本文首发于 2020-09-15 20:15:14
《ClickHouse和他的朋友们》系列文章转载自圈内好友 BohuTANG 的博客,原文链接:
https://bohutang.me/2020/09/13/clickhouse-and-friends-replicated-merge-tree/
以下为正文。
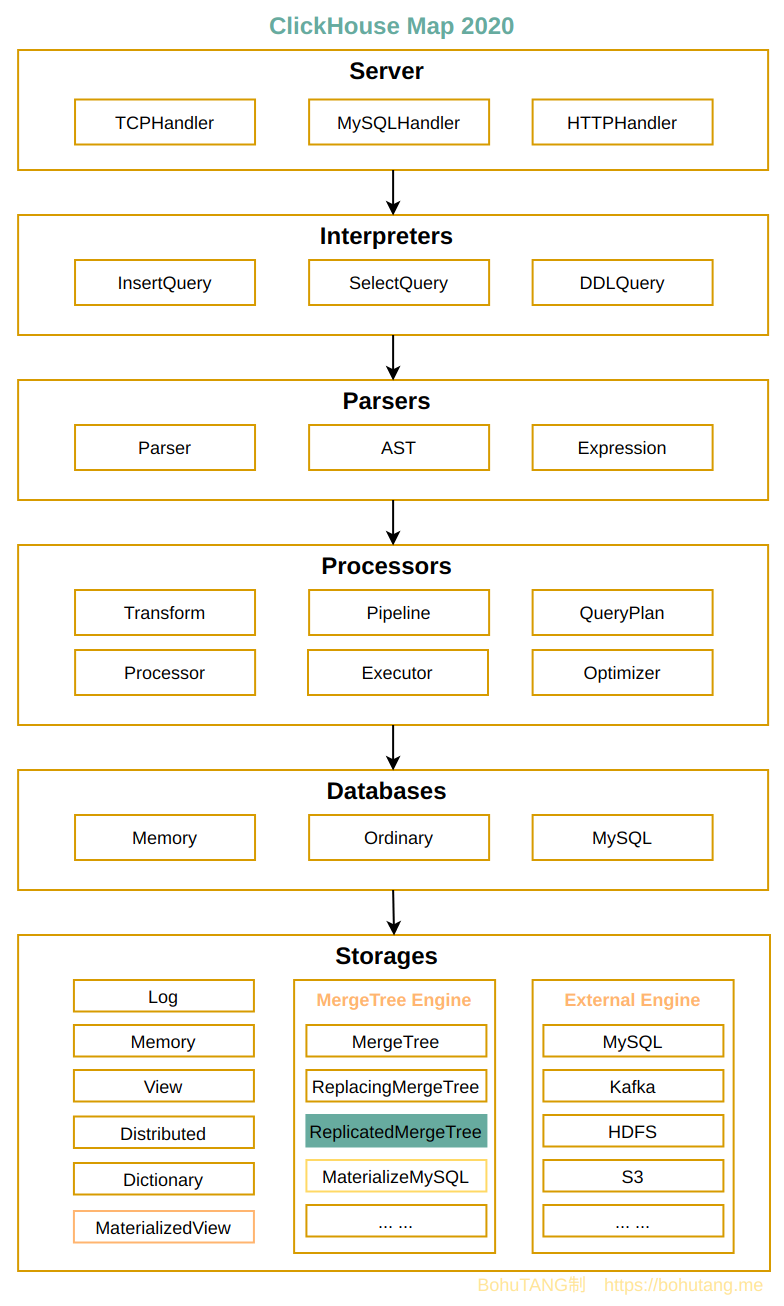
在 MySQL 里,为了保证高可用以及数据安全性会采取主从模式,数据通过 binlog 来进行同步。
在 ClickHouse 里,我们可以使用 ReplicatedMergeTree 引擎,数据同步通过 zookeeper 完成。
本文先从搭建一个多 replica 集群开始,然后一窥底层的机制,简单吃两口。
1. 集群搭建
搭建一个 2 replica 测试集群,由于条件有限,这里在同一台物理机上起 clickhouse-server(2个 replica) + zookeeper(1个),为了避免端口冲突,两个 replica 端口会有所不同。
1.1 zookeeper
docker run -p 2181:2181 --name some-zookeeper --restart always -d zookeeper
1.2 replica集群
replica-1 config.xml:
<zookeeper>
<node index="1">
<host>172.17.0.2</host>
<port>2181</port>
</node>
</zookeeper>
<remote_servers>
<mycluster_1>
<shard_1>
<internal_replication>true</internal_replication>
<replica>
<host>s1</host>
<port>9000</port>
</replica>
<replica>
<host>s2</host>
<port>9001</port>
</replica>
</shard_1>
</mycluster_1>
</remote_servers>
<macros>
<cluster>mycluster_1</cluster>
<shard>1</shard>
<replica>s1</replica>
</macros>
<tcp_port>9101</tcp_port>
<interserver_http_port>9009</interserver_http_port>
<path>/cluster/d1/datas/</path>
replica-2 config.xml:
<zookeeper>
<node index="1">
<host>172.17.0.2</host>
<port>2181</port>
</node>
</zookeeper>
<remote_servers>
<mycluster_1>
<shard_1>
<internal_replication>true</internal_replication>
<replica>
<host>s1</host>
<port>9000</port>
</replica>
<replica>
<host>s2</host>
<port>9001</port>
</replica>
</shard_1>
</mycluster_1>
</remote_servers>
<macros>
<cluster>mycluster_1</cluster>
<shard>1</shard>
<replica>s2</replica>
</macros>
<tcp_port>9102</tcp_port>
<interserver_http_port>9010</interserver_http_port>
<path>/cluster/d2/datas/</path>
1.3 创建测试表
CREATE TABLE default.rtest1 ON CLUSTER 'mycluster_1'
(
`id` Int64,
`p` Int16
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/replicated/test', '{replica}')
PARTITION BY p
ORDER BY id
1.4 查看 zookeeper
docker exec -it some-zookeeper bash
./bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 17] ls /clickhouse/tables/replicated/test/replicas
[s1, s2]
两个 replica 都已经注册到 zookeeper。
2. 同步原理
如果在 replica-1 上执行了一条写入:
replica-1> INSERT INTO rtest VALUES(33,33);
数据是如何同步到 replica-2 的呢?
s1. replica-1> StorageReplicatedMergeTree::write --> ReplicatedMergeTreeBlockOutputStream::write(const Block & block)
s2. replica-1> storage.writer.writeTempPart,写入本地磁盘
s3. replica-1> ReplicatedMergeTreeBlockOutputStream::commitPart
s4. replica-1> StorageReplicatedMergeTree::getCommitPartOp,提交LogEntry到zookeeper,信息包括:
ReplicatedMergeTreeLogEntry {
type: GET_PART,
source_replica: replica-1,
new_part_name: part->name,
new_part_type: part->getType
}
s5. replica-1> zkutil::makeCreateRequest(zookeeper_path + "/log/log-0000000022"),更新log_pointer到zookeeper
s6. replica-2> StorageReplicatedMergeTree::queueUpdatingTask(),定时pull任务
s7. replica-2> ReplicatedMergeTreeQueue::pullLogsToQueue ,拉取
s8. replica-2> zookeeper->get(replica_path + "/log_pointer") ,向zookeeper获取当前replica已经同步的位点
s9. replica-2> zookeeper->getChildrenWatch(zookeeper_path + "/log") ,向zookeeper获取所有的LogEntry信息
s10. replica-2> 根据同步位点log_pointer从所有LogEntry中筛选需要同步的LogEntry,写到queue
s11. replica-2> StorageReplicatedMergeTree::queueTask,消费queue任务
s12. replica-2> StorageReplicatedMergeTree::executeLogEntry(LogEntry & entry),根据LogEntry type执行消费
s13. replica-2> StorageReplicatedMergeTree::executeFetch(LogEntry & entry)
s14. replica-2> StorageReplicatedMergeTree::fetchPart,从replica-1的interserver_http_port下载part目录数据
s15. replica-2> MergeTreeData::renameTempPartAndReplace,把文件写入本地并更新内存meta信息
s16. replica-2> 数据同步完成
也可以进入 zookeeper docker 内部直接查看某个 LogEntry:
[zk: localhost:2181(CONNECTED) 85] get /clickhouse/tables/replicated/test/log/log-0000000022
format version: 4
create_time: 2020-09-13 16:39:05
source replica: s1
block_id: 33_2673203974107464807_7670041793554220344
get
33_2_2_0
3. 总结
本文以写入为例,从底层分析了 ClickHouse ReplicatedMergeTree 的工作原理,逻辑并不复杂。
不同 replica 的数据同步需要 zookeeper(目前社区有人在做etcd的集成 pr#10376)做元数据协调,是一个订阅/消费模型,涉及具体数据目录还需要去相应的 replica 通过 interserver_http_port 端口进行下载。
replica 的同步都是以文件目录为单位,这样就带来一个好处:我们可以轻松实现 ClickHouse 的存储计算分离,多个 clickhouse-server 可以同时挂载同一份数据进行计算,而且这些 server 每个节点都是可写,虎哥已经实现了一个可以 work 的原型,详情请参考下篇 <存储计算分离方案与实现>。
4. 参考
- [1]StorageReplicatedMergeTree.cpp
- [2]ReplicatedMergeTreeBlockOutputStream.cpp
- [3]ReplicatedMergeTreeLogEntry.cpp
- [4]ReplicatedMergeTreeQueue.cpp
欢迎关注我的微信公众号【数据库内核】:分享主流开源数据库和存储引擎相关技术。

| 标题 | 网址 |
|---|---|
| GitHub | https://dbkernel.github.io |
| 知乎 | https://www.zhihu.com/people/dbkernel/posts |
| 思否(SegmentFault) | https://segmentfault.com/u/dbkernel |
| 掘金 | https://juejin.im/user/5e9d3ed251882538083fed1f/posts |
| 开源中国(oschina) | https://my.oschina.net/dbkernel |
| 博客园(cnblogs) | https://www.cnblogs.com/dbkernel |