一、交叉验证(Cross Validation)
1. 目的
交叉验证的目的是为了让模型评估更加准确可信。
2. 基本思想
基本思想是将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型,以此来作为评价分类器的性能指标。
3. 主要方法
交叉验证主要有以下三种方法:
- Holdout验证
- K折交叉验证
- 留一验证
3.1 Holdout验证
将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型。
3.2 K折交叉验证(K-fold Cross Validation)
以10折交叉验证为例,如下图所示。
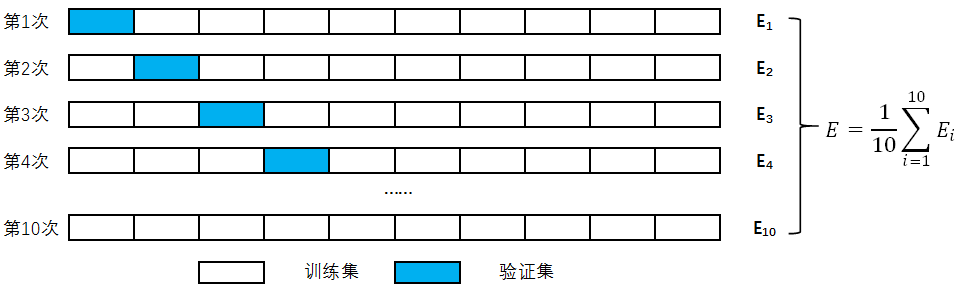
步骤如下:
- 将数据集平均分成不相交的10个子集
- 每一次挑选其中的1份作为测试集,其余的9份作为训练集进行模型训练,得到模型的指标
- 重复第2步10次,使每个子集都作为1次测试集,得到10个模型的指标
- 将10个模型指标取平均值,作为10折交叉验证的模型的指标
3.3 留一验证(Leave-One-Out Cross Validation,LOOCV)
留一验证是K折交叉验证的特例,假设原始数据有N个样本,每个样本单独作为验证集,其余的N-1个样本作为训练集。此方法主要用于样本量非常少的情况。
二、网格搜索(Grid Search)
通常情况下,很多超参数需要调节,但是手动过程繁杂,所以需要对模型预设几种超参数组合,每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。
sklearn中网格搜索API
sklearn.model_selection.GridSearchCV(estimator,param_grid,cv)
estimator:估计器对象
param_grid:估计器参数,参数名称(字符串)作为key,要测试的参数列表作为value的字典,或这样的字典构成的列表
cv:整形,指定K折交叉验证
方法:
fit:输入训练数据
score:准确率
best_score_:交叉验证中测试的最好的结果
best_estimator_:交叉验证中测试的最好的参数模型
best_params_:交叉验证中测试的最好的参数
cv_results_:每次交叉验证的结果
简单示例如下:
knn = KNeighborsClassifier()
param = {"n_neighbors": [3,5,10]}
gscv = GridSearchCV(knn, param_grid=param, cv=10)
gscv.fit(x_train, y_train)
print(gscv.score(x_test, y_test))
print(gscv.best_score_)
print(gscv.best_estimator_)
print(gscv.best_params_)
print(pd.DataFrame(gscv.cv_results_).T)
到不了的地方都叫做远方,回不去的世界都叫做家乡,我一直向往的却是比远更远的地方。——《幽灵公主》