname,loc)
表 A 与表 B join on deptno
集群有11个节点:1个 master,10个 segment
按照正常的主键列 hash 分布,每个 segment 节点上只会有 1/10 的表 A 和 1/10 的表 B。
此时 GreenPlum 会让所有节点给其他节点发送各自所拥有的小表 B 的1/10的数据,这样就保证了10个节点上,每个节点都有一份完整的表 B 的数据。此时,每个节点上1/10的 A 只需要和自己节点上的 B 进行 join 就OK。所以 GreenPlum 并行处理能力惊人的原因就在这里。
最终所有节点会将 join 的结果都发给主节点 master。
由该例可见统计信息十分重要,GreenPlum 通过统计信息来确定将哪张表进行(Broadcast Motion (N:N))。
另外,实际使用中还会出现列值倾斜的情况,比如 A 没有按照主键来 hash 分布,而是人为指定按照 deptno 的 hash 在各个节点上分布数据。若 A 中80%的数据都是sales(deptno=10)部门的,此时10个节点中,就会有一个节点上拥有了 10亿×80% 的数据,就算是将表 B 广播到其他节点 也无济于事,因为计算的压力都集中在一台机器了。所以,必须选择合适的列进行hash分布。
欢迎关注我的微信公众号【数据库内核】:分享主流开源数据库和存储引擎相关技术。

| 标题 | 网址 |
|---|---|
| GitHub | https://dbkernel.github.io |
| 知乎 | https://www.zhihu.com/people/dbkernel/posts |
| 思否(SegmentFault) | https://segmentfault.com/u/dbkernel |
| 掘金 | https://juejin.im/user/5e9d3ed251882538083fed1f/posts |
| 开源中国(oschina) | https://my.oschina.net/dbkernel |
| 博客园(cnblogs) | https://www.cnblogs.com/dbkernel |