前释:此为结合项目中的应用场景自己想的开发方案,项目在自己本机搭建,自定义模拟数据(不是海量数据)。
1:应用背景。
全国300多城市的小区,及多方发布的房源数据的一个检索功能。
全国的房源小区数据搜索。(多条件模糊查询,经纬度查询)
2:技术实现:ELK(elasticSearch+logstash+kibana)+ filebeat + kafka
3:数据来源:
1. 原始数据
2. 其它平台的定时推送过来的房源数据
3. 平台本身用户发布的房源数据
4:数据源处理方案:
4.1. 原始数据采用sqoop处理。
实现:这里不说明如何实现,本章主要实现的是es在java中的检索应用。
4.2. 定时推送的数据定的有2种解决方案,一种是采用binlog方式,二是采用接收数据的接口在装数时候传数据到kafka一份。
本人想采用kafka方式,原因:对binlog不熟。
实现:如同4.3中的数据。
4.3. 对于本身的平台数据。
3.1:将发布房源的数据写入log的目录文件中(写入的格式及文件名称形式可自定义)。
3.2:filebeat采集日志信息写入kafka中。
3.3:logstash消费kafka中的数据并解析数据output到es中。
实现:这里不说明如何实现,本章主要实现的是es在java中的检索应用。
5:数据的检索实现。(实现之后未能及时的随笔记录,有些点可能已经忘记了)
5.1:版本及客户端使用。
我的版本使用的是6.4.2版本。
客户端有transport client和rest client,我选择的是rest方式。(在8.0版本已经弃用了transport方式)。
5.2:jar包引入。
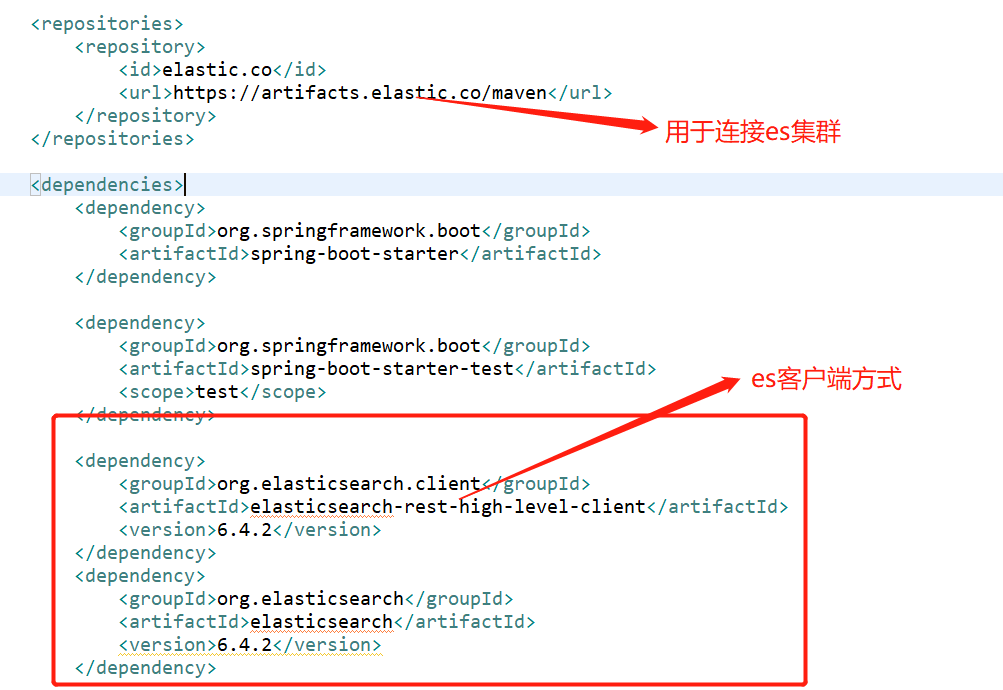
5.3:客户端的连接类。
@Configuration public class EsConfiguration { private static String hosts = "192.168.147.101,192.168.147.102,192.168.147.103"; // 集群地址,多个用,隔开 private static int port = 9200; // 使用的端口号 private static String schema = "http"; // 使用的协议 private static ArrayList<HttpHost> hostList = null; private static int connectTimeOut = 1000; // 连接超时时间 private static int socketTimeOut = 30000; // 连接超时时间 private static int connectionRequestTimeOut = 500; // 获取连接的超时时间 private static int maxConnectNum = 100; // 最大连接数 private static int maxConnectPerRoute = 100; // 最大路由连接数 static { hostList = new ArrayList<>(); String[] hostStrs = hosts.split(","); for (String host : hostStrs) { hostList.add(new HttpHost(host, port, schema)); } } @Bean public RestHighLevelClient client() { RestClientBuilder builder = RestClient.builder(hostList.toArray(new HttpHost[0])); // 异步httpclient连接延时配置 builder.setRequestConfigCallback(new RequestConfigCallback() { @Override public Builder customizeRequestConfig(Builder requestConfigBuilder) { requestConfigBuilder.setConnectTimeout(connectTimeOut); requestConfigBuilder.setSocketTimeout(socketTimeOut); requestConfigBuilder.setConnectionRequestTimeout(connectionRequestTimeOut); return requestConfigBuilder; } }); // 异步httpclient连接数配置 builder.setHttpClientConfigCallback(new HttpClientConfigCallback() { @Override public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpClientBuilder) { httpClientBuilder.setMaxConnTotal(maxConnectNum); httpClientBuilder.setMaxConnPerRoute(maxConnectPerRoute); return httpClientBuilder; } }); RestHighLevelClient client = new RestHighLevelClient(builder); return client; } }
5.4:实体类。


5.5:重点,整合java使用的测试类。在搜索的方法中有测试场景时候的情况的注释。
@RunWith(SpringRunner.class) @SpringBootTest(classes = { Demo01Application.class }) public class Demo01ApplicationTests { @Autowired private RestHighLevelClient client; public static String INDEX_TEST = null; public static String TYPE_TEST = null; public static Tests tests = null; public static List<Tests> testsList = null; @Test public void contextLoads() throws IOException, CloneNotSupportedException { // // 判断是否存在索引 // existsIndex("indexName"); // // 创建索引 // createIndex("house", "house-info"); // // 删除索引 // deleteIndex("house"); // // 判断数据是否存在 // exists("user", "user-info", "JO3hP24BlvWqEof7y5BF"); // // 根据ID获取数据 // get("index01", "type", "201"); // // List<String> idList = null; // List<Map<String, Object>> dataList = null; // // //批量更新 // bulkUpdate("index_name", "index_type", idList, dataList); // // 批量添加 // bulkAdd("index_name", "index_type", idList, dataList); // // 批量删除 // List<Map<String, Object>> dataList = null; // List<String> idList = new ArrayList<String>(); // idList.add("ZsSfRW4B3jWdK-k5x4lo"); // idList.add("ZcSZRW4B3jWdK-k5E4ld"); // bulkDelete("user", "user-info", idList, dataList); // // //坐标范围查询 // searchPoint(); // //关键字查询 // search("蒋", "user-info", "user"); client.close(); } /** * 创建索引 * * @param index_name * @param index_type * @throws IOException */ private void createIndex(String index_name, String index_type) throws IOException { CreateIndexRequest request = new CreateIndexRequest(index_name);// 创建索引 // 创建的每个索引都可以有与之关联的特定设置===================设置主片与副本数====================== //主片的个数(默认5个)确定是不会变的,副本数(默认1个)是可以改变的 request.settings(Settings.builder().put("index.number_of_shards", 3).put("index.number_of_replicas", 1)); XContentBuilder xContentBuilder = XContentFactory.jsonBuilder(); xContentBuilder.startObject() // 索引库名(类似数据库中的表),可以指定字段的类型,String中text是分词的,keyword不分词 .startObject(index_type).startObject("properties") .startObject("doc.haCode").field("type", "keyword").endObject() .startObject("doc.haStatus").field("type", "integer").field("index", false).endObject() .startObject("doc.haName").field("type", "text").endObject() .startObject("doc.haAddr").field("type", "text").endObject() .startObject("doc.haPrice").field("type", "float").field("index", false).endObject() .startObject("doc.location").field("type", "geo_point").endObject() //不参与索引创建 .startObject("doc.haImage").field("type", "text").field("index", false).endObject() .startObject("doc.haDate").field("type", "date").endObject() .endObject().endObject().endObject(); // 创建索引时创建文档类型映射==========================定义mapping,指定字段类型,如一些特殊字段========================= request.mapping(index_type, xContentBuilder); // 异步执行 // 异步执行创建索引请求需要将CreateIndexRequest实例和ActionListener实例传递给异步方法: // CreateIndexResponse的典型监听器如下所示: // 异步方法不会阻塞并立即返回。 ActionListener<CreateIndexResponse> listener = new ActionListener<CreateIndexResponse>() { @Override public void onResponse(CreateIndexResponse createIndexResponse) { // 如果执行成功,则调用onResponse方法; } @Override public void onFailure(Exception e) { // 如果失败,则调用onFailure方法。 } }; CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT); System.out.println("createIndex: " + JSON.toJSONString(createIndexResponse)); xContentBuilder.close(); // client.indices().createAsync(request, RequestOptions.DEFAULT, // listener);//要执行的CreateIndexRequest和执行完成时要使用的ActionListener } /** * 判断索引是否存在 * * @param index_name * @return * @throws IOException */ public boolean existsIndex(String index_name) throws IOException { GetIndexRequest request = new GetIndexRequest(); request.indices(index_name); boolean exists = client.indices().exists(request, RequestOptions.DEFAULT); System.out.println("existsIndex: " + exists); return exists; } /** * 删除索引 * * @param index * @return * @throws IOException */ public void deleteIndex(String index_name) throws IOException { DeleteIndexRequest request = new DeleteIndexRequest(index_name); DeleteIndexResponse deleteIndexResponse = client.indices().delete(request, RequestOptions.DEFAULT); System.out.println("deleteIndex: " + JSON.toJSONString(deleteIndexResponse)); } /** * 判断记录是否存在 * * @param index * @param type * @param tests * @return * @throws IOException */ public boolean exists(String index_name, String index_type, String index_id) throws IOException { GetRequest getRequest = new GetRequest(index_name, index_type, index_id); getRequest.fetchSourceContext(new FetchSourceContext(false)); getRequest.storedFields("_none_"); boolean exists = client.exists(getRequest, RequestOptions.DEFAULT); System.out.println("exists: " + exists); return exists; } /** * 根据ID获取记录信息 * * @param index * @param type * @param id * @throws IOException */ public void get(String index_name, String index_type, String index_id) throws IOException { GetRequest getRequest = new GetRequest(index_name, index_type, index_id); GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT); System.out.println("get: " + JSON.toJSONString(getResponse)); } /** * 批量增加 addTestList方法封装list数据 * * @throws IOException */ private void bulkAdd(String index_name, String index_type, List<String> idList, List<Map<String, Object>> dataList) throws IOException { BulkRequest bulkAddRequest = new BulkRequest(); for (int i = 0; i < dataList.size(); i++) { IndexRequest indexRequest = new IndexRequest(index_name, index_type, idList.get(i)); indexRequest.source(JSON.toJSONString(dataList.get(i)), XContentType.JSON); bulkAddRequest.add(indexRequest); } BulkResponse bulkAddResponse = client.bulk(bulkAddRequest, RequestOptions.DEFAULT); System.out.println("bulkAddResponse: " + JSON.toJSONString(bulkAddResponse)); } /** * 批量更新 * * @param index * @param type * @param tests * @throws IOException */ public void bulkUpdate(String index_name, String index_type, List<String> idList, List<Map<String, Object>> dataList) throws IOException { BulkRequest bulkUpdateRequest = new BulkRequest(); for (int i = 0; i < dataList.size(); i++) { UpdateRequest updateRequest = new UpdateRequest(index_name, index_type, idList.get(i)); updateRequest.doc(JSON.toJSONString(dataList.get(i)), XContentType.JSON); bulkUpdateRequest.add(updateRequest); } BulkResponse bulkUpdateResponse = client.bulk(bulkUpdateRequest, RequestOptions.DEFAULT); System.out.println("bulkUpdate: " + JSON.toJSONString(bulkUpdateResponse)); } /** * 删除记录 * * @param index * @param type * @param id * @throws IOException */ public void bulkDelete(String index_name, String index_type, List<String> idList, List<Map<String, Object>> dataList) throws IOException { BulkRequest bulkDeleteRequest = new BulkRequest(); for (int i = 0; i < idList.size(); i++) { DeleteRequest deleteRequest = new DeleteRequest(index_name, index_type, idList.get(i)); bulkDeleteRequest.add(deleteRequest); } BulkResponse bulkDeleteResponse = client.bulk(bulkDeleteRequest, RequestOptions.DEFAULT); System.out.println("bulkDelete: " + JSON.toJSONString(bulkDeleteResponse)); } /** * 搜索 * * @param index 要搜索的索引库 * @param type 要搜索的索引库类型 * @param name 要搜索的关键字 * @throws IOException */ public void search(String name, String type, String index) throws IOException { //query查询: //match查询:知道分词器存在,会对查询的关键字分词; //team一个关键词/teams多个关键词查询:不知道分词器,不会对查询的关键字分词; 较精确的查询 //例子:条件是‘我你’ team查询的是含有‘我你’的,match查询含有‘我你’‘我’‘你’的都能查询出 //QueryBuilders.matchQuery("name", name) //filter查询:不计算相关性,且有cache,速度比query查询快 // boolBuilder多条件查询:must相当于and, should相当于or,mustnot不符合条件的 //聚合查询 // sum min max avg cardinality基数(类似去重之后的数量) teams分组 // matchQuery(提高召回率,关键字会被分词), // matchPhraseQuery(关键字不会分词), match_phrase提高精准度 // matchQuery单一查询QueryBuilders.matchQuery("name", name), // multiMatchQuery匹配多列查询QueryBuilders.multiMatchQuery("music","name","interest"), // wildcardQuery模糊匹配查询QueryBuilders.wildcardQuery("name", "*jack*") *多个 ?一个 // QueryBuilders.matchPhraseQuery("字段名字", "前缀");//前缀查询 // QueryBuilders.fuzzyQuery("字段名字", "关键字"); //模糊查询,跟关键字类似的都可以查询出来 --> 关键字:tet 有可能会搜寻出 test text等 // rangeQuery区间查询 // geoDistanceQuery经纬度范围商家 // 排序:ScoreSortBuilder,FieldSortBuilder //关键字查询 BoolQueryBuilder boolBuilder = QueryBuilders.boolQuery(); // boolBuilder.must(QueryBuilders.matchQuery("name", name)); // // 这里可以根据字段进行搜索,must表示符合条件的,相反的mustnot表示不符合条件的 // boolBuilder.must(QueryBuilders.matchQuery("sex", name)); // boolBuilder.must(QueryBuilders.matchQuery("id", tests.getId().toString())); // boolQueryBuilder.must(QueryBuilders.termQuery("field","value")); // boolQueryBuilder.must(QueryBuilders.wildcardQuery("field","value")); // boolQueryBuilder.must(QueryBuilders.rangeQuery("field").gt("value")); // boolQueryBuilder.must(QueryBuilders.termsQuery("field","value")); // boolBuilder.should(boolBuilder.filter(QueryBuilders.matchPhraseQuery("name", name))); // boolBuilder.should(boolBuilder.filter(QueryBuilders.matchPhraseQuery("sex", name))); // boolBuilder.should(QueryBuilders.matchPhraseQuery("sex", name)); boolBuilder.should(QueryBuilders.matchPhraseQuery("doc.username", name)); // RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("id"); // //区间查询,都是闭区间 // rangeQueryBuilder.gte(1); // rangeQueryBuilder.lte(1); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.query(boolBuilder); // sourceBuilder.query(rangeQueryBuilder); sourceBuilder.from(0); sourceBuilder.size(100); // 获取记录数,默认10 // sourceBuilder.sort("id", SortOrder.ASC); // sourceBuilder.fetchSource(new String[] { "id", "name", "sex", "age" }, new String[] {}); // 第一个是获取字段,第二个是过滤的字段,默认获取全部 sourceBuilder.fetchSource(new String[] { "doc.username", "doc.password"}, new String[] {}); // 第一个是获取字段,第二个是过滤的字段,默认获取全部 SearchRequest searchRequest = new SearchRequest(index); searchRequest.types(type); searchRequest.source(sourceBuilder); SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT); System.out.println("search: " + JSON.toJSONString(response)); SearchHits hits = response.getHits(); SearchHit[] searchHits = hits.getHits(); for (SearchHit hit : searchHits) { System.out.println("search -> " + hit.getSourceAsString()); System.out.println("search -> " + hit.getSourceAsMap().get("doc")); UserEntity parseObject = JSONObject.parseObject(JSONObject.toJSONString(hit.getSourceAsMap().get("doc")), UserEntity.class); System.out.println("search -> " + parseObject.getUsername()); } } /** * 范围查询,左右都是闭集 * * @param fieldKey * @param start * @param end * @return */ public RangeQueryBuilder rangeMathQuery(String fieldKey, String start, String end) { RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery(fieldKey); rangeQueryBuilder.gte(start); rangeQueryBuilder.lte(end); return rangeQueryBuilder; } //坐标查询 范围查询 public void searchPoint() throws IOException { double a = 40.215193; double b = 116.680852; GeoDistanceQueryBuilder builder = QueryBuilders.geoDistanceQuery("location"); builder.point(a, b); builder.distance(1000, DistanceUnit.MILES); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.query(builder); GeoDistanceSortBuilder sort = SortBuilders.geoDistanceSort("location", a, b).order(SortOrder.ASC) .unit(DistanceUnit.KILOMETERS); sourceBuilder.sort("id", SortOrder.ASC); SearchRequest searchRequest = new SearchRequest("index1"); searchRequest.types("type1"); searchRequest.source(sourceBuilder); SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT); SearchHits hits = response.getHits(); SearchHit[] searchHits = hits.getHits(); for (SearchHit hit : searchHits) { System.out.println("search -> " + hit.getSourceAsString()); } } /** * 创建新增数据 * * @throws IOException */ public void addTestList() throws IOException { double lat = 38.929986; double lon = 113.395645; for (long i = 201; i < 202; i++) { double max = 0.00001; double min = 0.000001; Random random = new Random(); double s = random.nextDouble() % (max - min + 1) + max; DecimalFormat df = new DecimalFormat("######0.000000"); // System.out.println(s); String lons = df.format(s + lon); String lats = df.format(s + lat); Double dlon = Double.valueOf(lons); Double dlat = Double.valueOf(lats); Tests tests = new Tests(); tests.setId(i); tests.setName("名字啊" + i); tests.setSex("电话啊" + i); GeoPoint location = new GeoPoint(); location.setLat(dlat); location.setLon(dlon); tests.setLocation(location); testsList.add(tests); } } }
6:注意的点
6.1:当时有想到可不可以关联查询?
首先不建议关联查询,尽量一个表表述完整。原因关联查询会慢几倍-几百倍,失去了快速查询的意义。
这个是关联查询的方法:https://blog.csdn.net/tuposky/article/details/80988915
这个是验证关联会慢的 :http://www.matools.com/blog/190652134
6.2:如果说有海量的数据,且数据的字段很多怎么处理?
目前我能想到的就是将海量数据存入hbase中,在es中存入要检索的关键信息。能力一般水平有限,还希望各路大神指点。
6.3:es的数据存储字段定义的问题?
es的数据是存储在 "_source" 下面的,es本身会有很多属性,所以如果字段中有type,host,path等值,那么数据插入不进去。
解决办法:logstash中的output配置target => "doc" 将数据放在 _source下的doc中,数据就是doc.xxx
但是由于有经纬度数据,经纬度类型数据无法报存到上述方法的doc中,未找到原因,所以字段就尽量避开type,host,path等值就好了。